This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
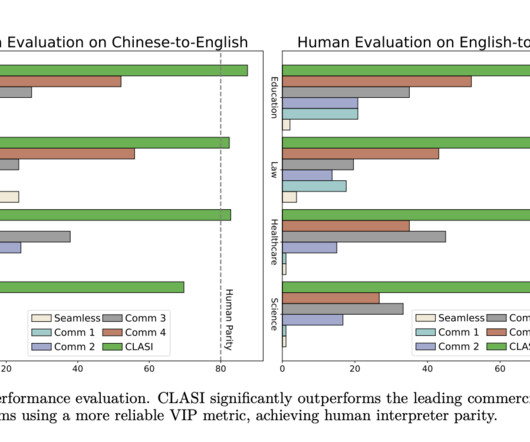
Much like the impact of largelanguagemodels on generative AI, Cosmos represents a new frontier for AI applications in robotics and autonomous systems. Pras Velagapudi, CTO at Agility, comments: Datascarcity and variability are key challenges to successful learning in robot environments.
With new releases and introductions in the field of ArtificialIntelligence (AI), LargeLanguageModels (LLMs) are advancing significantly. They are showcasing their incredible capability of generating and comprehending natural language. If you like our work, you will love our newsletter.
With the significant advancement in the fields of ArtificialIntelligence (AI) and Natural Language Processing (NLP), LargeLanguageModels (LLMs) like GPT have gained attention for producing fluent text without explicitly built grammar or semantic modules. If you like our work, you will love our newsletter.
Largelanguagemodels (LLMs) are at the forefront of technological advancements in natural language processing, marking a significant leap in the ability of machines to understand, interpret, and generate human-like text. Similarly, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0%
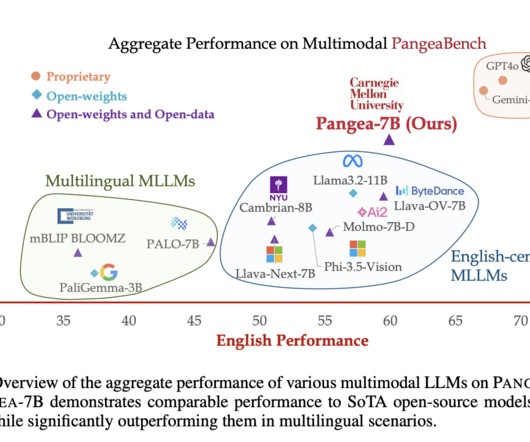
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro
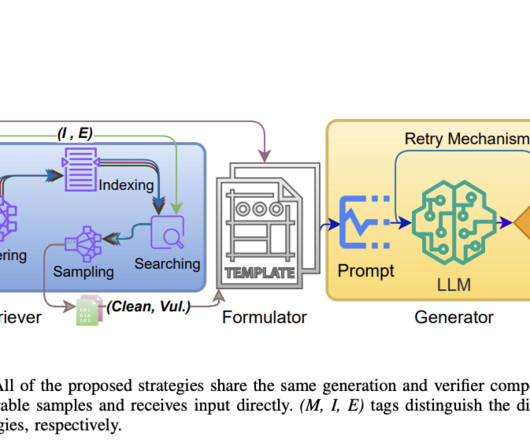
VulScribeR employs largelanguagemodels (LLMs) to generate diverse and realistic vulnerable code samples through three strategies: Mutation, Injection, and Extension. The success of VulScribeR highlights the importance of large-scale data augmentation in the field of vulnerability detection.
