This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Don’t Forget to join our 40k+ ML SubReddit The post The “Zero-Shot” Mirage: How DataScarcity Limits Multimodal AI appeared first on MarkTechPost. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
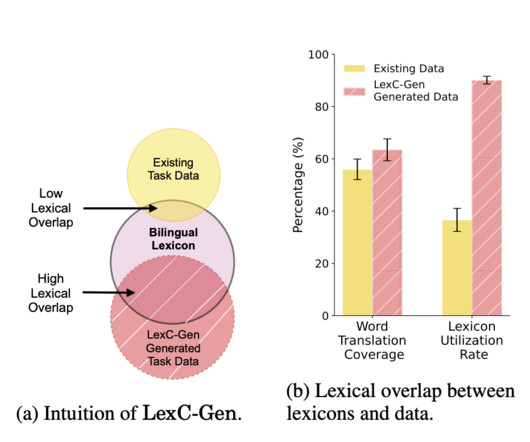
Datascarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. Check out the Paper. All credit for this research goes to the researchers of this project.
DataScarcity: Pre-training on small datasets (e.g., Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit. While newer models like GTE and CDE improved fine-tuning strategies for tasks like retrieval, they rely on outdated backbone architectures inherited from BERT.
The rapid advancement of ArtificialIntelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. OAK dataset offers a comprehensive resource for AI research, derived from Wikipedia’s main categories.
In the rapidly evolving landscape of artificialintelligence (AI), the quest for large, diverse, and high-quality datasets represents a significant hurdle. Don’t Forget to join our 40k+ ML SubReddit Want to get in front of 1.5 Also, don’t forget to follow us on Twitter. If you like our work, you will love our newsletter.
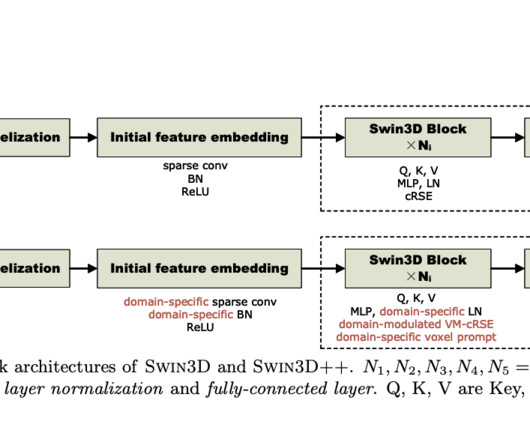
However, the scarcity and limited annotation of 3D data present significant challenges for the development and impact of 3D pretraining. One straightforward solution to address the datascarcity issue is to merge multiple existing 3D datasets and employ the combined data for universal 3D backbone pretraining.
Together, these techniques mitigate the issues of limited target data, improving the model’s adaptability and accuracy. A recent paper published by a Chinese research team proposes a novel approach to combat datascarcity in classification tasks within target domains. Check out the Paper.
With new releases and introductions in the field of ArtificialIntelligence (AI), Large Language Models (LLMs) are advancing significantly. Other effective strategies to address datascarcity include vocabulary extension and ongoing pretraining. Check out the Paper and Model. Also, don’t forget to follow us on Twitter.
With the significant advancement in the fields of ArtificialIntelligence (AI) and Natural Language Processing (NLP), Large Language Models (LLMs) like GPT have gained attention for producing fluent text without explicitly built grammar or semantic modules. Also, don’t forget to follow us on Twitter.
However, judgmental forecasting has introduced a nuanced approach, leveraging human intuition, domain knowledge, and diverse information sources to predict future events under datascarcity and uncertainty. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Check out the Paper.
The number of AI and, in particular, machine learning (ML) publications related to medical imaging has increased dramatically in recent years. A current PubMed search using the Mesh keywords “artificialintelligence” and “radiology” yielded 5,369 papers in 2021, more than five times the results found in 2011.
