This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
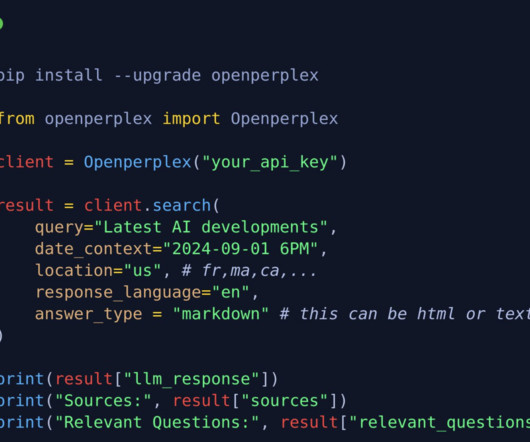
A powerful feature of Grok-3 is its integration with Deep Search, a next-generation AI-powered search engine. By utilizing advanced algorithms, Deep Search quickly processes vast amounts of data to deliver relevant information in seconds.
Ensuring consistent access to a single inferenceengine or database connection. Strategy Pattern The Strategy Pattern defines a family of interchangeable algorithms, encapsulating each one and allowing the behavior to change dynamically at runtime. retraining models, swapping algorithms). model hyperparameters).
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google AI Researchers Propose ‘MODEL SWARMS’: A Collaborative Search Algorithm to Flexibly Adapt Diverse LLM Experts to Wide-Ranging Purposes appeared first on MarkTechPost.
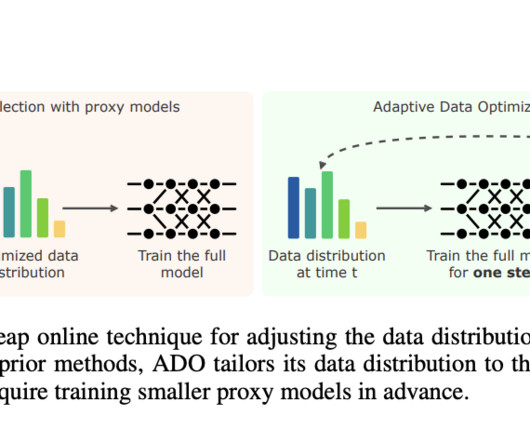
ADO is an online algorithm that does not require smaller proxy models or additional external data. Researchers from Carnegie Mellon University, Stanford University, and Princeton University introduced Adaptive Data Optimization (ADO) , a novel method that dynamically adjusts data distributions during training.
The hierarchical structure of these ideas is essential for creating algorithms that are both effective and simple to comprehend. To create retrieval algorithms that are effective and simple to understand, the system arranges prompts and their answers into a layered, hierarchical structure. Don’t Forget to join our 55k+ ML SubReddit.
The Together InferenceEngine, capable of processing over 400 tokens per second on Meta Llama 3 8B, integrates the latest innovations from Together AI, including FlashAttention-3, faster GEMM and MHA kernels, and quality-preserving quantization, as well as speculative decoding techniques.
While existing search engines have made strides in improving search results, they still have significant limitations. Most rely on keyword-based searches and ranking algorithms that may not fully understand the context of the query. It also uses a reranking system to refine the results based on relevance.
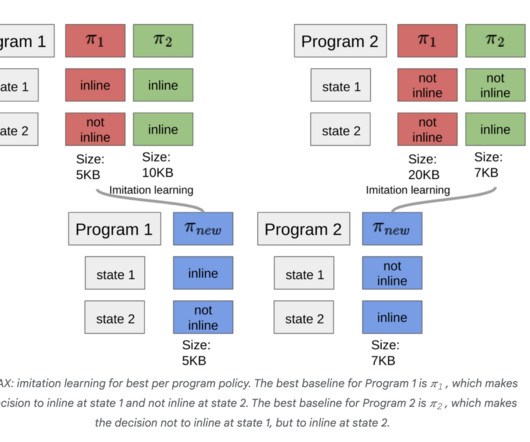
Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. In this, the limitation learning algorithm combines trajectories to learn a new policy.
