This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process begins with data ingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback. It organizes it by filtering out irrelevant details and ensuring dataquality. Another key issue is bias within AI algorithms.
Why It Matters As AI takes on more prominent roles in decision-making, data monocultures can have real-world consequences. AI models can reinforce discrimination when they inherit biases from their training data. Data monoculture can lead to ethical and legal issues as well. Cultural representation is another challenge.
The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. No matter how advanced an algorithm is, noisy, biased, or insufficient data can bottleneck its potential.
Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets. Companies have struggled with dataquality and data hygiene.
. “Our AI engineers built a prompt evaluation pipeline that seamlessly considers cost, processing time, semantic similarity, and the likelihood of hallucinations,” Ros explained. It’s obviously an ambitious goal, but it’s important to our employees and it’s important to our clients,” explained Ros.
From technical limitations to dataquality and ethical concerns, it’s clear that the journey ahead is still full of obstacles. Another challenge is the data itself. AI algorithms depend on massive datasets for training, and while the pharmaceutical industry has plenty of data, it’s often noisy, incomplete, or biased.
The Role of Explainable AI in In Vitro Diagnostics Under European Regulations: AI is increasingly critical in healthcare, especially in vitro diagnostics (IVD). The European IVDR recognizes software, including AI and ML algorithms, as part of IVDs. This includes considering patient population, disease conditions, and scanning quality.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
Some rely on machine learning algorithms, while others use rule-based systems or statistical methods. The tool employs advanced algorithms to deliver precision hallucination detection. Key features of Cleanlab include: Cleanlab's AI algorithms can automatically identify label errors, outliers, and near-duplicates.
It covers the concept of embedding, its importance for machine learning algorithms, and how it is used in LangChain for various applications. It covers key considerations like balancing dataquality versus quantity, ensuring data diversity, and selecting the right tuning method.
Introduction: The Reality of Machine Learning Consider a healthcare organisation that implemented a Machine Learning model to predict patient outcomes based on historical data. However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases.
The wide availability of affordable, highly effective predictive and generative AI has addressed the next level of more complex business problems requiring specialized domain expertise, enterprise-class security, and the ability to integrate diverse data sources.
Technological risk—security AI algorithms are the parameters that optimizes the training data that gives the AI its ability to give insights. Should the parameters of an algorithm be leaked, a third party may be able to copy the model, causing economic and intellectual property loss to the owner of the model.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party big data sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Headquartered in Oregon, the company is at the forefront of transforming how healthcare data is shared, monetized, and applied, enabling secure collaboration between data custodians and data consumers. Can you explain how datma.FED utilizes AI to revolutionize healthcare data sharing and analysis?
For now, we consider eight key dimensions of responsible AI: Fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. This includes handling unexpected inputs, adversarial manipulations, and varying dataquality without significant degradation in performance.
These preferences are then used to train a reward model , which predicts the quality of new outputs. Finally, the reward model guides the LLMs behavior using reinforcement learning algorithms, such as Proximal Policy Optimization (PPO). Dataquality dependency: Success depends heavily on having high-quality preference data.
However, this progress has limitations and challenges, including dataquality , algorithm robustness, explainability , and scalability. Another example of AI optimism is Netflix , a prominent streaming service that uses AI algorithms to optimize content delivery.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. You can review the recommendations and augment rules from over 25 included dataquality rules.
However, with the emergence of Machine Learning algorithms, the retail industry has seen a revolutionary shift in demand forecasting capabilities. This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Ongoing Challenges: – Design Complexity: Designing and training these complex networks remains a hurdle due to their intricate architectures and the need for specialized algorithms.– These chips have demonstrated the ability to process complex algorithms using a fraction of the energy required by traditional GPUs.–
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
The Evolution of AI Agents Transition from Rule-Based Systems Early software systems relied on rule-based algorithms that worked well in controlled, predictable environments. This use of AI helps clinicians by providing data-driven insights that complement their expertise. This makes them effective for straightforward, real-time tasks.
Extensions to the base DQN algorithm, like Double Q Learning and Prioritized replay, enhance its performance, offering promising avenues for autonomous driving applications. DRL models, such as Deep Q-Networks (DQN), estimate optimal action policies by training neural networks to approximate the maximum expected future rewards.
This foundational step requires clean and well-structured data to facilitate accurate model training. Techniques such as parallel data loading, data augmentation , and feature engineering are pivotal in enhancing dataquality and richness. A primary concern is bias and fairness in algorithmic decision-making.
To explain this limitation, it is important to understand that the chemistry of sensory-based products is largely focused on quality control, i.e., how much of this analyte is in that mixture? When it comes to dataquality, we realized a valid training set could not be generated from existing commercial or crowd-sourced data.
The “distance” between each pair of neighbors can be interpreted as a probability.When a question prompt arrives, run graph algorithms to traverse this probabilistic graph, then feed a ranked index of the collected chunks to LLM. One way to build a graph to use is to connect each text chunk in the vector store with its neighbors.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online. Models […]
Machine learning algorithms can analyze vast amounts of transaction data in real-time, identifying patterns and anomalies that might indicate fraudulent activity. Algorithms can analyze market data, news sentiment, and social media trends to predict stock prices and optimize portfolio allocation.
Apache Superset remains popular thanks to how well it gives you control over your data. Algorithm-visualizer GitHub | Website Algorithm Visualizer is an interactive online platform that visualizes algorithms from code. The no-code visualization builds are a handy feature.
So far, LLM capability improvements have been relatively predictable with compute and training data scaling — and this likely gives confidence to plan projects on this $100bn scale. This can come from algorithmic improvements and more focus on pretraining dataquality, such as the new open-source DBRX model from Databricks.
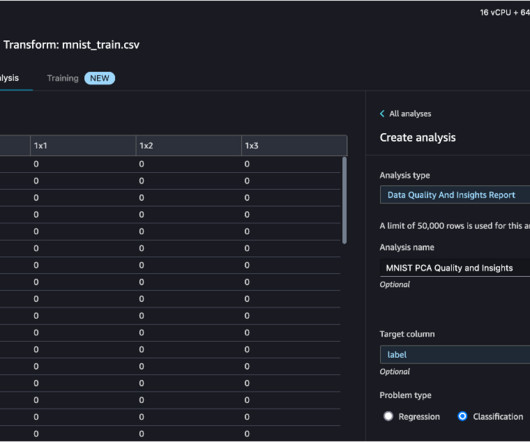
Today, we’re excited to add a new transformation technique that is commonly used in the ML world to the list of Data Wrangler pre-built transformations: dimensionality reduction using Principal Component Analysis. In this post, we provide an overview of this new feature and show how to use it in your data transformation. Choose Create.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
Some of our most popular in-person sessions were: MLOps: Monitoring and Managing Drift: Oliver Zeigermann | Machine Learning Architect ODSC Keynote: Human-Centered AI: Peter Norvig, PhD | Engineering Director, Education Fellow | Google, Stanford Institute for Human-Centered Artificial Intelligence (HAI) The Cost of AI Compute and Why AI Clouds Will (..)
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and data science experience who wanted to implement MLOps. All looks good, but the (numerical) result is clearly incorrect.
There are only 0.12% of anomalous images in the entire data set (i.e., Finally, there is no labeled data available for training a supervised machine learning model. Next, we describe how we address these challenges and explain our proposed method. First, we will describe the steps involved in the data processing pipeline.
These preferences are then used to train a reward model , which predicts the quality of new outputs. Finally, the reward model guides the LLMs behavior using reinforcement learning algorithms, such as Proximal Policy Optimization (PPO). Dataquality dependency: Success depends heavily on having high-quality preference data.
In parallel, data selection methods, such as ChatGPT-based scoring and gradient-based clustering, have been explored to refine instruction tuning. Researchers at Meta GenAI introduce a diversity-aware data selection strategy using SAEs to improve instruction tuning.
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. We explain the metrics and show techniques to deal with data to obtain better model performance. Confusion matrix SageMaker Canvas uses confusion matrices to help you visualize when a model generates predictions correctly.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
From high-qualitydata to robust algorithms and infrastructure, each component is critical in ensuring AI delivers accurate and impactful results. DataData is the lifeblood of AI systems. The quality, quantity, and diversity of datasets directly influence the accuracy of AI models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