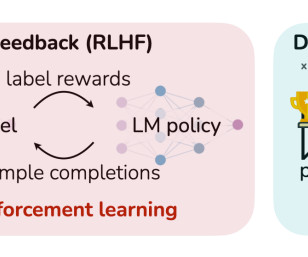
A major issue in RL is the datascarcity in embodied AI, where agents must interact with physical environments. This problem is exacerbated by the need for substantial reward-labeled data to train agents effectively. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
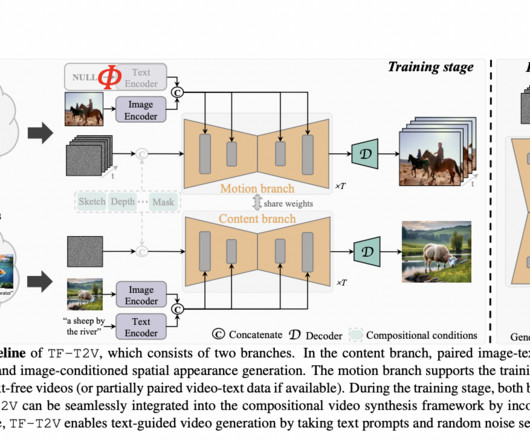
A fascinating field of study in artificialintelligence and computer vision is the creation of videos based on written descriptions. link] To conclude, the TF-T2V framework offers several key advantages: It innovatively utilizes text-free videos, addressing the datascarcity issue prevalent in the field.
In the rapidly evolving landscape of artificialintelligence, the quality and quantity of data play a pivotal role in determining the success of machine learning models. While real-world data provides a rich foundation for training, it often faces limitations such as scarcity, bias, and privacy concerns.
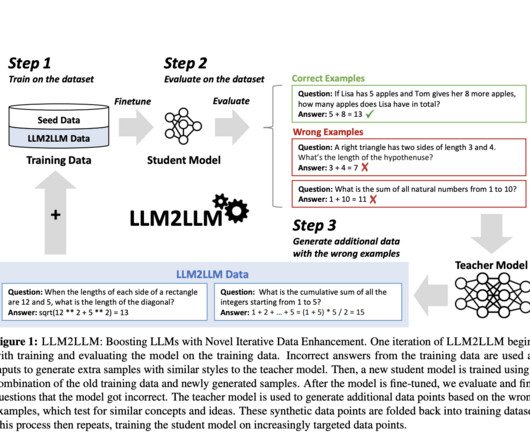
In conclusion, the LLM2LLM framework offers a robust solution to the critical challenge of datascarcity. By harnessing the power of one LLM to improve another, it demonstrates a novel, efficient pathway to fine-tune models for specific tasks with limited initial data. Similarly, on the CaseHOLD dataset, there was a 32.6%
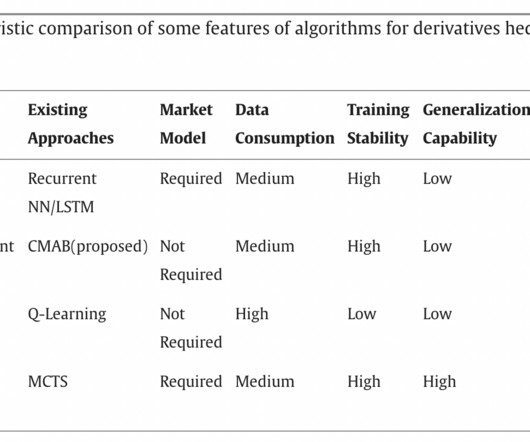
Artificialintelligence is used in all spheres of life, providing utility in all fields. He highlighted the necessity for effective data use by stressing the significant amount of data many AI systems consume. However, due to high transaction costs and other limitations, continuous trading may not be feasible.
