This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recent studies have addressed this gap by introducing benchmarks that evaluate AI agents on various softwareengineering and machine learning tasks. Furthermore, these frameworks often lack flexibility in assessing diverse research outputs, such as novel algorithms, model architectures, or predictions.
It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. So let’s explore how MLOps for softwareengineers addresses these hurdles, enabling scalable, efficient AI development pipelines.
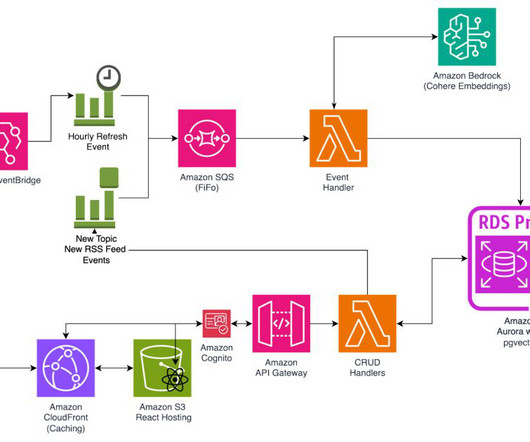
On our website, users can subscribe to an RSS feed and have an aggregated, categorized list of the new articles. However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions.
What is AI Engineering AI Engineering is a new discipline focused on developing tools, systems, and processes to enable the application of artificial intelligence in real-world contexts [1]. In a nutshell, AI Engineering is the application of softwareengineering best practices to the field of AI.
Design patterns in softwareengineering are typical solutions to common problems in software design. They represent best practices, evolved over time, and are a toolkit for software developers to solve common problems efficiently. It defines a family of algorithms, encapsulates each one, and makes them interchangeable.
Advanced Gradient Boosting: Probabilistic Regression and Categorical Structure Brian Lucena | Principal | Numeristical Join this hands-on training to learn some of the more advanced, cutting-edge techniques for gradient boosting. Sign up here Above are just a few of the training sessions you’ll find at ODSC East.
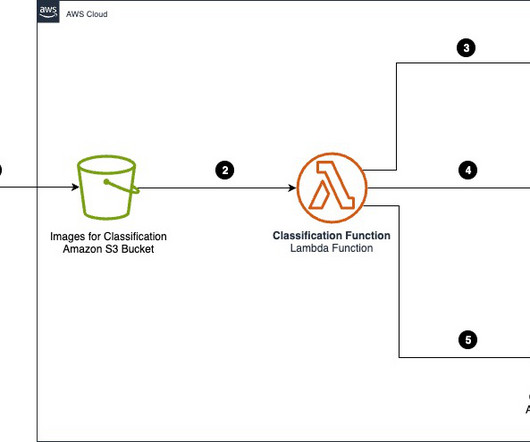
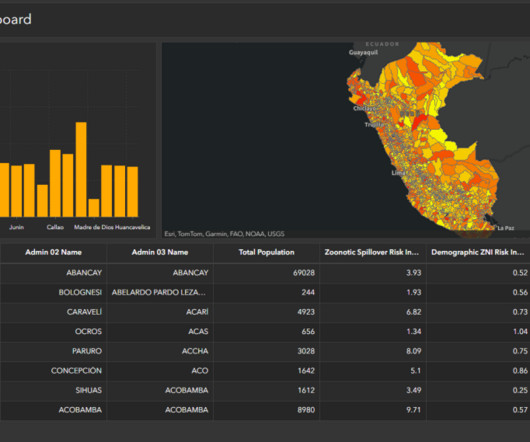
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Categorizing documents is an important first step in IDP systems. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale.
In fact, AI/ML graduate textbooks do not provide a clear and consistent description of the AI softwareengineering process. Therefore, I thought it would be helpful to give a complete description of the AI engineering process or AI Process, which is described in most AI/ML textbooks [5][6].
Model training You can continue experimenting with different feature engineering techniques in your JupyterLab environment and track your experiments in MLflow. You can use the xgboost algorithm for this purpose and run your code either in your JupyterLab environment or as a SageMaker Training job. For example, pending or approved.
Many Discord users are high school and undergraduate college students with no AI/ML or softwareengineering experience. I learned this lesson after spending considerable time trying to help beginners (unknown to me) who proceeded to solve the wrong problem using the wrong algorithm. Describe the problem.
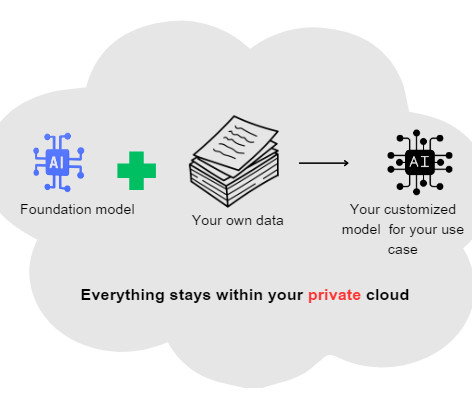
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. While these challenges can be significant, they are not insurmountable.