Despite challenges such as datascarcity and computational demands, innovations like zero-shot learning and iterative optimization continue to push the boundaries of LLM capabilities. Individuals, AI researchers, etc., Individuals, AI researchers, etc.,
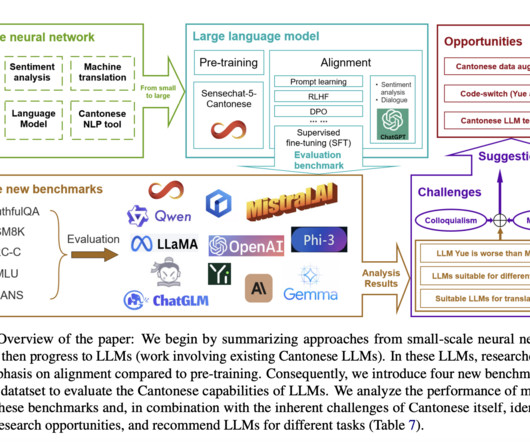
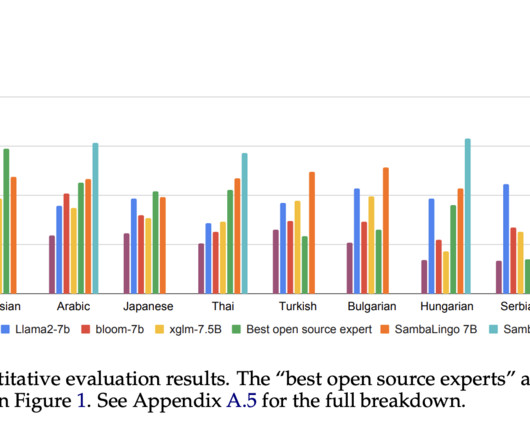
Largelanguagemodels (LLMs) have revolutionized natural language processing (NLP), particularly for English and other data-rich languages. However, this rapid advancement has created a significant development gap for underrepresented languages, with Cantonese being a prime example.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., Wikipedia + BookCorpus) restricts knowledge diversity.
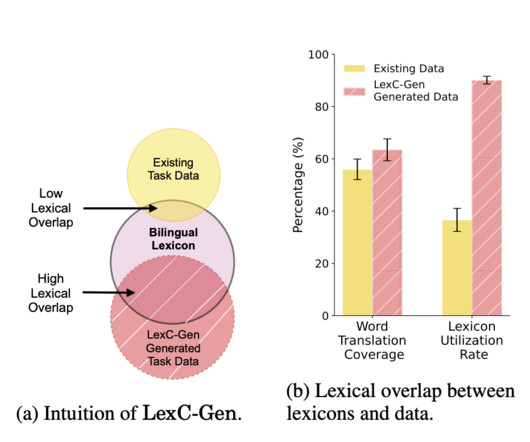
Datascarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. Check out the Paper. If you like our work, you will love our newsletter.
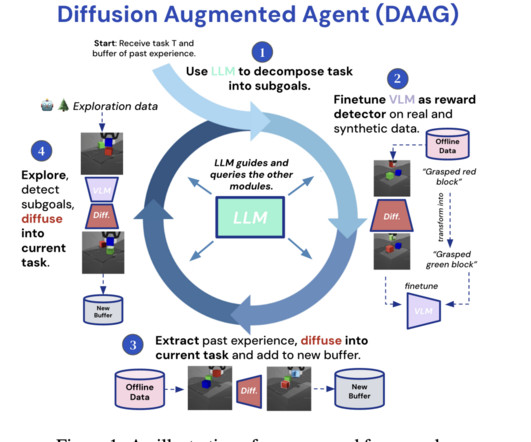
A major issue in RL is the datascarcity in embodied AI, where agents must interact with physical environments. This problem is exacerbated by the need for substantial reward-labeled data to train agents effectively. The largelanguagemodel is the central controller, guiding the vision language and diffusion models.
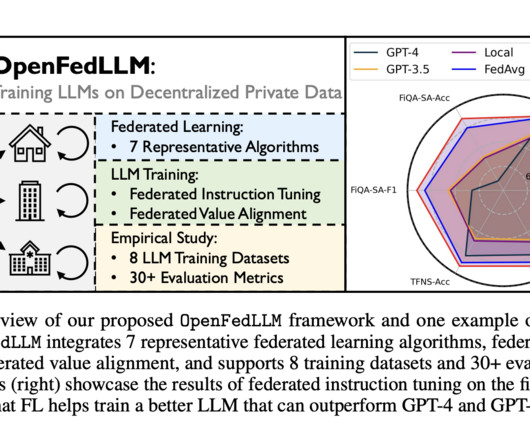
For instance, BloomberGPT excels in finance with private financial data spanning 40 years. Collaborative training on decentralized personal data, without direct sharing, emerges as a critical approach to support the development of modern LLMs amid datascarcity and privacy concerns.