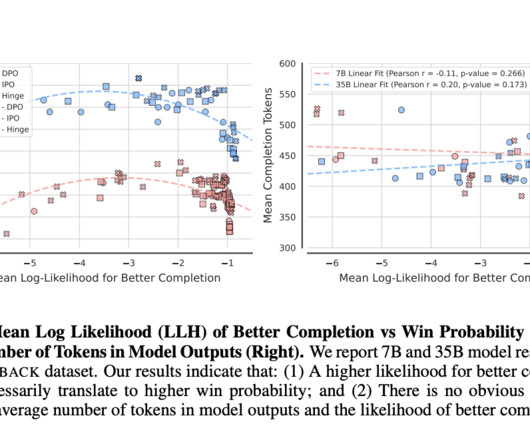
The problem of over-optimization of likelihood in Direct Alignment Algorithms (DAAs), such as Direct Preference Optimisation (DPO) and Identity Preference Optimisation (IPO), arises when these methods fail to improve model performance despite increasing the likelihood of preferred outcomes. If you like our work, you will love our newsletter.
ML algorithms learn from data to improve over time, while DL uses neural networks to handle large, complex datasets. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems. AI, particularly through ML and DL, has advanced medical applications by automating complex tasks.
Several search engines have attempted to improve the relevance of search results by integrating advanced algorithms and machine learning models. Additionally, many of these search engines are not open-source, limiting the ability for broader community involvement and innovation.
This involves tweaking algorithms, fine-tuning models, and using tools and frameworks that support cross-platform compatibility. Language Processing Units (LPUs): The Language Processing Unit (LPU) is a custom inferenceengine developed by Groq, specifically optimized for large language models (LLMs).
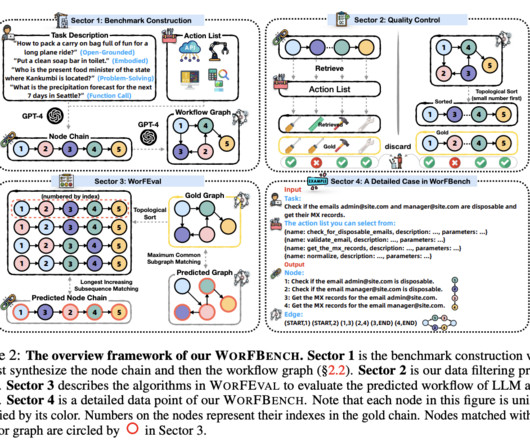
Further, researchers presented WORFEVAL, a systematic evaluation protocol utilizing advanced subsequence and subgraph matching algorithms to evaluate chain and graph structure workflow generation. In conclusion, researchers introduced WORFBENCH, a method to evaluate workflow generation capabilities in LLM agents.
Evaluating the performance of quantum computers has been a challenging task due to their sensitivity to noise, the complexity of quantum algorithms, and the limited availability of powerful quantum hardware. Decoherence and errors introduced by noise can significantly affect the accuracy of quantum computations.
These differences make it challenging to directly relate visual perception to action control, requiring intermediate representations or learning algorithms to bridge the gap. Currently, robots are represented by geometric primitives like triangle meshes, and kinematic structures describe their morphology.