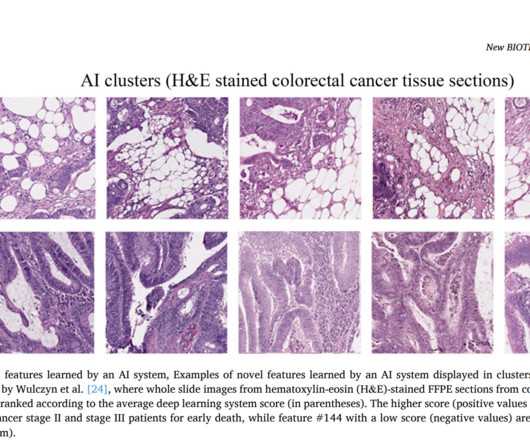















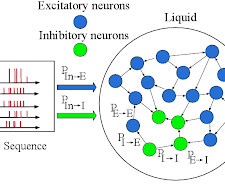




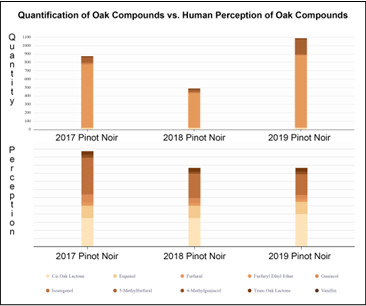

















Let's personalize your content