This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Algorithmic trading is a widely adopted trading strategy that has revolutionized the way people trade stocks. More and more people are making money on the side by investing in stocks and automating their trading strategies.
Algorithms, which are the foundation for AI, were first developed in the 1940s, laying the groundwork for machine learning and data analysis. Most consumers trust Google to deliver accurate answers to countless questions, they rarely consider the complex processes and algorithms behind how those results appear on their computer screen.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Unlike traditional document systems, IDP can handle unstructured and semi-structured data for multiple healthcare documents, which can exist in various forms. Thus, it reduces the human factor and enhance performance, Establishing more accurate data With AI algorithms.
Imagine running powerful AI algorithms directly within your own infrastructure, with no detours through external servers and no compromises on privacy. Thats the core appeal of on-prem AIit puts your data, performance, and decision-making firmly in your hands. The Hybrid Model: A Practical Middle Ground?
Introduction to Data Engineering In recent days the consignment of data produced from innumerable sources is drastically increasing day-to-day. So, processing and storing of these data has also become highly strenuous. The post Data Engineering – A Journal with Pragmatic Blueprint appeared first on Analytics Vidhya.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. It allows for the interpretation of reviews and dataextraction without needing large amounts of labeled datasets.
One of the most practical use cases of AI today is its ability to automate data standardization, enrichment, and validation processes to ensure accuracy and consistency across multiple channels. Leveraging customer data in this way allows AI algorithms to make broader connections across customer order history, preferences, etc.,
sciencedaily.com Screening Mammography and Artificial Intelligence: A Comprehensive Systematic Review A total of 13 studies were analyzed, with dataextracted on study characteristics, population demographics, artificial intelligence algorithms, and key outcomes.
Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. Generative AI refers to algorithms, particularly those built on models like GPT-4, that can generate new content. What is Generative AI? For more information.
This is also a critical differentiator between hyperpersonalization and personalization – the depth and timing of the data used. While personalization uses historical data such as customers’ purchase history, hyperpersonalization uses real-time dataextracted throughout the customer journey to learn their behavior and needs.
Using AI algorithms and machine learning models, businesses can sift through big data, extract valuable insights, and tailor. It included calls for “safe and effective systems,” “algorithmic discrimination protections,” and requiring a notice for when an automated system is being used. decrypt.co
What are some of the different machine learning algorithms that are used by SmartSense? We obviously leverage a lot of technical machine learning components, but I view the real ML algorithm as the customer benefits of our open platform. In data science, degradation in temperature is reflected through derivatives.
By leveraging the transition from pretrained DM distributions to fine-tuning data distributions, FineXtract accurately guides the generation process toward high-probability regions of the fine-tuned data distribution, enabling successful dataextraction.' Second from right, the image extracted via FineXtract.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. And then I found certain areas in computer science very attractive such as the way algorithms work, advanced algorithms. So that's how I got my undergraduate education.
Parsio (OCR + AI chat) Enhance your dataextraction process by adopting an AI-driven document parser. Enhance your dataextraction routines with our state-of-the-art AI-based PDF parser. Bid farewell to labor-intensive data entry, and embrace seamless, automatic dataextraction with this advanced technology.
DataExtraction This project explores how data from Reddit, a widely used platform for discussions and content sharing, can be utilized to analyze global sentiment trends.
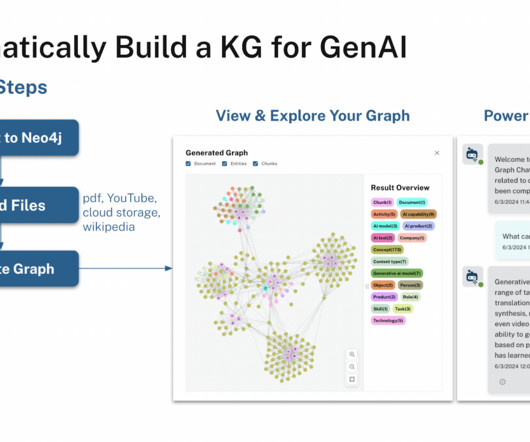
The program works well with long-form English text, but it does not work as well with tabular data, such as that found in Excel or CSV files or images that include presentations or diagrams. After building the knowledge graph, users can query their data using several Retrieval-Augmented Generation (RAG) techniques.