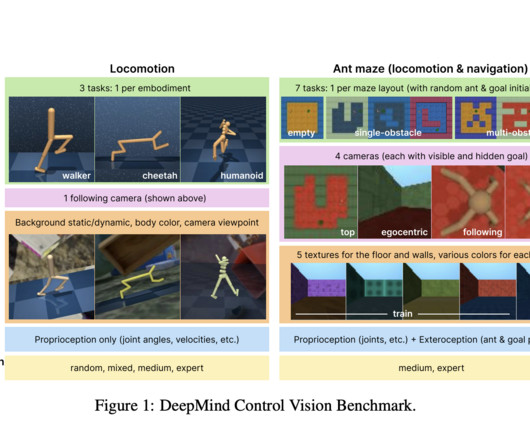
Online RL algorithms iteratively take actions, collecting observations and rewards from the environment, and then update their policy using the latest experience. a) It contains a diversity of tasks including tasks where state-of-the-art algorithms struggle to drive the development of novel algorithms. (b)
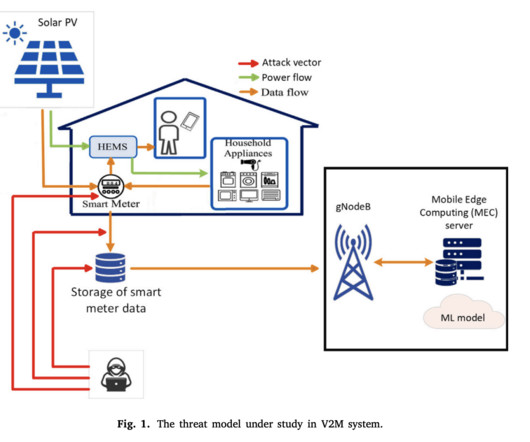
However, adversarial attacks on AI algorithms can manipulate energy flows, disrupting the balance between vehicles and the grid and potentially compromising user privacy by exposing sensitive data like vehicle usage patterns. However, using Conditional GAN for data augmentation significantly reduces DBSCAN’s effectiveness.
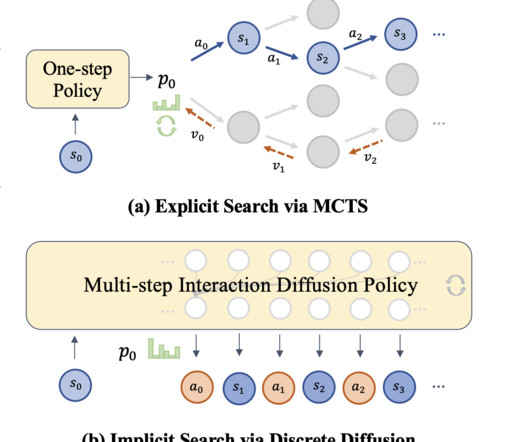
While explicit search methods like Monte Carlo Tree Search (MCTS) have been employed to enhance decision-making in various AI systems, including chess engines and game-playing algorithms, they present challenges when applied to LLMs. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
Optimization-based attacks use automatic algorithms to generate jailbreak prompts based on feedback, such as loss function gradients or by training generators to imitate optimization algorithms. Existing jailbreak attempts primarily follow two methodological approaches: optimization-based and strategy-based attacks.
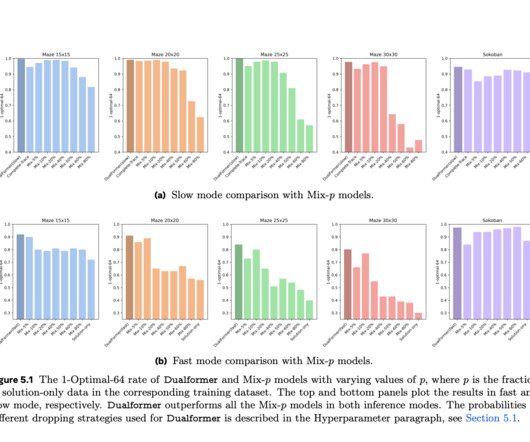
Thus, one can conduct training for such a strategy on complex tasks like maze navigation or Sokoban games using traces generated by the A* search algorithm. The model constructed is based on a systematic trace-dropping method where the traces of reasoning are progressively pruned over the training process to instill efficiency.