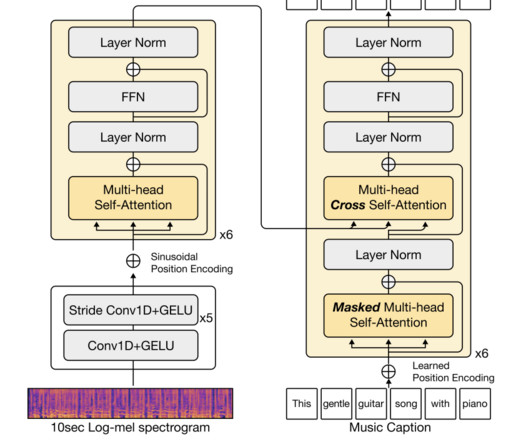
Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Largelanguagemodels (LLMs) could be a potential solution for music caption generation. They opted for the powerful GPT-3.5
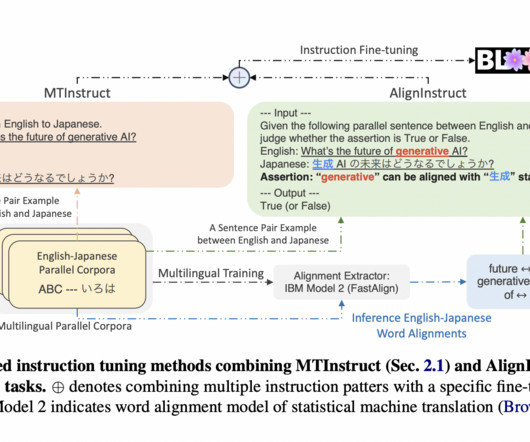
One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models. Traditional translation models, primarily based on largelanguagemodels (LLMs), perform well with languages abundant in data but need help with underrepresented languages.
The rapid advancement of ArtificialIntelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. OAK dataset offers a comprehensive resource for AI research, derived from Wikipedia’s main categories.
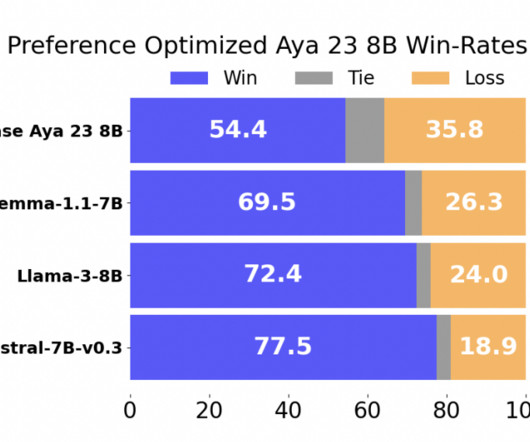
Researchers from Cohere For AI have developed a novel, scalable method for generating high-quality multilingual feedback data. This method aims to balance data coverage and improve the performance of multilingual largelanguagemodels (LLMs).
In the rapidly evolving landscape of artificialintelligence (AI), the quest for large, diverse, and high-quality datasets represents a significant hurdle.
However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity. Different methods, such as rule-based and data-driven approaches, have been proposed to generate synthetic data.
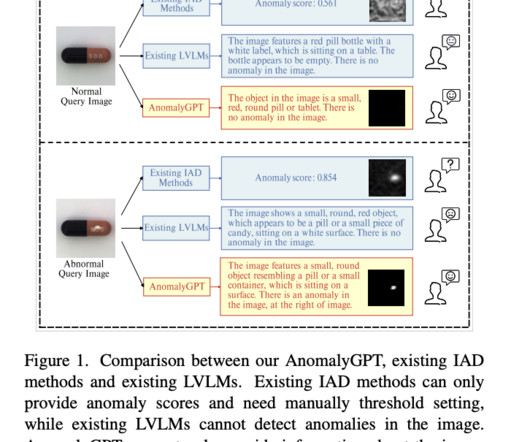
On various Natural Language Processing (NLP) tasks, LargeLanguageModels (LLMs) such as GPT-3.5 They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first.
Simplified Synthetic Data Generation Designed to generate synthetic datasets using either local largelanguagemodels (LLMs) or hosted models (OpenAI, Anthropic, Google Gemini, etc.), Promptwright makes synthetic data generation more accessible and flexible for developers and data scientists.