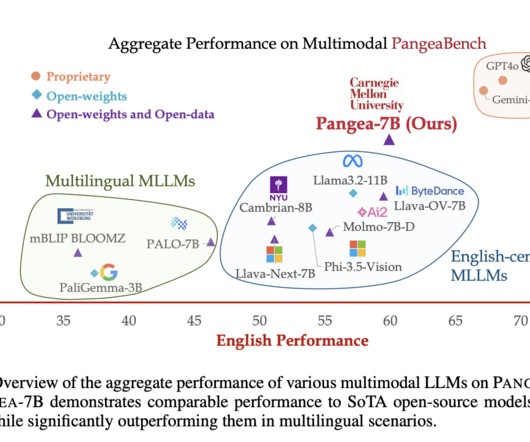
The dataset was designed to address the major challenges of multilingual multimodal learning: datascarcity, cultural nuances, catastrophic forgetting, and evaluation complexity. Don’t Forget to join our 50k+ ML SubReddit. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro
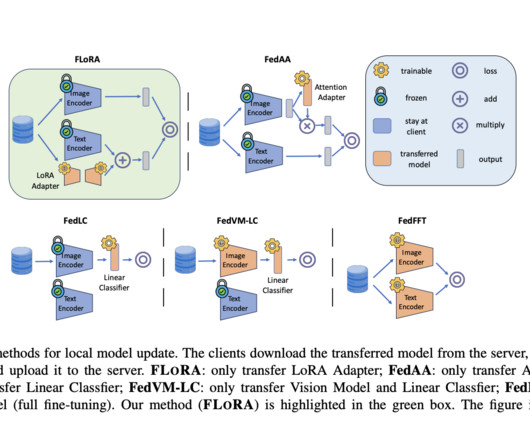
A few-shot evaluation further confirms FLORA’s proficiency in managing datascarcity and distribution variability, showcasing its robust performance even with limited training examples. In conclusion, FLORA presents a promising solution to the challenge of training vision-language models in federated learning settings.
Integrating artificialintelligence (AI) in healthcare transforms medical practices by improving diagnostics and treatment planning accuracy and efficiency. Unlike conventional methods, this approach utilizes Bayesian inference and Monte Carlo techniques to effectively manage uncertainty and datascarcity.
Modern bioprocess development, driven by advanced analytical techniques, digitalization, and automation, generates extensive experimental data valuable for process optimization—ML methods to analyze these large datasets, enabling efficient exploration of design spaces in bioprocessing.
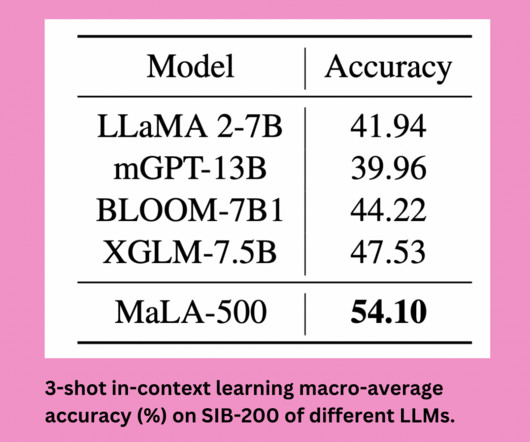
However, there’s potential to significantly improve models for smaller languages through multilingual training, which could mitigate the datascarcity issue. Also, don’t forget to follow us on Twitter. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
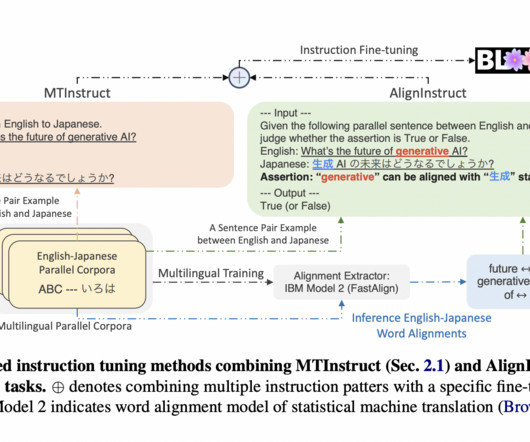
Developed by researchers from Apple, aiming to enhance machine translation, AlignInstruct represents a paradigm shift in tackling datascarcity. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Check out the Paper. Also, don’t forget to follow us on Twitter.
Also, don’t forget to join our 27k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more.