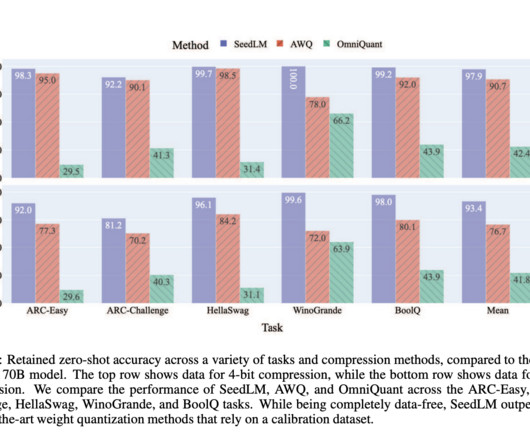
By eliminating the need for calibration data and relying on deterministic offline algorithms, SeedLM simplifies the compression process while retaining high accuracy levels. The FPGA implementation further emphasizes its potential in real-world applications, providing up to a 4x speed-up in memory-bound tasks.
Frequently, Python code invokes C++ methods for intricate algorithmic calculations. However, I encountered an opposite scenario where my Machine Learning application urgently required invoking a custom model with Python-based inference code. My initial thought was simple: “Calling Python from C++ should be a breeze.”
These approaches typically involve training reward models on human preference data and using algorithms like Proximal Policy Optimization (PPO) or Direct Policy Optimization (DPO) for policy learning. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
Similarly, HumanEval and MBPP evaluate code generation only in basic, algorithmic tasks, failing to reflect the complexity of real-world AI development. Benchmarks like SWE-Bench, for example, focus on the success rate of final solutions in long-term automated tasks but offer little insight into the performance of intermediate steps.
The regular expression, LLM decision rules, and the traversal algorithm are all stored in the Query Object. A regular expression inferenceengine that effectively converts regular expressions to finite automata has been designed and implemented. They are the first group to use automata to accommodate these variant encodings.
FlashAttention, on the other hand, is a precise attention algorithm that considers hardware configurations to achieve better performance. Reformer uses a sparse approximation to reduce computing cost, while other works use low-rank or a combination of approximation techniques.
Rigorous testing was done on a wide range of problems that involved algorithmic challenges to real-world applications. Further experiments conducted on various LLMs revealed 25% logic errors that were missed by the conventional unit tests. Multiple code generation models were used for assessing the robustness of the model.
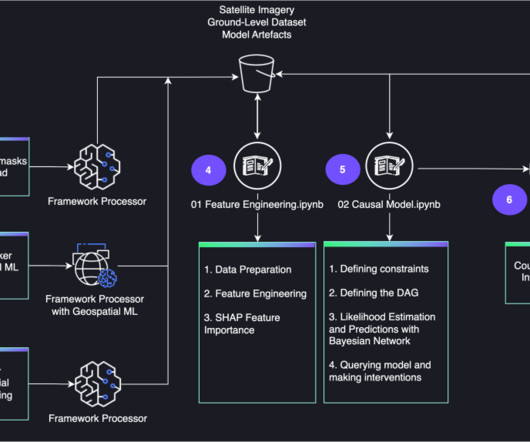
The causal inferenceengine is deployed with Amazon SageMaker Asynchronous Inference. SageMaker Asynchronous Inference allows queuing incoming requests and processes them asynchronously. In this post, we demonstrate how to create this counterfactual analysis using Amazon SageMaker JumpStart solutions.
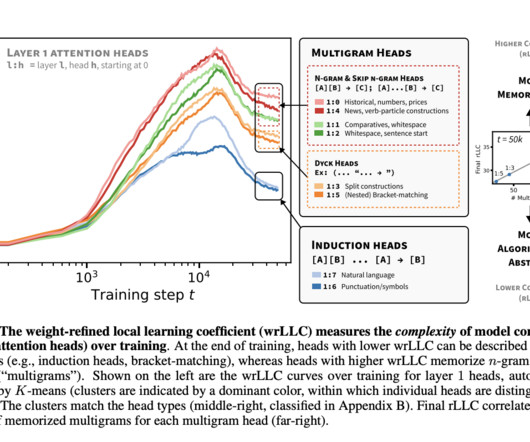
These include techniques like ablation studies, where specific model components are disabled to observe their role, and clustering algorithms, which group similar components based on their behavior. Several tools have been developed to study how neural networks operate. If you like our work, you will love our newsletter.
