This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API.
Unlike previous frameworks that require predefined tool configurations, OctoTools introduces tool cards, which encapsulate tool functionalities and metadata. The planner first analyzes the user query and determines the appropriate tools based on metadata associated with each tool card. in medical question answering.
These applications leverage AI tasks such as object detection, segmentation, video metadata and re-identification to rapidly and accurately identify legitimate vs. suspicious or abnormal people or behavior and trigger responses in real time. The most common AI use cases in surveillance systems include perimeter protection and access control.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
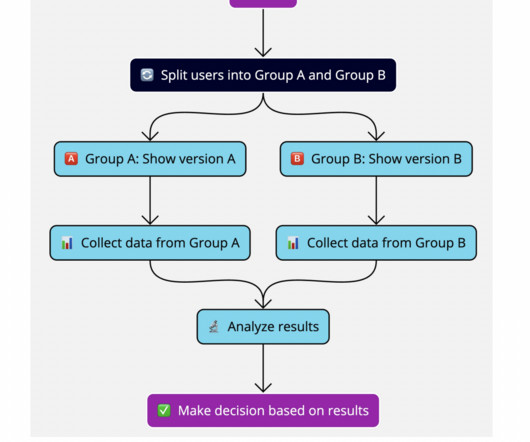
From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes. Have you ever wondered how these algorithms arrive at their conclusions? Executives evaluating decisions made by ML algorithms need to have faith in the conclusions they produce.
Researchers from the University of Toronto present an insightful examination of the advanced algorithms used in modern ad and content recommendation systems. This survey examines these systems’ most effective retrieval algorithms, highlighting their underlying mechanisms and challenges.
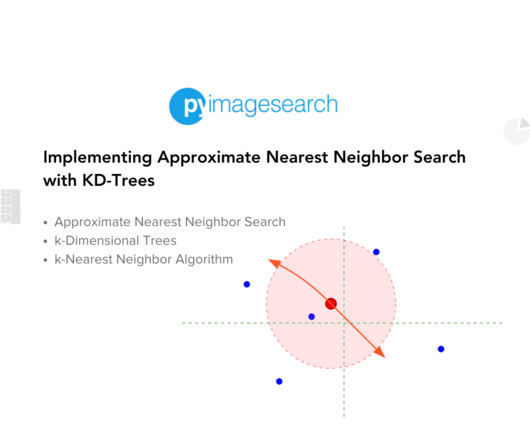
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes. These deep-learning algorithms dissect individual preferences based on various musical elements such as tempo and mood to craft personalized song suggestions. Creating music using artificial intelligence began several decades ago.
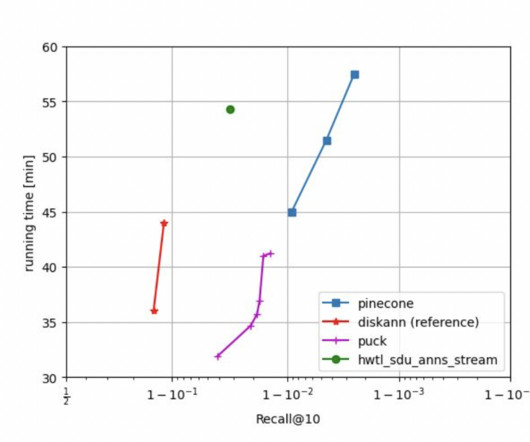
Participants face four distinct tracks, each tackling a different aspect of the challenge: Filter Track: This track focuses on efficiently finding nearest neighbors while filtering results based on specific tags or metadata. They invested in developing new algorithms and optimizing existing techniques to compete with other teams.
The company specializes in image processing and AI, with extensive expertise in research, implementation, and optimization of algorithms for embedded platforms and the in-car automotive industry. Our solutions analyze the video stream in real-time, translating it to metadata. Yehuda Holtzman serves as the CEO of Cipia.
Second, the LightAutoML framework limits the range of machine learning models purposefully to only two types: linear models, and GBMs or gradient boosted decision trees, instead of implementing large ensembles of different algorithms.
Blockchain networks store data with high resilience & integrity that makes it almost impossible to tamper with the data which is the major reason why the outcome of machine learning algorithms when they make decisions using blockchain smart contracts cannot be disputed, and can be trusted.
The Paillier algorithm works as depicted. Furthermore, encryption technologies such as homomorphic encryption, differential privacy protection, digital signature algorithms, asymmetric encryption algorithms, and hash algorithms, can prevent unauthorized & illegal access by non-authorized users and ensure data confidentiality.
Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. FMEval offers flexibility in dataset handling, model integration, and algorithm implementation. Model runner Composes input, and invokes and extracts output from your model.
Name a product and extract metadata to generate a tagline and description In the field of marketing and product development, coming up with a perfect product name and creative promotional content can be challenging. The image was generated using the Stability AI (SDXL 1.0) model on Amazon Bedrock.