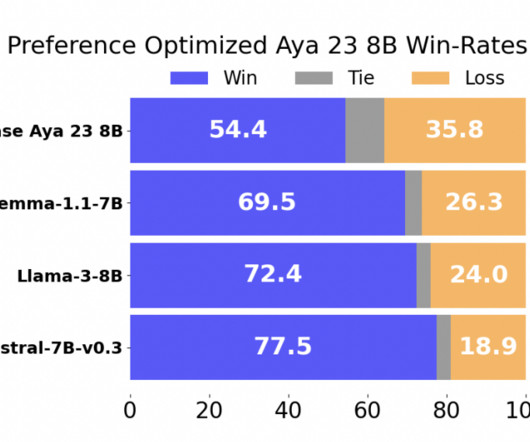
In conclusion, the research conducted by Cohere For AI demonstrates the critical importance of high-quality, diverse, multilingual data in training effective multilingual language models. Also, don’t forget to follow us on Twitter. Join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
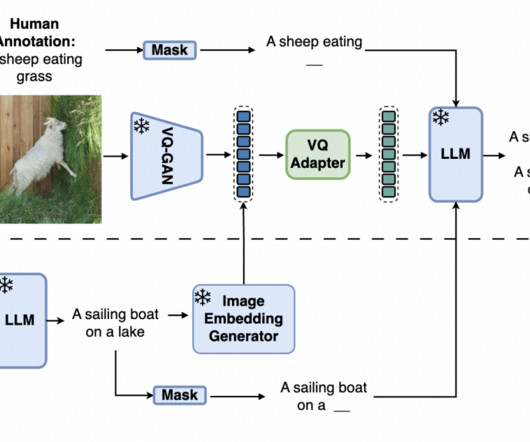
This method leverages pre-trained generative text and image models to create synthetic paired data for VLMs, addressing datascarcity, cost, and noise challenges. It generates both text and images synthetically, avoiding reliance on real-world data. The researchers from Google DeepMind have proposed Synth2.
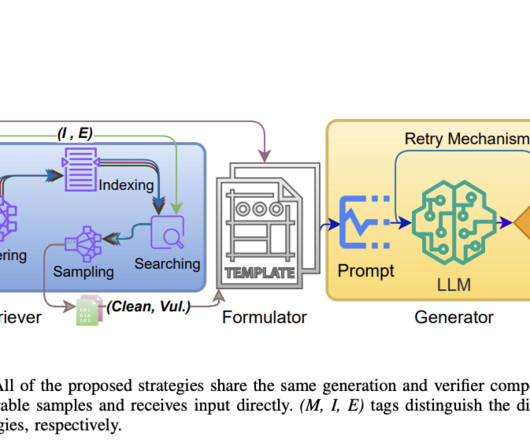
The success of VulScribeR highlights the importance of large-scale data augmentation in the field of vulnerability detection. By generating diverse and realistic vulnerable code samples, this approach provides a practical solution to the datascarcity problem that has long hindered the development of effective DLVD models.
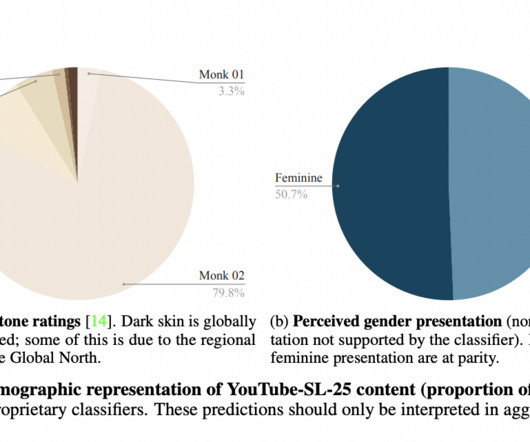
In conclusion, YouTube-SL-25 is a pivotal advancement in sign language research, addressing the longstanding datascarcity issue. The dataset’s open-domain nature allows for broad applications, from general sign language pretraining to medium-quality finetuning for specific tasks such as translation and caption alignment.
Human-sensing applications such as activity recognition, fall detection, and health monitoring have been revolutionized by advancements in artificialintelligence (AI) and machine learning technologies. Don’t Forget to join our 52k+ ML SubReddit. If you like our work, you will love our newsletter.
They also make available a sizable collection of artificially photorealistic photos matched with ground truth labels for these kinds of signals to overcome datascarcity. It can also be used for data obtained from a consumer’s cell phone. Check out the Paper and Project.