In order to tackle this, the team at Modular developed a modular inferenceengine. Designed by Canva Have you guys ever heard of Modular? This highly complex and fragmented ecosystem is hampering the AI innovation, and is pulling back the AI community, as a whole. Read more about it here.
In coding tasks, the o1 model was evaluated using the USACO dataset, a benchmark that tests the model’s algorithmic and problem-solving skills. This approach contrasted with models like GPT-4o, which relied more heavily on scaling parameters but needed help with multi-step reasoning tasks that required a more structured approach.
TensorFlow: TensorFlow is an open source library for building neural networks and other deep learning algorithms on top of GPUs. It offers various data type conversions and aggregations as well as powerful plotting capabilities.
gemma.cpp is a lightweight, standalone C++ inferenceengine for the Gemma foundation models from Google. Massachusetts-based Overjet , an AI-powered dental technology company that provides algorithms to analyze dental images and deliver diagnoses raised over $130M from private investors. raised $600M from private investors.
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Overall, TensorRT’s combination of techniques results in faster inference and lower latency compared to other inferenceengines.
Once the model is trained we test the model on sample images or videos Inference Running inference using Monk is even simpler ★ Step-1 — Import and initiate the InferenceEngine ★ Step-2 — Load the trained Model ★ Step-3— Run inference on image The final output can be displayed in the jupyter notebook in this manner!!
With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance. Because XGBoost is a memory-intensive algorithm, we provide ml.m5 type instances to get instance type recommendations. large", "ml.m5.xlarge",
The team had to carefully tune their algorithms and leverage hierarchical communication patterns to maintain efficiency. Numerical stability: At such large scales, ensuring numerical stability of the training process became more challenging, potentially requiring adjustments to the optimization algorithm or learning rate schedules.
As discussed in our previous blog post , GPU-accelerated ML inference is often limited by memory performance, and execution of LDMs is no exception. Ultimately, our primary objective is to reduce the overall latency of the ML inference.
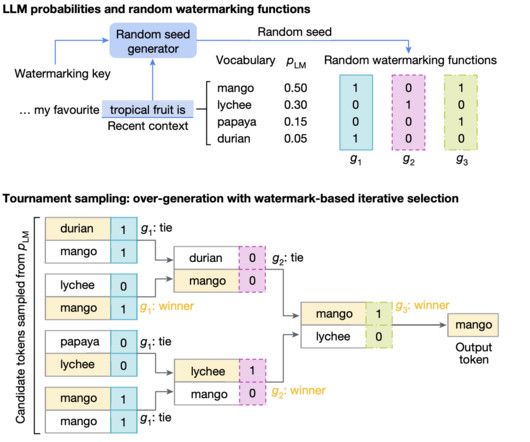
Moreover, the integration of a novel sampling algorithm called Tournament sampling within SynthID-Text has enhanced detection performance by embedding statistical signatures that are challenging to remove. The results are promising: during testing, SynthID identified watermarked text with an accuracy rate exceeding 95%.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. DeepSparse: a CPU inferenceengine for sparse models. Follow their code on GitHub. SparseZoo: a model repo for sparse models.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. DeepSparse: a CPU inferenceengine for sparse models. Follow their code on GitHub. SparseZoo: a model repo for sparse models.
Invariant learning approaches enhance robustness to distributional changes by enforcing that models remain consistent across environments; however, in cases without predefined environments, data subsets can be created to challenge invariant constraints, using algorithms like groupDRO to improve distributional robustness.
In addition, I link philosophical reasoning to conceptual/qualitative/non-paradigmatic research, arguing that they’re implemented using the same cognitive algorithms. One of these steps consists of relating empirical evidence to theoretical and decision-relevant propositions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content