This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. And then I found certain areas in computer science very attractive such as the way algorithms work, advanced algorithms. What initially attracted you to computer science?
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
The humble beginnings with Iris In 2017, SnapLogic unveiled Iris, an industry-first AI-powered integration assistant. Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. We use the following prompt: Human: Your job is to act as an expert on ETL pipelines.
DATALORE uses Large Language Models (LLMs) to reduce semantic ambiguity and manual work as a data transformation synthesis tool. Second, for each provided base table T, the researchers use data discovery algorithms to find possible related candidate tables. These models have been trained on billions of lines of code.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. The following blog will provide you with complete information and in-depth understanding on what is data profiling and its benefits and the various tools used in the method.
The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions. DataIntegration Once data is collected from various sources, it needs to be integrated into a cohesive format. What Are Some Common Tools Used in Business Intelligence Architecture?
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
It relates to employing algorithms to find and examine data patterns to forecast future events. Through practice, machines pick up information or skills (or data). Algorithms and models Predictive analytics uses several methods from fields like machine learning, data mining, statistics, analysis, and modeling.
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. Hevo automatically detects and duplicates the schema at the data destination.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, dataintegration, data modelling, analysis of information, and data visualization are all part of intelligence for businesses.
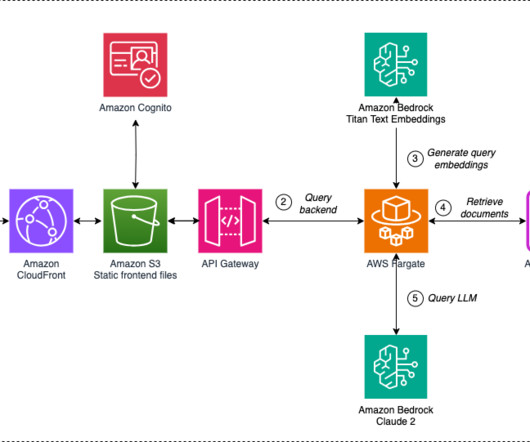
Generative AI empowers organizations to combine their data with the power of machine learning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. The following diagram illustrates this architecture.
The primary functions of BI tools include: Data Collection: Gathering data from multiple sources including internal databases, external APIs, and cloud services. Data Processing: Cleaning and organizing data for analysis. Data Analysis : Utilizing statistical methods and algorithms to identify trends and patterns.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
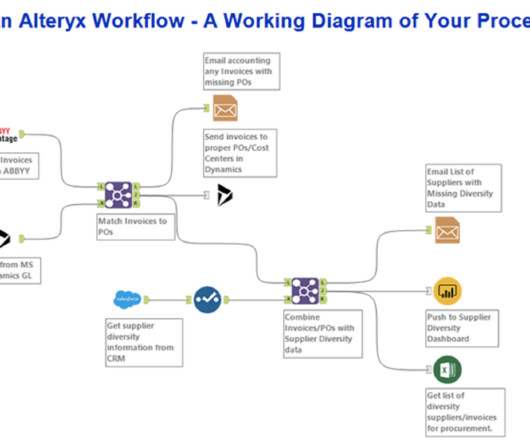
Alteryx’s Capabilities Data Blending: Effortlessly combine data from multiple sources. Predictive Analytics: Leverage machine learning algorithms for accurate predictions. This makes Alteryx an indispensable tool for businesses aiming to glean insights and steer their decisions based on robust data.
Students should learn about the architecture of data warehouses and how they differ from traditional databases. DataIntegration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis.
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated DataIntegration and ETL Tools The rise of no-code and low-code tools is transforming dataintegration and Extract, Transform, and Load (ETL) processes.
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity.
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
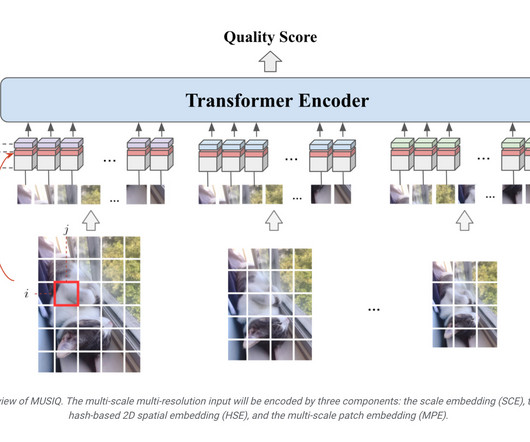
The one of the main shortcomings of NIMA was that the input image had to be resized and that created a challenge of the benchmark and algorithm itself in a real life datasets where the input images might have a varying sizes. MUSIQ accommodates this shortcoming by using multi-scale input images so that the algorithm is scale-invariant.
This pre-aggregation allows OLAP systems to quickly return results for complex queries, making them highly effective for interactive data exploration and analysis. The 1990s also saw the rise of data mining, the process of discovering patterns and knowledge from large amounts of data. Morgan Kaufmann. Morgan Kaufmann.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content