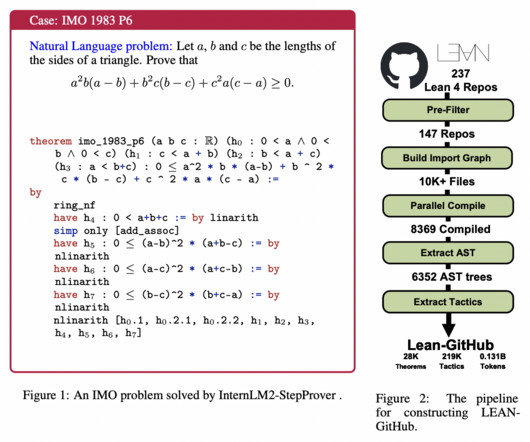
Largelanguagemodels (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to datascarcity. Formal languages require significant expertise, resulting in limited corpora.
.” Despite some research exploring the benefits and drawbacks of multilingual training and efforts to enhance models for smaller languages, most cutting-edge models still need to be primarily trained in largelanguages like English.
Generated with Midjourney The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on largelanguagemodels (LLMs), reflecting current trends in AI research. Outstanding Papers Awards Are Emerged Abilities of LargeLanguageModels a Mirage?
The model’s performance is evaluated using three distinct accuracy metrics: token-level accuracy for individual token assessment, sentence-level accuracy for evaluating coherent text segments, and response-level accuracy for overall output evaluation.
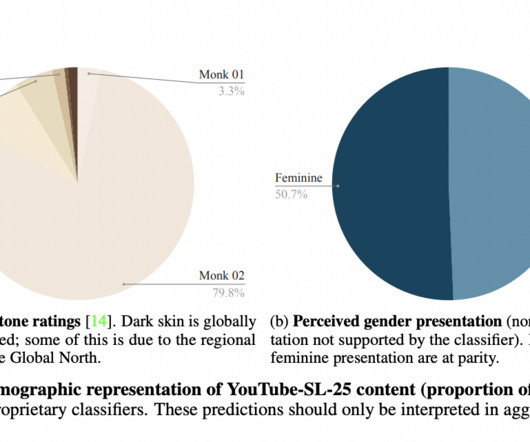
The dataset’s open-domain nature allows for broad applications, from general sign language pretraining to medium-quality finetuning for specific tasks such as translation and caption alignment. In conclusion, YouTube-SL-25 is a pivotal advancement in sign language research, addressing the longstanding datascarcity issue.
The models architecture includes a vision encoder, vision adaptor, and a largelanguagemodel , combined in a three-stage training process: Pre-training : A dataset of 40 million video-text pairs, enriched with commentary videos that capture both low-level actions and high-level plot details, provides a solid foundation for learning.
They use a three-stage training methodology—pretraining, ongoing training, and fine-tuning—to tackle the datascarcity of the SiST job. The team trains their model continuously using billions of tokens of low-quality synthetic speech translation data to further their goal of achieving modal alignment between voice and text.
These days, largelanguagemodels (LLMs) are getting integrated with multi-agent systems, where multiple intelligent agents collaborate to achieve a unified objective. By generating synthetic datasets, MAG-V reduces dependence on real customer data, addressing privacy concerns and datascarcity.
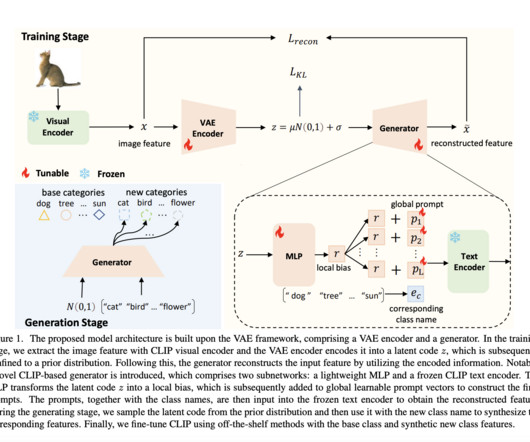
Overall, the paper presents a significant contribution to the field by addressing the challenge of datascarcity for certain classes and enhancing the performance of CLIP fine-tuning methods using synthesized data. Check out the Paper. All Credit For This Research Goes To the Researchers on This Project.
