This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
By leveraging machine learning algorithms, companies can prioritize leads, schedule follow-ups, and handle customer service queries accurately. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics. Enhanced Analytics AI in CRM platforms can take analytics to new heights.
Prescriptive AI relies on several essential components that work together to turn raw data into actionable recommendations. The process begins with dataingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback.
Drasi's Real-Time Data Processing Architecture Drasi’s design is centred around an advanced, modular architecture, prioritizing scalability, speed, and real-time operation. Maily, it depends on continuous dataingestion , persistent monitoring, and automated response mechanisms to ensure immediate action on data changes.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
GPUs (graphics processing units) and TPUs (tensor processing units) are specifically designed to handle complex mathematical computations central to AI algorithms, offering significant speedups compared with traditional CPUs. Additionally, using in-memory databases and caching mechanisms minimizes latency and improves data access speeds.
cuDF helps optimize content delivery by analyzing user data to predict demand and adjust content distribution in real time, improving overall user experiences. Professionals can benefit from high-quality video playback, accelerate video dataingestion and use advanced AI-powered video editing features. 264 and HEVC decode.
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
For time-series forecasting use cases, SageMaker Canvas uses autoML to train six algorithms on your historical time-series dataset and combines them using a stacking ensemble method to create an optimal forecasting model. To learn more about the modalities that Amazon SageMaker Canvas supports, visit the Amazon SageMaker Canvas product page.
Table: Research Phase vs Production Phase Datasets The contrast highlights the “production data” we’ll call “data” in this post. Data is a key differentiator in ML projects (more on this in my blog post below). We don’t have better algorithms; we just have more data. It involves the following core operations: 1.
enhances data management through automated insights generation, self-tuning performance optimization and predictive analytics. It leverages machine learning algorithms to continuously learn and adapt to workload patterns, delivering superior performance and reducing administrative efforts.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
Typically, dense vector embeddings and similarity search algorithms (e.g., However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. document retrieval). What Is ColPali? ColPali ( Faysse et al.,
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm. Large language models (LLMs) have taken the field of AI by storm.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. The retrieved vectors augment the initial query with context-specific enterprise data, enhancing its relevance.
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. A very common pattern for building machine learning infrastructure is to ingestdata via Kafka into a data lake.
Unlike traditional medical algorithms, which are often geared toward standard diagnostics and treatments, functional medicine requires nuanced, personalized interventions to optimize patient outcomes. However, the complexity and scale of data present significant challenges in processing, accuracy, and can stymie decisionmaking.
Data sources, embeddings, and vector store Organizations domain-specific data, which provides context and relevance, typically resides in internal databases, data lakes, unstructured data repositories, or document stores, collectively referred to as organizational data sources or proprietary data stores.
It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning. As datasets grow, scalable dataingestion and storage become critical.
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library.
In this session, you will learn how explainability can help you identify poor model performance or bias, as well as discuss the most commonly used algorithms, how they work, and how to get started using them. What techniques are there and how do they work?
Using recipes (algorithms prepared for specific uses cases) provided by Amazon Personalize, you can offer diverse personalization experiences like “recommend for you”, “frequently bought together”, guidance on next best actions, and targeted marketing campaigns with user segmentation.
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas , organizations can overcome these challenges and unlock new levels of agility.
Amazon Forecast is an ML-based time series forecasting service that includes algorithms that are based on over 20 years of forecasting experience used by Amazon.com , bringing the same technology used at Amazon to developers as a fully managed service, removing the need to manage resources.
To simplify, you can build a regression algorithm using a user’s previous ratings across different categories to infer their overall preferences. This can be done with algorithms like XGBoost. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds.
SageMaker enables Marubeni to run ML and numerical optimization algorithms in a single environment. Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting. Amazon EventBridge to trigger the dataingestion and ML pipeline on a schedule and in response to events.
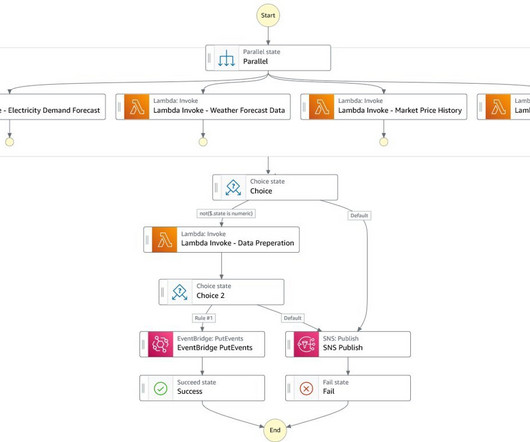
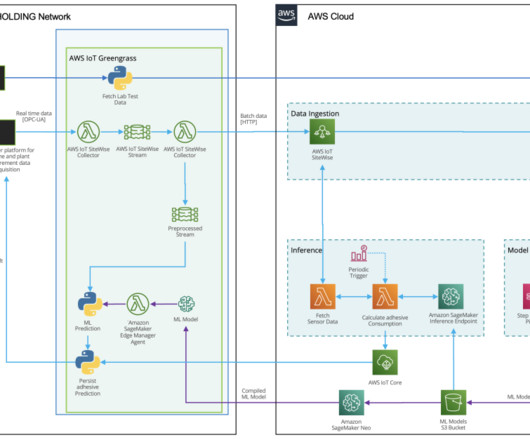
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. Setting up and managing custom ML environments can be time-consuming and cumbersome.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index.
Data engineering – Identifies the data sources, sets up dataingestion and pipelines, and prepares data using Data Wrangler. Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation.
This track is designed to help practitioners strengthen their ML foundations while exploring advanced algorithms and deployment techniques. Data Engineering TrackBuild the Data Foundation forAI Data engineering powers every AI system.
The recent strides made in the field of machine learning have given us an array of powerful language models and algorithms. These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects.
Amazon Personalize offers a variety of recommendation recipes (algorithms), such as the User Personalization and Trending Now recipes, which are particularly suitable for training news recommender models. We discuss more about how to use items and interactions data attributes in DynamoDB later in this post.
Clustering Algorithms Techniques such as K-means clustering can help identify groups of similar data points. Isolation Forest This algorithm isolates anomalies by randomly partitioning the data. For instance, adjusting algorithms to account for anomalies can enhance forecasting accuracy.
By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. Lastly, we cover the dataingestion by an intelligent search service, powered by ML.
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. Parallelism is suited for workloads that are repetitive, fixed tasks, involving little conditional branching and often large amounts of data.
Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes. Enhance IDP with Amazon Comprehend Flywheel and Amazon Textract Custom Queries Leverage the Amazon Comprehend flywheel for a streamlined ML process, from dataingestion to deployment.
Advanced ranking algorithms can refine this process by incorporating user preferences or domain-specific features. These databases use optimised algorithms like k-nearest neighbours (k-NN) and Approximate Nearest Neighbors (ANN) to quickly identify the most relevant results based on cosine similarity or other distance metrics.
In this workshop, you’ll explore no-code and low-code frameworks, how they are used in the ML workflow, how they can be used for dataingestion and analysis, and how they can be used for building, training, and deploying ML models.
Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Answer : Data Masking features available in Azure include Azure SQL Database masking, Dynamic data masking, Azure Data Factory masking, Azure Data Share Masking, and Azure Synapse Analytics masking.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Collaborating with Teams: Working with data engineers, analysts, and stakeholders to ensure data solutions meet business needs.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content