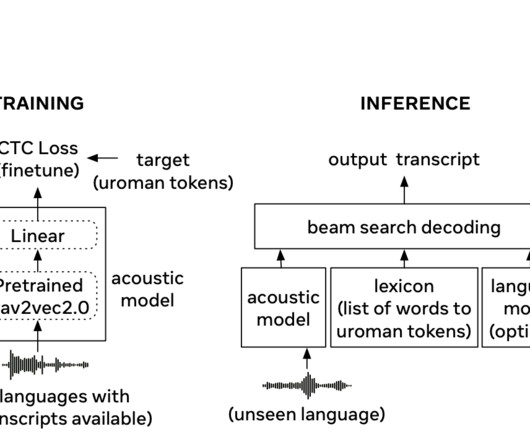
With its extensive language training and romanization technique, the MMS Zero-shot method offers a promising solution to the datascarcity challenge, advancing the field towards more inclusive and universal speech recognition systems. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
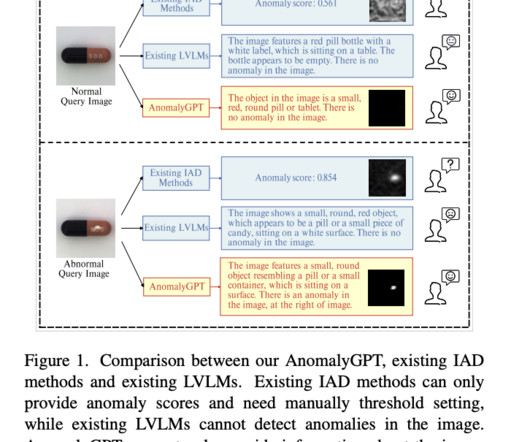
They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first. With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects.
This combination of technical depth and usability lowers the barrier for data scientists and ML engineers to generate synthetic data efficiently. By enabling straightforward generation of synthetic datasets, it allows organizations to experiment and train models without being hindered by datascarcity or privacy restrictions.
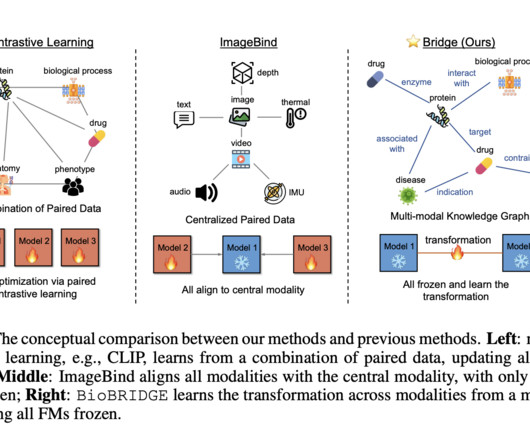
By aligning the embedding space of unimodal FMs through cross-modal transformation models utilizing KG triplets, BioBRIDGE maintains data sufficiency and efficiency and navigates the challenges posed by computational costs and datascarcity that hinder the scalability of multimodal approaches. Check out the Paper.
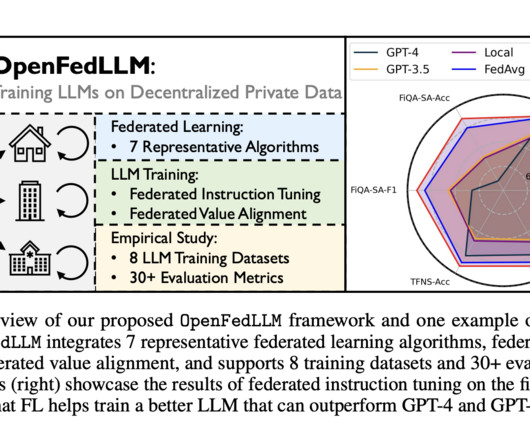
For instance, BloomberGPT excels in finance with private financial data spanning 40 years. Collaborative training on decentralized personal data, without direct sharing, emerges as a critical approach to support the development of modern LLMs amid datascarcity and privacy concerns. Check out the Paper and Github.
The approach generates over a million structured synthetic preferences to address datascarcity. Over 1M synthetic personalized preferences are generated to address datascarcity, ensuring diversity and consistency for effective real-world transfer. Check out the Paper.
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. The paper also explores alternative strategies to mitigate datascarcity. Fast, parallel, weakly-synchronized computation dominates in ML.
They use a three-stage training methodology—pretraining, ongoing training, and fine-tuning—to tackle the datascarcity of the SiST job. The team trains their model continuously using billions of tokens of low-quality synthetic speech translation data to further their goal of achieving modal alignment between voice and text.