Fan | Staff SoftwareEngineer | Quansight Labs This session will start with an overview of scikit-learn’s API for supervised machine learning, with a focus on its three methods: fit to build models, predict to make predictions from models, and transform to modify data. Jon Krohn | Chief Data Scientist | Nebula.io
The dataset, divided into three categories intuitive properties of lists, trees, and numbers (medley), termination lemmas for recursive functions (termination), and properties of nonstandard sorting algorithms (sorting)included 201 theorem statements. success rate on medley properties.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Advancements in machine learning algorithms are equipping chatbots with emotional intelligence. These include customer operations, marketing & sales, and softwareengineering. SoftwareEngineering Generative AI can revolutionize softwareengineering processes.
The two most common types of supervised learning are classification , where the algorithm predicts a categorical label, and regression , where the algorithm predicts a numerical value. Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided.
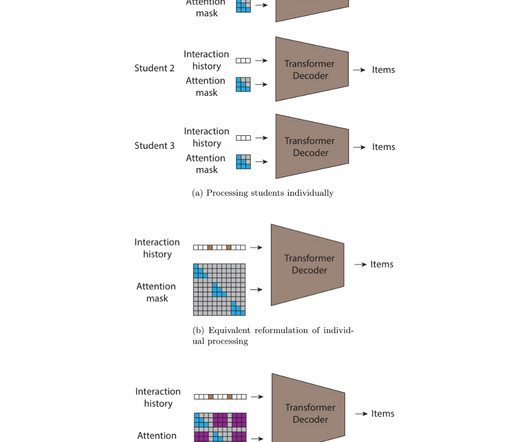
We developed the STUDY algorithm in partnership with Learning Ally , an educational nonprofit, aimed at promoting reading in dyslexic students, that provides audiobooks to students through a school-wide subscription program. We evaluate the model on the entire test set (all) as well as the novel and non-continuation splits.
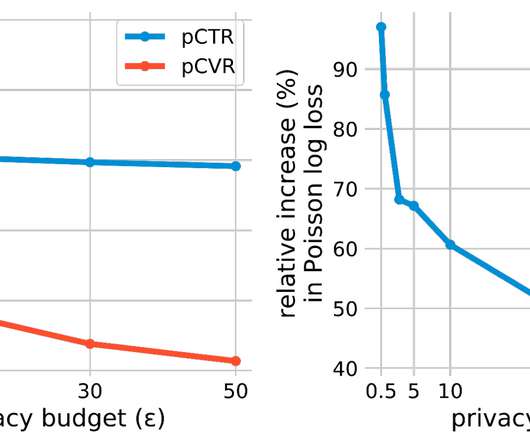
Posted by Krishna Giri Narra, SoftwareEngineer, Google, and Chiyuan Zhang, Research Scientist, Google Research Ad technology providers widely use machine learning (ML) models to predict and present users with the most relevant ads, and to measure the effectiveness of those ads.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and soon. Theyre looking for people who know all related skills, and have studied computer science and softwareengineering.
Photo by Nathan Anderson on Unsplash Brief Intro to ML Algorithms A decision tree is a widely used algorithm in machine learning. The Gradient Boosted Tree (GBT) algorithm begins with an initial prediction and iteratively adds decision trees to correct errors and improve accuracy. at the University of Washington.
Spatial data, which relates to the physical position and shape of objects, often contains complex patterns and relationships that may be difficult for traditional algorithms to analyze. fillna(0) df1['totalpixels'] = df1.sum(axis=1) fillna(0) allDf[col] = allDf.groupby(idCols + ['year'])[col].transform(lambda
Model Training: This step involves selecting an algorithm, feeding it with training data, and iteratively adjusting its parameters to minimize error. This issue becomes even more difficult when code is passed between different roles, such as from a data scientist to a softwareengineer for deployment.
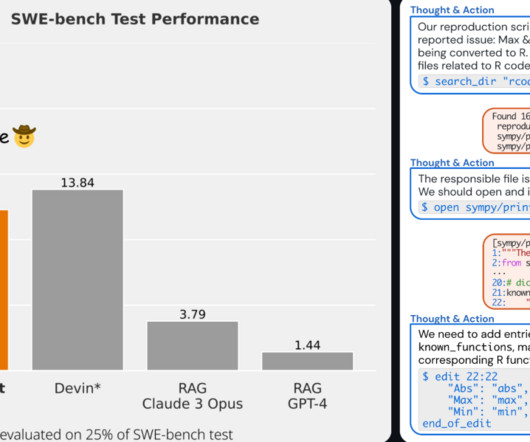
From self-driving cars to language models that can engage in human-like conversations, AI is rapidly transforming various industries, and software development is no exception. However, the advent of AI-powered softwareengineers like SWE-Agent has the potential to disrupt this age-old paradigm.
Session 2: Bayesian Analysis of Survey Data: Practical Modeling withPyMC Unlock the power of Bayesian inference for modeling complex categorical data using PyMC. This session takes you from logistic regression to categorical and ordered logistic regression, providing practical, hands-on experience with real-world surveydata.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. The model then uses a clustering algorithm to group the sentences into clusters. Shyam Desai is a Cloud Engineer for big data and machine learning services at AWS.
Apply the MinHash algorithm as shown in the preceding example and calculate the similarity scores between paragraphs. Instruction fine tuning dataset format The columns in the table that follows represent the key components of the instruction-tuning paradigm: Type categorizes the task or instruction type. David Ping is a Sr.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content