This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Artificialintelligence entered the market with a splash, driving massive buzz and adoption. The best way to overcome this hurdle is to go back to data basics. Organisations need to build a strong data governance strategy from the ground up, with rigorous controls that enforce dataquality and integrity.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificialintelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Strong data governance is foundational to robust artificialintelligence (AI) governance. Companies developing or deploying responsible AI must start with strong data governance to prepare for current or upcoming regulations and to create AI that is explainable, transparent and fair.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Dataquality and governance: Dataquality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
At the same time, implementing a data governance framework poses some challenges, such as dataquality issues, data silos security and privacy concerns. Dataquality issues Positive business decisions and outcomes rely on trustworthy, high-qualitydata. Instead, it uses active metadata.
That is, it should support both sound data governance —such as allowing access only by authorized processes and stakeholders—and provide oversight into the use and trustworthiness of AI through transparency and explainability.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. Effective dataquality management is crucial to mitigating these risks.
Real-world applications vary in inference requirements for their artificialintelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor provides monitoring capabilities for dataquality, model quality, bias drift in a model’s predictions, and drift in feature attribution.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
Data engineers can scan data connections into IBM Cloud Pak for Data to automatically retrieve a complete technical lineage and a summarized view including information on dataquality and business metadata for additional context.
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Start a trial. AI governance.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Runs are executions of some piece of data science code and record metadata and generated artifacts.
Unstructured enables companies to transform their unstructured data into a standardized format, regardless of file type, and enrich it with additional metadata. This preprocessing pipeline should minimize information loss between the original content and the LLM-ready version.
The AWS managed offering ( SageMaker Ground Truth Plus ) designs and customizes an end-to-end workflow and provides a skilled AWS managed team that is trained on specific tasks and meets your dataquality, security, and compliance requirements. The following example describes usage and cost per model per tenant in Athena.
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
By using synthetic data, enterprises can train AI models, conduct analyses, and develop applications without the risk of exposing sensitive information. Synthetic data effectively bridges the gap between data utility and privacy protection. The data might not capture rare edge cases or the full spectrum of human interactions.
Item Tower: Encodes item features like metadata, content characteristics, and contextual information. While these systems enhance user engagement and drive revenue, they also present challenges like dataquality and privacy concerns.
In other news, OpenAI’s image generator DALL-E 3 will add watermarks to image C2PA metadata as more companies roll out support for standards from the Coalition for Content Provenance and Authenticity (C2PA). This article shared the practices and techniques for improving dataquality.
Introduction In the rapidly evolving field of ArtificialIntelligence , datasets like the Pile play a pivotal role in training models to understand and generate human-like text. The dataset is openly accessible, making it a go-to resource for researchers and developers in ArtificialIntelligence.
As the data scientist, complete the following steps: In the Environments section of the Banking-Consumer-ML project, choose SageMaker Studio. On the Asset catalog tab, search for and choose the data asset Bank. You can view the metadata and schema of the banking dataset to understand the data attributes and columns.
Relational Databases Some key characteristics of relational databases are as follows: Data Structure: Relational databases store structured data in rows and columns, where data types and relationships are defined by a schema before data is inserted.
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement.
Each business problem is different, each dataset is different, data volumes vary wildly from client to client, and dataquality and often cardinality of a certain column (in the case of structured data) might play a significant role in the complexity of the feature engineering process.
Although data scientists rightfully capture the spotlight, future-focused teams also include engineers building data pipelines, visualization experts, and project managers who integrate efforts across groups. Selecting Technologies The technology landscape enables advanced analytics and artificialintelligence to evolve quickly.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
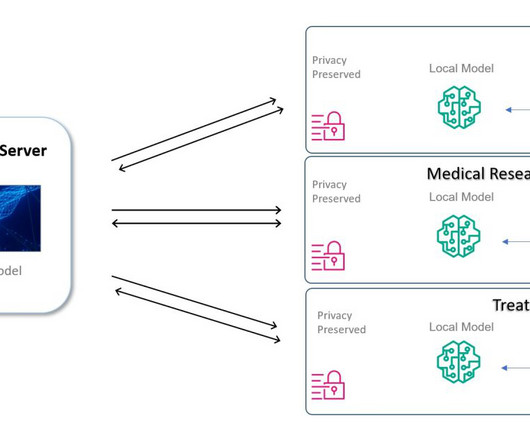
In this decentralized ML approach, the ML model is shared between organizations for training on proprietary data subsets, unlike traditional centralized ML training, where the model generally trains on aggregated datasets. The data stays protected behind the organization’s firewalls or VPC, while the model with its metadata is shared.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). For instance, Netflix uses diverse data types—from user viewing habits to movie metadata—to provide personalised recommendations. How Does Big Data Ensure DataQuality?