As it pertains to social media data, text mining algorithms (and by extension, text analysis) allow businesses to extract, analyze and interpret linguistic data from comments, posts, customer reviews and other text on social media platforms and leverage those data sources to improve products, services and processes.
Pre-processing is crucial for translating 3-D data from LC-MS into a 2D aligned peak table, which is necessary for downstream analysis. Algorithms like XCMS, MZmine, and MS-Dial are used for pre-processing, but only some methods are universally accepted.
Posted by Haim Kaplan and Yishay Mansour, Research Scientists, Google Research Differential privacy (DP) machine learning algorithms protect user data by limiting the effect of each data point on an aggregated output with a mathematical guarantee. not necessarily in the data). are both close to a third point ?
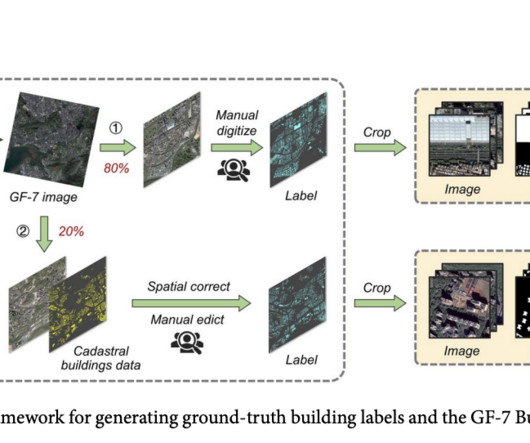
In urban development and environmental studies, accurate and efficient building dataextraction from satellite imagery is a cornerstone for myriad applications. The introduction of the GF-7 Building dataset is timely, aligning with the increasing reliance on deep learning in building extraction tasks.
The important information from an invoice may be extracted without resorting to templates or memorization, thanks to the hundreds of millions of invoices used to train the algorithms. Even on day one of operation, their algorithms produce near-perfect header results, and their technology is always evolving.
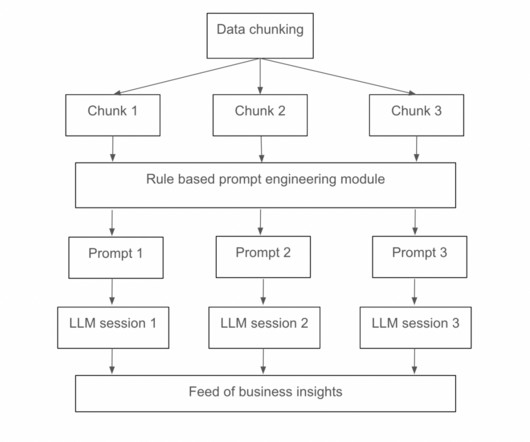
The hybrid model enhances transparency and trustworthiness in dataextraction processes, as stakeholders can easily understand and validate the generated insights. For instance, rule-based preprocessing algorithms improved processing efficiency to 100% compared to 63% for standalone LLMs, with a hybrid approach achieving 87%.
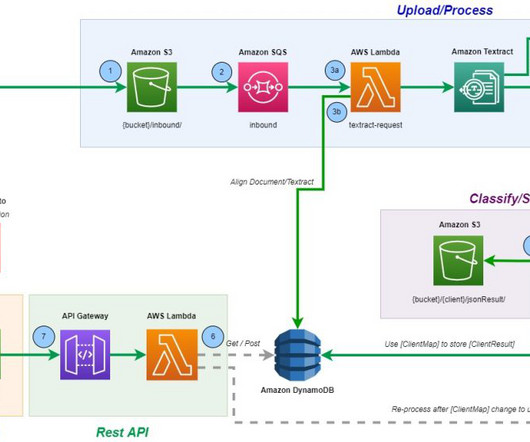
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas , organizations can overcome these challenges and unlock new levels of agility. The following diagram outlines the proposed solution architecture. Note we have two folders.
As the demand grows, efficiently extracting key information from seller ads becomes crucial. However, for beginners in machine learning, diving into complex algorithms and coding might seem intimidating. In this guide, I will walk you through a beginner-friendly solution: Azure Cognitive Service Language Studio. Happy analyzing!