Using examples from the dataset, we’ll build a classification model with decision tree algorithm. I extract the hour part of these values to create, hopefully, better features for the learning algorithm. Train a decision tree model Now the training dataset is ready for the decision tree algorithm.
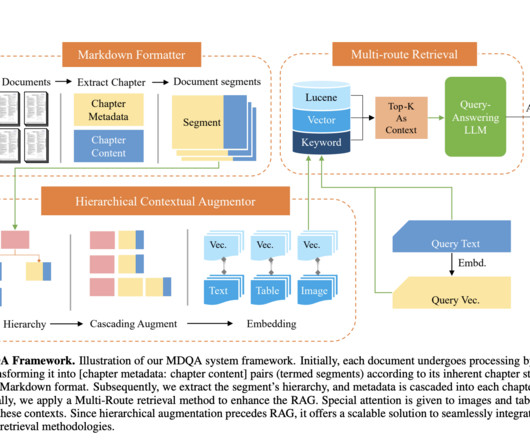
Researchers from Cornell University have introduced HiQA, a novel framework developed by integrating cascading metadata and a multi-route retrieval mechanism. The Hierarchical Contextual Augmentor (HCA) enriches these segments with hierarchical metadata, optimizing the information structure for retrieval.
To search against the database, you can use a vector search, which is performed using the k-nearest neighbors (k-NN) algorithm. When you perform a search, the algorithm computes a similarity score between the query vector and the vectors of stored objects using methods such as cosine similarity or Euclidean distance. Choose Confirm.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
With the recipes —algorithms for specific uses cases—provided by Amazon Personalize, you can deliver a wide array of personalization, including product or content recommendations and personalized ranking. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts. compared to previous versions.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party big data sources. Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model.
Team Whistle is using AI to generate metadata for its videos on social platforms like TikTok and YouTube and claimed more of these videos have gone viral, which evp of content Noah Weissman credits in part to the technology. One TikTok video that Team Whistle used AI to help with research, metadata and scripting has over 176,000 views.
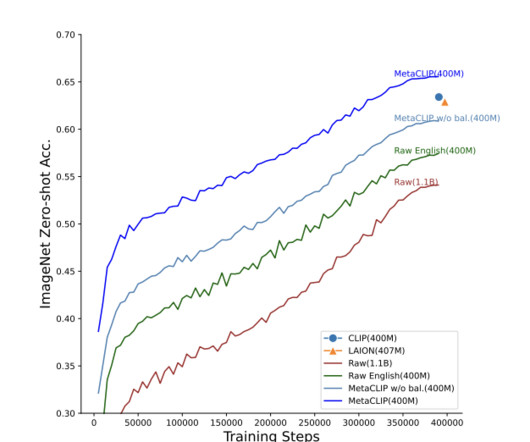
Researchers believe that CLIP owes its effectiveness to the data it was trained on, and they believe that uncovering the data curation process would allow them to create even more effective algorithms. All texts associated with each metadata entry are then grouped into lists, creating a mapping from each entry to the corresponding texts.
makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. The web pages are loaded as LangChain documents , which include the page content as a string and metadata associated with that document, e.g., the source pages URL.
By embedding metadata into images and other digital files, Adobe enables artists to assert ownership and trace the origin of their work. This is especially important in an era where digital content is increasingly driven by machine learning algorithms.
It was equally important that this infrastructure contained consistent metadata and data structures across all entities, preventing data redundancy and streamlining processes. This was done by incorporating mathematical optimization and machine learning algorithms completing the holistic approach for more efficiency.
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
Promote cross- and up-selling Recommendation engines use consumer behavior data and AI algorithms to help discover data trends to be used in the development of more effective up-selling and cross-selling strategies, resulting in more useful add-on recommendations for customers during checkout for online retailers.
Using recipes (algorithms prepared for specific uses cases) provided by Amazon Personalize, you can offer diverse personalization experiences like “recommend for you”, “frequently bought together”, guidance on next best actions, and targeted marketing campaigns with user segmentation. You can also use this for sequential chains.
The Sinkhorn regularization parameter is set to 0.05, and it performs 10 iterations of the algorithm. However, this approach needs to filter images, and it works best only when a textual metadata is present. An algorithm that can learn the patterns from a large amount of images without any labels, annotations, or metadata.
Challenges in rectifying biased data: If the data is biased from the beginning, “ the only way to retroactively remove a portion of that data is by retraining the algorithm from scratch.” This may cause the model to exclude entire areas, departments, demographics, industries or sources from the conversation.
Generative AI uses an advanced form of machine learning algorithms that takes users prompts and uses natural language processing (NLP) to generate answers to almost any question asked. Automatic capture of model metadata and facts provide audit support while driving transparent and explainable model outcomes. What is generative AI?
