This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation. We unify source data, metadata, operational data, vector data and generated data—all in one platform.
The assistant then orchestrates a multi-source data collection process, performing web searches while also pulling account metadata from OpenSearch, Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3) storage.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
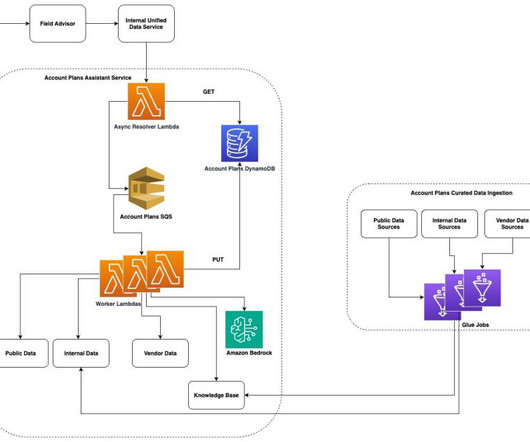
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG). You can now interact with your documents in real time without prior dataingestion or database configuration.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Getting recommendations along with metadata makes it more convenient to provide additional context to LLMs. You can also use this for sequential chains.
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. For information about model pricing, refer to Amazon Bedrock pricing.
In this post, we discuss how the IEO developed UNDP’s artificialintelligence and machine learning (ML) platform—named ArtificialIntelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. She is passionate about enabling customers on their data/AI journey to the cloud.
Data sources are essential components in the Chronon ecosystem. Whether near real-time or daily intervals, Chronon’s “Temporal” or “Snapshot” accuracy models ensure that computations align with each use-case’s specific requirements.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Principal and AWS collaborated on a new AWS Lambda function that was added to the Step Functions workflow.
Refer to the Amazon Forecast Developer Guide for information about dataingestion , predictor training , and generating forecasts. If you have item metadata and related time series data, you can also include these as input datasets for training in Forecast. Egor Miasnikov is a Solutions Architect at AWS based in Germany.
In this session, you’ll explore the following questions Why Ray was built and what it is How AIR, built atop Ray, allows you to easily program and scale your machine learning workloads AIR’s interoperability and easy integration points with other systems for storage and metadata needs AIR’s cutting-edge features for accelerating the machine learning (..)
As the data scientist, complete the following steps: In the Environments section of the Banking-Consumer-ML project, choose SageMaker Studio. On the Asset catalog tab, search for and choose the data asset Bank. You can view the metadata and schema of the banking dataset to understand the data attributes and columns.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Streamlining Unstructured Data for Retrieval Augmented Generation Matt Robinson | Open Source Tech Lead | Unstructured In this talk, you’ll explore the complexities of handling unstructured data, and offer practical strategies for extracting usable text and metadata from unstructured data.
Data Engineering TrackBuild the Data Foundation forAI Data engineering powers every AI system. This track offers practical guidance on building scalable data pipelines and ensuring dataquality.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificialintelligence (AI), are simply not practically possible, without hardware acceleration. 32xlarge 0 16 0 128 512 512 4 x 1.9
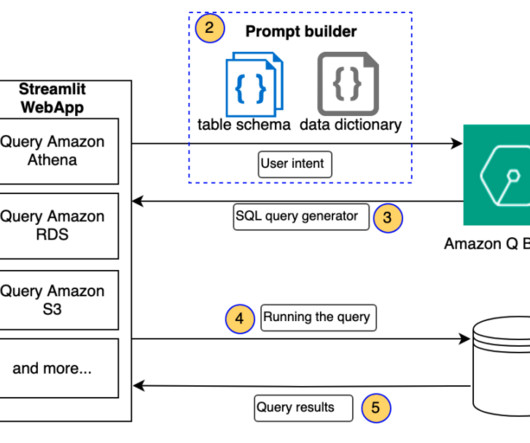
One of the most common applications of generative artificialintelligence (AI) and large language models (LLMs) in an enterprise environment is answering questions based on the enterprise’s knowledge corpus. In response, Amazon Q Business provides an appropriate Athena query to run.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
The core challenge lies in developing data pipelines that can handle diverse data sources, the multitude of data entities in each data source, their metadata and access control information, while maintaining accuracy. As a result, they can index one time and reuse that indexed content across use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content