He joined the company as a software developer in 2004 after studying computer science with a heavy focus on databases, distributed systems, software development processes, and genetic algorithms. You have a strong background in databases, distributed systems, and genetic algorithms. In 2014, Mathias was appointed CTO.
Dataextraction: Platform capabilities help sort through complex details and quickly pull the necessary information from large documents. This unified experience optimizes the process of developing and deploying ML models by streamlining workflows for increased efficiency.
It uniquely combines verifiable and open-ended questions, including theorem proving, making it valuable for developing algorithms that enhance LLMs’ reasoning abilities beyond simple verification tasks and enabling knowledge distillation from stronger to weaker models.
The increasing volume of spoken content (whether in podcasts, music, video content, or real-time communications) offers businesses untapped opportunities for dataextraction and insights. This transformation happens through complex algorithms that analyze audio data and decode it into corresponding text.
Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. A human-in-the-loop process combines supervised ML with human involvement in training and testing an algorithm. Using IDP can reduce or eliminate the requirement for time-consuming human reviews. What is human-in-the-loop?
In addition to its prowess in crafting captivating narratives and artistic creations, generative AI demonstrates its versatility by helping users empower their own data analytics. With its advanced algorithms and language comprehension, it can navigate complex datasets and distill valuable insights.
In mortgage requisition intake, AI optimizes efficiency by automating the analysis of requisition data, leading to faster processing times. Fraud detection has become more robust with advanced AI algorithms that help identify and prevent fraudulent activities, thereby safeguarding assets and reducing risks.
It is crucial to pursue a metrics-driven strategy that emphasizes the quality of dataextraction at the field level, particularly for high-impact fields. Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes.
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library.
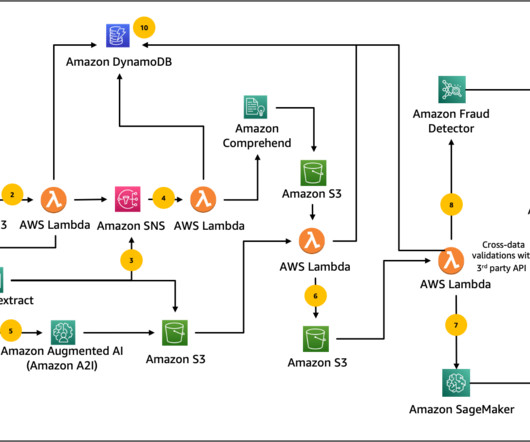
The document pages are then automatically routed to Amazon Textract text processing operations for accurate dataextraction and analysis. This is achieved by generating fraud predictions based on dataextracted from the mortgage documents against ML fraud models trained with the customer’s historical (fraud) data.
The efficiency of its memory system is influenced by the quality of dataextraction, the algorithms used for indexing and storage, and the scalability of the system as the volume of stored information grows. This allows for more context-aware responses, improving the user experience.
This not only speeds up content production but also allows human writers to focus on more creative and strategic tasks. - **Data Analysis and Summarization**: These models can quickly analyze large volumes of data, extract relevant information, and summarize findings in a readable format.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of BeautifulSoup} Image by Author Behold the wondrous marvel known as BeautifulSoup, a mighty Python library renowned for its prowess in the realms of web scraping and dataextraction from HTML and XML documents.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
As such, unless a task requires such complexity, it is better to use simple algorithms. An interesting approach One algorithm of note focuses on topic classification by employing data compression algorithms. It utilizes a compressor algorithm (e.g., gzip), NID, and the good old KNN algorithm.
Data retrieval and augmentation – When a query is initiated, the Vector Database Snap Pack retrieves relevant vectors from OpenSearch Service using similarity search algorithms to match the query with stored vectors. The retrieved vectors augment the initial query with context-specific enterprise data, enhancing its relevance.
We’ll need to provide the chunk data, specify the embedding model used, and indicate the directory where we want to store the database for future use. Additionally, the context highlights the role of Deep Learning in extracting meaningful abstract representations from Big Data, which is an important focus in the field of data science.
Text Recognition OCR uses two algorithms: pattern matching and feature extraction for text extraction. Feature extraction breaks down characters into basic shapes and matches them to stored patterns. ML algorithms can learn from data and improve their accuracy over time.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content