This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ahead of AI & BigData Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes. This remains unchanged in the age of artificialintelligence.
Ahead of AI & BigData Expo Europe, AI News caught up with Ivo Everts, Senior Solutions Architect at Databricks , to discuss several key developments set to shape the future of open-source AI and data governance. With our GenAI app you can generate your own cartoon picture, all running on the DataIntelligence Platform.”
With their own unique architecture, capabilities, and optimum use cases, data warehouses and bigdata systems are two popular solutions. The differences between data warehouses and bigdata have been discussed in this article, along with their functions, areas of strength, and considerations for businesses.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
Our composable CDP ensures your data is AI-ready, helping you collect, clean, and activate customer data with our open, API-first platform and 450+ pre-built connectors that enable you to start with data anywhere and activate it everywhere. HT: Twilio Segment is excited to be taking part in AI & BigData Expo Europe in 2023!
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
Our product is one of those that is able to do the entire automation including the ETL pipelines and data modeling and loading data into your star schemas or data wall automatically and also maintaining it using CDC.
ELT Pipelines: Typically used for bigdata, these pipelines extract data, load it into data warehouses or lakes, and then transform it. It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Existing research emphasizes the significance of distributed processing and data quality control for enhancing LLMs. Utilizing frameworks like Slurm and Spark enables efficient bigdata management, while data quality improvements through deduplication, decontamination, and sentence length adjustments refine training datasets.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
After understanding data science let’s discuss the second concern “ Data Science vs AI ”. So, we know that data science is a process of getting insights from data and helps the business but where this ArtificialIntelligence (AI) lies?
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
You may use OpenRefine for more than just data cleaning; it can also help you find mistakes and outliers that could compromise your data’s quality. Apache Griffin Apache Griffin is an open-source data quality tool that aims to enhance bigdata processes.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. Apache Spark is an open-source, unified analytics engine for large-scale data processing.
Predictive analytics uses methods from data mining, statistics, machine learning, mathematical modeling, and artificialintelligence to make future predictions about unknowable events. It creates forecasts using historical data. Predictive analytics can make use of both structured and unstructured data insights.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Data Quality: Without proper governance, data quality can become an issue. Performance: Query performance can be slower compared to optimized data stores. Business Applications: BigData Analytics : Supporting advanced analytics, machine learning, and artificialintelligence applications.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
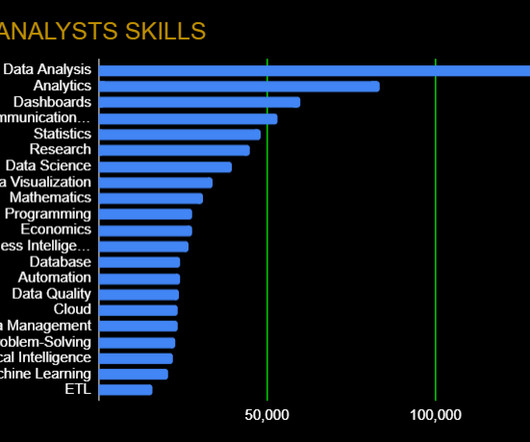
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
Bigdata analytics are supported by scalable, object-oriented services. Each of the “buckets” used to store data has a maximum capacity of 5 terabytes. Db2 Warehouse A fully managed, scalable cloud data storage platform is IBM Db2 Warehouse. Pre-ETL mapping was first used by Analytics pioneer Mike Boggs.
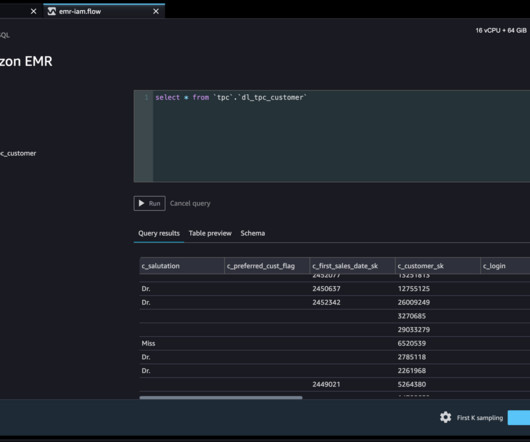
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional Data Modeling in the Modern Era Building BigData Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of BigData and Gen AI Introduction to Containers for Data Science / Data Engineering (..)
The mode is the value that appears most frequently in a data set. Machine learning is a subset of artificialintelligence that enables computers to learn from data and improve over time without being explicitly programmed. Data Warehousing and ETL Processes What is a data warehouse, and why is it important?
Generative artificialintelligence (AI) applications powered by large language models (LLMs) are rapidly gaining traction for question answering use cases. About the Authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
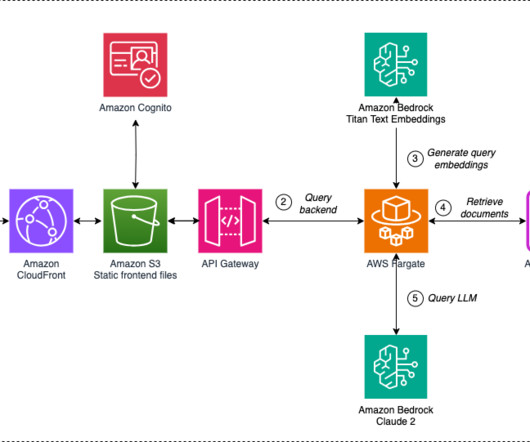
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior Data Scientist at Keepler. Generative artificialintelligence (AI) is rapidly emerging as a transformative force, poised to disrupt and reshape businesses of all sizes and across industries.
Power Query Power Query is a powerful ETL (Extract, Transform, Load) tool within Power BI that helps users clean and transform raw data into usable formats. Key Features Data Cleaning Functions: Remove duplicates, fill missing values, or standardise formats. Impact: Scales seamlessly as organisational data grows.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content