To address datascarcity and granularity issues, the system employs sophisticated synthetic data generation techniques, particularly focusing on dense captioning and visual question-answering tasks. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
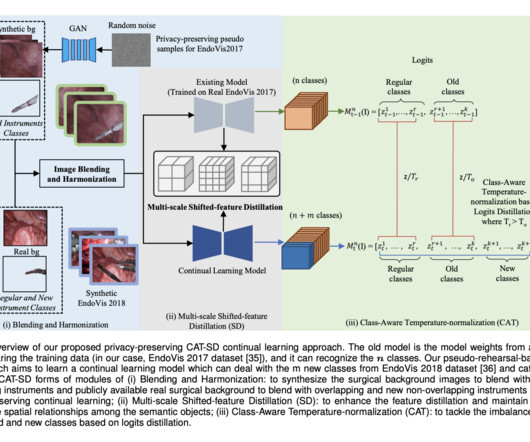
The developed CAT-SD scheme effectively mitigates catastrophic forgetting, addresses datascarcity, and ensures privacy in medical datasets. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Check out the Paper and Github. If you like our work, you will love our newsletter.
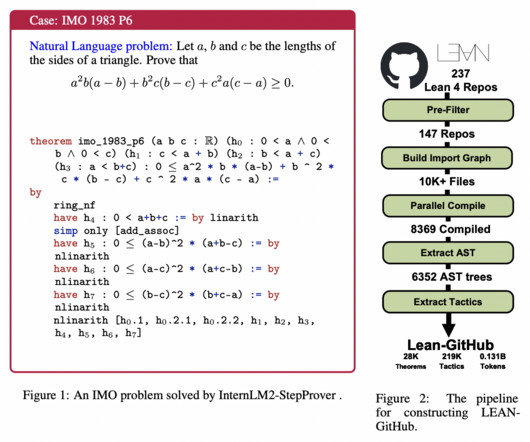
Large language models (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to datascarcity. Formalized systems like Lean, Isabelle, and Coq offer computer-verifiable proofs, but creating these demands substantial human effort.
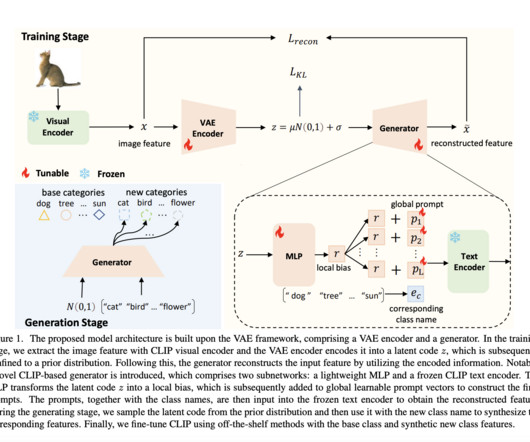
They aimed to train a generative model that can synthesize features by providing class names, which enables them to generate features for categories without data. Also, don’t forget to join our 27k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more.
Conclusion Tarsier2 marks a significant step forward in video understanding by addressing key challenges such as temporal alignment, hallucination reduction, and datascarcity. Dont Forget to join our 65k+ ML SubReddit. All credit for this research goes to the researchers of this project.
The expansion of question-answering (QA) systems driven by artificialintelligence (AI) results from the increasing demand for financial data analysis and management. Acquiring high-quality data is difficult, and copyright constraints frequently hinder sharing it. Also, don’t forget to follow us on Twitter.
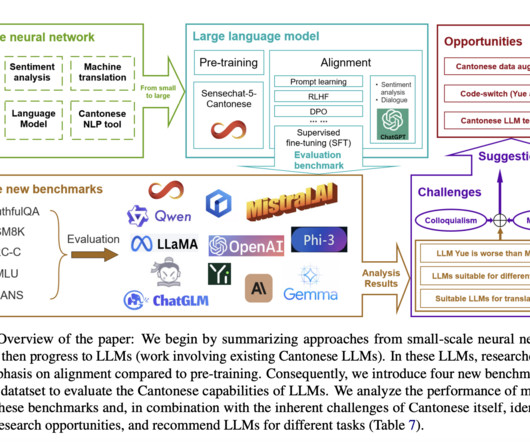
Language modeling faces challenges due to datascarcity, while various NLP tools cater to specific Cantonese processing needs. Cantonese large language model Recent advances in Cantonese LLMs show promise despite resource scarcity and language-specific challenges. Also, don’t forget to follow us on Twitter and LinkedIn.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content