Different tokenizers output different token splits based on algorithm, vocabulary size, and encoding rules. BPE is an algorithm that decides how to split text, but GPT models use a custom version of BPE). Metadata (optional): May include timestamps, speaker labels, or token-counts per speaker (for advanced models).
Summary: Depth First Search (DFS) is a fundamental algorithm used for traversing tree and graph structures. Introduction Depth First Search (DFS) is a fundamental algorithm in Artificial Intelligence and computer science, primarily used for traversing or searching tree and graph data structures. What is Depth First Search?
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The search microservice processes the query requests and retrieves relevant listings from Elasticsearch using keyword search (BM25 as a ranking algorithm).
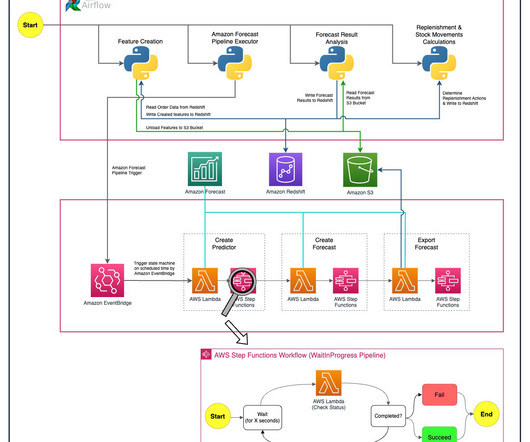
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios.
We don’t have better algorithms; we just have more data. With a pipeline and incremental snapshots, metadata documentation is essential to track: Data Source… Read the full blog for free on Medium. Table: Research Phase vs Production Phase Datasets The contrast highlights the “production data” we’ll call “data” in this post.
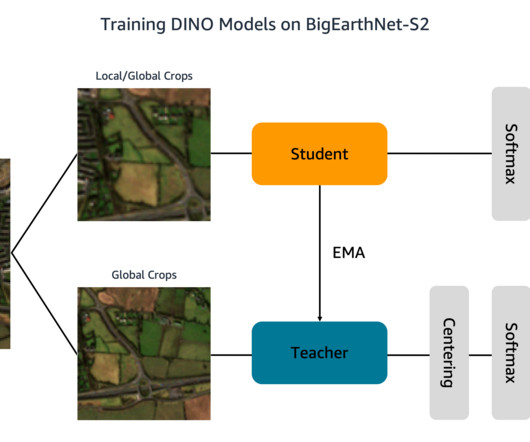
Our solution is based on the DINO algorithm and uses the SageMaker distributed data parallel library (SMDDP) to split the data over multiple GPU instances. Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. Accelerate Processes Investigators can use AI to accelerate examination, analysis and reporting significantly since these algorithms can rapidly analyze large amounts of data.
Automated Reasoning checks help prevent factual errors from hallucinations using sound mathematical, logic-based algorithmic verification and reasoning processes to verify the information generated by a model, so outputs align with provided facts and arent based on hallucinated or inconsistent data.
JWTs are signed using a cryptographic algorithm to ensure that the claims can’t be altered after the token is issued. Header – It contains parts like type of the token, which is JWT, the signing algorithm being used, such as HMAC SHA256 or RSA, and an optional key identifier. For Algorithm , choose the HS256 algorithm.
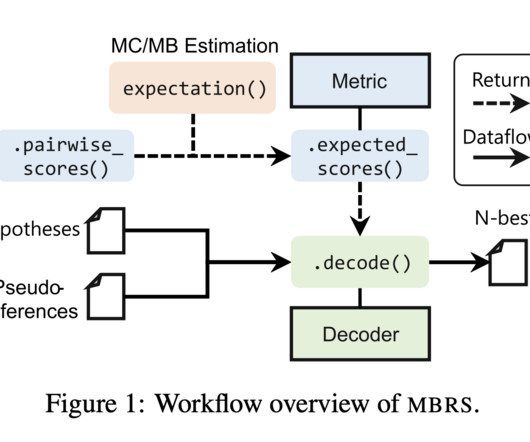
NAIST introduced MBRS, a new library specifically designed for MBR decoding, which supports a range of metrics and algorithmic variants. Additionally, MBRS provides metadata analysis capabilities, allowing users to analyze the origins of output texts and visualize the decision-making process of MBR decoding.
It works by analyzing audio signals, identifying patterns, and matching them to words and phrases using advanced algorithms. The primary drawbacks of cloud-based solutions are their cost and the lack of control over the underlying infrastructure and algorithms, as they are managed by the service provider.
Its advanced algorithms and artificial intelligence will analyze your emails and prioritize them accordingly. Instead, it uses advanced algorithms to analyze email metadata for efficient sorting. Finally, Sanebox will ask if you want to turn on SaneReminders if you ever want to deal with an email at a later time.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content