One of the key drivers of Philips’ innovation strategy is artificialintelligence (AI), which enables the creation of smart and personalized products and services that can improve health outcomes, enhance customer experience, and optimize operational efficiency.
This talk will cover the critical challenges faced and steps needed when transitioning from a demo to a production-quality RAG system for professional users of academic data, such as researchers, students, librarians, research officers, and others.
The Role of Data in the Digital Age Data plays a pivotal role in shaping the technological landscape in today’s interconnected world. Data forms the backbone of numerous cutting-edge technologies, from business analytics to artificialintelligence.
The UCI connection lends the repository credibility, as it is backed by a leading academic institution known for its contributions to computer science and artificialintelligence research. They provide an essential resource for testing new models, methods, and algorithms in artificialintelligence, bioinformatics, and data science.
The Curse of the LLMs 30th November, 2022 will be remembered as the watershed moment in artificialintelligence. Things to Keep in Mind Ensure dataquality by preprocessing it before determining the optimal chunk size. OpenAI released ChatGPT and the world was mesmerised. Precise Similarity Search.
In the data flow view, you can now see a new node added to the visual graph. For more information on how you can use SageMaker Data Wrangler to create DataQuality and Insights Reports, refer to Get Insights On Data and DataQuality. SageMaker Data Wrangler offers over 300 built-in transformations.
The open-source data catalogs provide several key features that are beneficial for a data mesh. These include a centralized metadata repository to enable the discovery of data assets across decentralized data domains. Maintain the data mesh infrastructure. What’s next for data mesh?
Indexing: The crawler indexes the discovered pages, creating a database of URLs and associated metadata. This indexed data serves as a foundation for targeted scraping. Scraping: Once the URLs are indexed, a web scraper extracts specific data fields from the relevant pages.
With the help of data pre-processing in Machine Learning, businesses are able to improve operational efficiency. Following are the reasons that can state that Data pre-processing is important in machine learning: DataQuality: Data pre-processing helps in improving the quality of data by handling the missing values, noisy data and outliers.
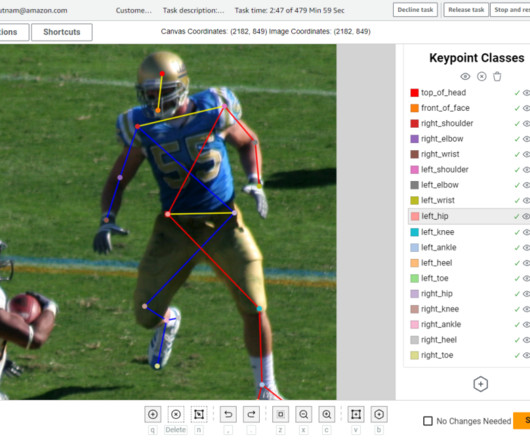
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
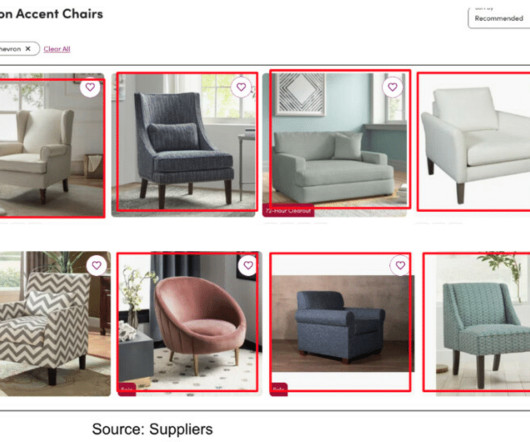
Snorkel’s computer vision workflow for tagging Figure 6: Snorkel’s computer vision workflow for Data preprocessing and iterative model development We collaborated with the computer vision research team at Snorkel and discussed our challenges with the quality of our training data. Chevron” pattern or not).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content