This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Moreover, modern CRM systems also leverage artificialintelligence (AI) to enhance the functionalities of CRM tools. By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history.
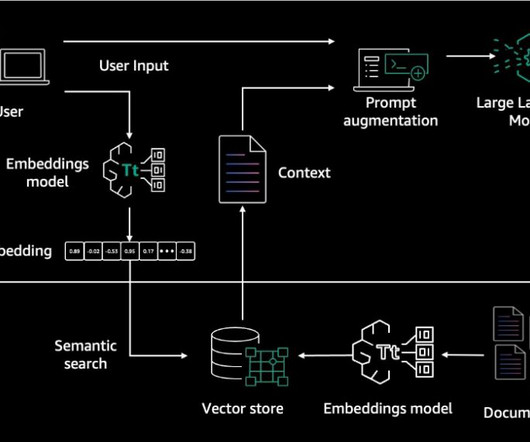
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
ArtificialIntelligence (AI) has made significant progress in recent years, transforming how organizations manage complex data and make decisions. With the vast amount of data available, many industries face the critical challenge of acting on real-time insights. This is where prescriptive AI steps in.
Moreover, data is often an afterthought in the design and deployment of gen AI solutions, leading to inefficiencies and inconsistencies. Unlocking the full potential of enterprise data for generative AI At IBM, we have developed an approach to solving these data challenges.
Understanding Drasi Drasi is an advanced event-driven architecture powered by ArtificialIntelligence (AI) and designed to handle real-time data changes. Traditional data systems often rely on batch processing, where data is collected and analyzed at set intervals.
By facilitating efficient data integration and enhancing LLM performance, LlamaIndex is tailored for scenarios where rapid, accurate access to structured data is paramount. Key Features of LlamaIndex: Data Connectors: Facilitates the integration of various data sources, simplifying the dataingestion process.
Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation. This remains unchanged in the age of artificialintelligence.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
Join the AI conversation and transform your advertising strategy with AI weekly sponsorship ArtificialIntelligence Weekly This RSS feed is published on [link]. You can also subscribe via email.
Artificialintelligence (AI) is revolutionizing industries by enabling advanced analytics, automation and personalized experiences. Accelerated data processing Efficient data processing pipelines are critical for AI workflows, especially those involving large datasets.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
The average cost of a data breach set a new record in 2023 of USD 4.45 million, and the IBM X-Force Threat Intelligence Index revealed a threat landscape with a predominance of extortion-motivated attacks and signs of increased collaboration between cybercriminal groups.
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
An AI Copilot is an artificialintelligence system that assists developers, programmers, or other professionals in various tasks related to software development, coding, or content creation. AI Copilots leverage various artificialintelligence, natural language processing (NLP), machine learning, and code analysis.
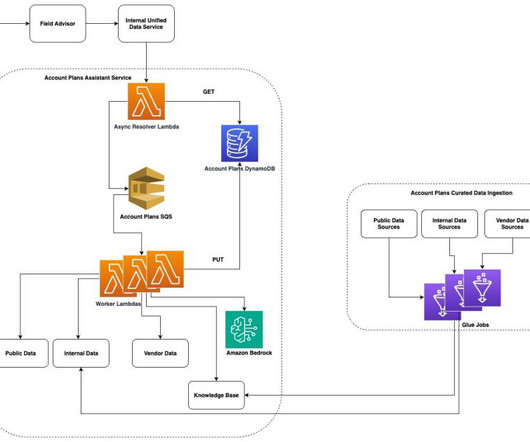
Rockets legacy data science architecture is shown in the following diagram. The diagram depicts the flow; the key components are detailed below: DataIngestion: Data is ingested into the system using Attunity dataingestion in Spark SQL.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration.
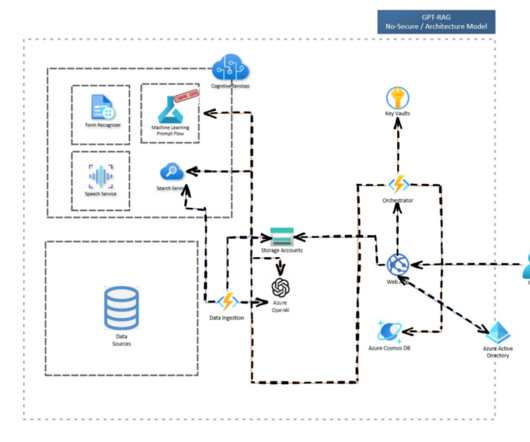
This observability ensures continuity in operations and provides valuable data for optimizing the deployment of LLMs in enterprise settings. The key components of GPT-RAG are dataingestion, Orchestrator, and front-end app.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Hence, there is no one-size-fits-all data warehouse solution.
FM-powered artificialintelligence (AI) assistants have limitations, such as providing outdated information or struggling with context outside their training data. You can now interact with your documents in real time without prior dataingestion or database configuration. What is Retrieval Augmented Generation?
