This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
Table: Research Phase vs Production Phase Datasets The contrast highlights the “production data” we’ll call “data” in this post. Data is a key differentiator in ML projects (more on this in my blog post below). We don’t have better algorithms; we just have more data. It involves the following core operations: 1.
Using recipes (algorithms prepared for specific uses cases) provided by Amazon Personalize, you can offer diverse personalization experiences like “recommend for you”, “frequently bought together”, guidance on next best actions, and targeted marketing campaigns with user segmentation. You can also use this for sequential chains.
Amazon Forecast is an ML-based time series forecasting service that includes algorithms that are based on over 20 years of forecasting experience used by Amazon.com , bringing the same technology used at Amazon to developers as a fully managed service, removing the need to manage resources. For more details, refer to Importing Datasets.
A feature store maintains user profile data. A media metadata store keeps the promotion movie list up to date. A language model takes the current movie list and user profile data, and outputs the top three recommended movies for each user, written in their preferred tone. This can be done with algorithms like XGBoost.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. Lastly, we cover the dataingestion by an intelligent search service, powered by ML. join(", "), }; }).catch((error)
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library.
In this session, you will learn how explainability can help you identify poor model performance or bias, as well as discuss the most commonly used algorithms, how they work, and how to get started using them. What techniques are there and how do they work?
Amazon Personalize offers a variety of recommendation recipes (algorithms), such as the User Personalization and Trending Now recipes, which are particularly suitable for training news recommender models. In this solution, you can also ingest certain items and interactions data attributes into Amazon DynamoDB.
This track is designed to help practitioners strengthen their ML foundations while exploring advanced algorithms and deployment techniques. Data Engineering TrackBuild the Data Foundation forAI Data engineering powers every AI system.
The recent strides made in the field of machine learning have given us an array of powerful language models and algorithms. During training, we log all the model metrics and metadata automatically. These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Ensure that everyone handling data understands its importance and the role it plays in maintaining data quality. Data Documentation Comprehensive data documentation is essential. Create data dictionaries and metadata repositories to help users understand the data’s structure and context.
Model management Teams typically manage their models, including versioning and metadata. Optimization: Use database optimizations like approximate nearest neighbor ( ANN ) search algorithms to balance speed and accuracy in retrieval tasks. Develop the text preprocessing pipeline Dataingestion: Use Unstructured.io
Elements of a machine learning pipeline Some pipelines will provide high-level abstractions for these components through three elements: Transformer : an algorithm able to transform one dataset into another. Estimator : an algorithm trained on a dataset to produce a transformer. Data preprocessing. CSV, Parquet, etc.)
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. Parallelism is suited for workloads that are repetitive, fixed tasks, involving little conditional branching and often large amounts of data.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
The core challenge lies in developing data pipelines that can handle diverse data sources, the multitude of data entities in each data source, their metadata and access control information, while maintaining accuracy. As a result, they can index one time and reuse that indexed content across use cases.
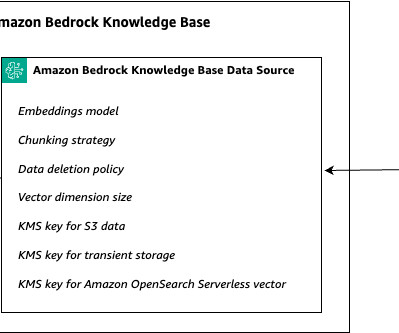
In the context of RAG systems, tenants might have varying requirements for dataingestion frequency, document chunking strategy, or vector search configuration. You can also choose the specific settings for the HNSW algorithm per tenant to control memory consumption, cost, and indexing time.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. These identifiers can be used to uniquely reference and retrieve specific documents from the vector data store.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content