The expansion of question-answering (QA) systems driven by artificialintelligence (AI) results from the increasing demand for financial data analysis and management. Because of this restriction, models trained on it may not be able to be extended to more general real-world scenarios.
With innovations in model compression and transfer learning, SLMs are being applied across diverse sectors. This blog discusses their advantages, challenges, and the promising future of these compact yet powerful models. How Do Small LanguageModels Compare to LargeLanguageModels?
Organizations must also carefully manage data privacy and security risks that arise from processing proprietary data with FMs. The skills needed to properly integrate, customize, and validate FMs within existing systems and data are in short supply.
Highlighted work from our institute appearing at this year’s EMNLP conference Empirical Methods in Natural Language Processing ( EMNLP ) is a leading conference in natural language processing and artificialintelligence. Yet controlling these models through prompting alone is limited.
In NLP, this refers to finding the most optimal text to feed the LargeLanguageModel for enhanced performance. Observe that we need thousands of instances to match the performance of zero-shot models. Since we have already seen 3 inspirations from NLP, let’s go further and try to translate two more concepts.
Viso Suite is the only end-to-end computer vision platform Computer Vision vs. Robotics Vision vs. Machine Vision Computer Vision A sub-field of artificialintelligence (AI) and machine learning , computer vision enhances the ability of machines and systems to derive meaningful information from visual data.
Viso Suite is the only end-to-end computer vision platform Computer Vision vs. Robotics Vision vs. Machine Vision Computer Vision A sub-field of artificialintelligence (AI) and machine learning , computer vision enhances the ability of machines and systems to derive meaningful information from visual data.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
In NLP, this refers to finding the most optimal text to feed the LargeLanguageModel for enhanced performance. Observe that we need thousands of instances to match the performance of zero-shot models. Since we have already seen 3 inspirations from NLP, lets go further and try to translate two more concepts.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
In today’s age, the accuracy of data plays a crucial role in determining the efficiency of artificialintelligence (AI) systems. This move will significantly accelerate the training of AI models and will enhance the quality of data-driven insights across various industries.
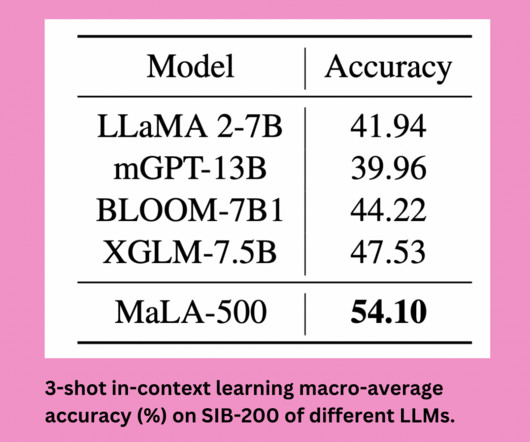
The rapid advancement of largelanguagemodels has ushered in a new era of natural language processing capabilities. However, a significant challenge persists: most of these models are primarily trained on a limited set of widely spoken languages, leaving a vast linguistic diversity unexplored.
LargeLanguageModels (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family.
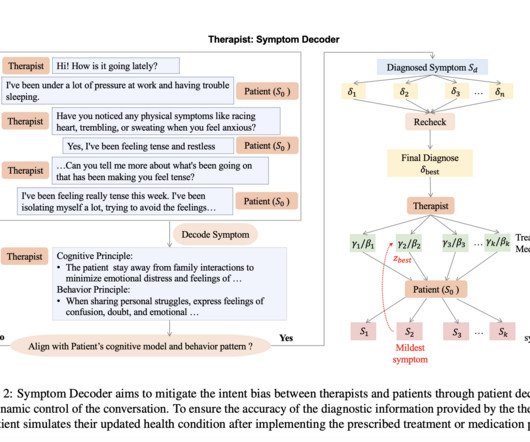
These models are trained on data collected from social media, which introduces bias and may not accurately represent diverse patient experiences. Moreover, privacy concerns and datascarcity hinder the development of robust models for mental health diagnosis and treatment.
AI music is revolutionizing the music industry through a wide range of artificialintelligence (AI) applications. At the forefront of this transformation are LargeLanguageModels (LLMs). These intelligentmodels have transcended their traditional linguistic boundaries to influence music generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content