The platform’s interactive UI, powered by Gradio, enhances the user experience by simplifying the dataingestion and parsing process. In conclusion, OmniParse addresses the significant challenge of handling unstructured data by providing a versatile and efficient platform that supports multiple data types.
Through its RAG architecture, we semantically search and use metadata filtering to retrieve relevant context from diverse sources: internal sales enablement materials, historic APs, SEC filings, news articles, executive engagements and data from our CRM systems.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificialintelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
Data quality standards make sure that organizations are making data-driven decisions to meet their business goals. Data quality is not only essential for smooth, daily business operations, but is also crucial for adopting and integrating artificialintelligence (AI) and automation technologies.
But what if we could build an AI (ArtificialIntelligence) system that not only understands the text but also comprehends the visual elements, allowing us to have natural conversations about any PDF? Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Data Indexes : Post dataingestion, LlamaIndex assists in indexing this data into a retrievable format.
Application Programming Interface (API) plays a crucial role in ML systems to facilitate communication and interaction between different components, e.g., model deployment and interface, dataingestion, etc. In this post, we will introduce a package that could help develop RESTful APIs in Julia U+1F680.
The company’s approach allows businesses to efficiently handle data growth while ensuring security and flexibility throughout the data lifecycle. Can you provide an overview of Quantum’s approach to AI-driven data management for unstructured data?
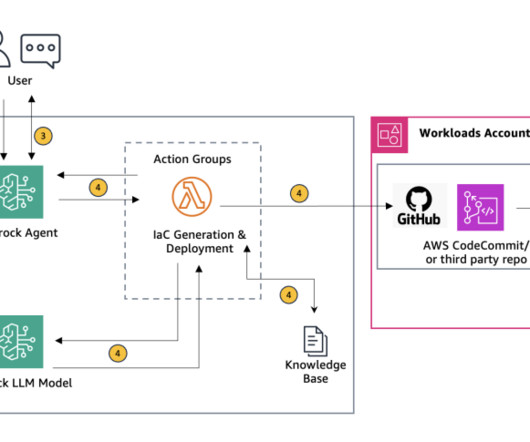
Select the KB and in the Data source section, choose Sync to begin dataingestion. When dataingestion completes, a green success banner appears if it is successful. This interaction allows for a more tailored and precise IaC configuration. Double-check all entered information for accuracy.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment.
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
In the evolving landscape of artificialintelligence, language models are becoming increasingly integral to a variety of applications, from customer service to real-time data analysis. One key challenge, however, remains: preparing documents for ingestion into large language models (LLMs). Check out the GitHub Page.
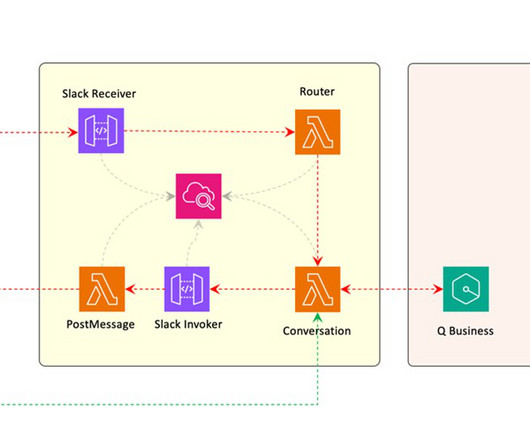
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
It provides components for dataingestion, validation, and feature extraction. Strengths: Scalable, integrates well with other tools like Apache Airflow and Kubeflow, and provides comprehensive data validation capabilities. Weaknesses: Steep learning curve, especially during initial setup.
You should see two pipelines created: car-data-ingestion-pipeline and car-data-aggregated-ingestion-pipeline. You should see two pipelines created: car-data-ingestion-pipeline and car-data-aggregated-ingestion-pipeline. Choose the car-data-ingestion-pipeline.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
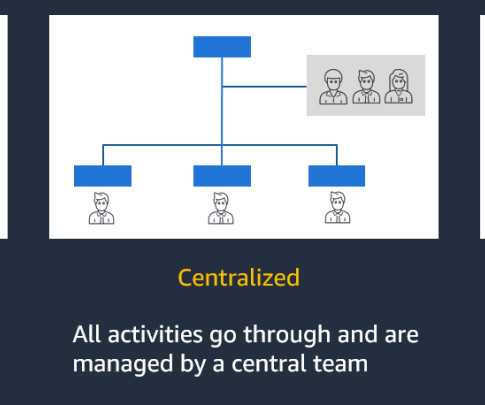
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
The system is meticulously designed for high flexibility in data processing tasks, including deduplication, bias mitigation, and toxicity removal, without specifying the use of particular datasets in the paper.
Manage data through standard methods of dataingestion and use Enriching LLMs with new data is imperative for LLMs to provide more contextual answers without the need for extensive fine-tuning or the overhead of building a specific corporate LLM.
In this post, we discuss how the IEO developed UNDP’s artificialintelligence and machine learning (ML) platform—named ArtificialIntelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content