This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The gait is not biological, but the robot isnt biological, explains Farbod Farshidian , roboticist at the RAI Institute. The best Farshidian can categorize how Spot is moving is that its somewhat similar to a trotting gait, except with an added flight phase (with all four feet off the ground at once) that technically turns it into a run.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
These systems, built on biased datasets and algorithms, fail to reflect the diversity of global populations. Bias in AI typically can be categorized into algorithmic bias and data-driven bias. Algorithmic bias occurs when the logic and rules within an AI model favor specific outcomes or populations.
Introduction Classification algorithms are at the heart of data science, helping us categorize and organize data into pre-defined classes. These algorithms are used in a wide array of applications, from spam detection and medical diagnosis to image recognition and customer profiling.
Second, for each provided base table T, the researchers use data discovery algorithms to find possible related candidate tables. Adding more details about connected tables in a database to the data catalog basically helps statistical-based search algorithms overcome their limitations. Check out the Paper.
Bookkeeping involves the meticulous scanning of receipts, methodically tracking all income and expenses, and categorizing expenditures. However, now, you need to categorize it for tax purposes. Imagine this scenario: you’ve purchased a printer for your home office, and it turns out to be of great help.
Tech concepts (if any) will be explained in plain English. If you’re new to ML, you probably must’ve heard of the words “algorithm” or “model” without knowing how they’re related to machine learning. Machine learning algorithms are categorized as supervised or unsupervised.
RL algorithms can be generally categorized into two groups i.e., value-based and policy-based methods. We will discuss the intuition behind PG, how it works, and also provide a code implementation of the algorithm. Last Updated on May 25, 2023 by Editorial Team Author(s): Ebrahim Pichka Originally published on Towards AI.
As Argonne postdoctoral researcher James (Jay) Horwath explains, “The way we understand how materials move and change over time is by collecting X-ray scattering data.” Unsupervised machine learning algorithm A key component of this new approach is the use of an unsupervised machine learning algorithm.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. To identify the overlap densities within datasets, we developed an overlap detection algorithm leveraging the simplicity bias in neural network learning. I have also summarized the presentation’s main points here.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. To identify the overlap densities within datasets, we developed an overlap detection algorithm leveraging the simplicity bias in neural network learning. I have also summarized the presentation’s main points here.
Summary: This comprehensive guide covers the basics of classification algorithms, key techniques like Logistic Regression and SVM, and advanced topics such as handling imbalanced datasets. Classification algorithms are crucial in various industries, from spam detection in emails to medical diagnosis and customer segmentation.
To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Linear categorical to categorical correlation is not supported.
The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety. Depending on which role you have as a company, you will need to comply with different requirements,” Simons explains. Or are you actually fine-tuning the model quite a bit?
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. Machine Translation : Translating text from one language to another. Still confused?
ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. Sophisticated ML algorithms drive the intelligence behind conversational AI, enabling it to learn and enhance its capabilities through experience. Ensuring fairness and inclusivity in conversational AI is crucial.
Summary: This tutorial provides a comprehensive guide on Softmax Regression, explaining its principles and implementation using NumPy and PyTorch. Some of its key applications include image classification, text categorization, and more. What Optimization Algorithm is Helpful in Training Softmax Regression Models?
One of the most popular algorithms in Machine Learning are the Decision Trees that are useful in regression and classification tasks. In Supervised Learning, Decision Trees are the Machine Learning algorithms where you can split data continuously based on a specific parameter. Hence, the decision tree variable is categorical.
Then, how to essentially eliminate training, thus speeding up algorithms by several orders of magnitude? It easily handles a mix of categorical, ordinal, and continuous features. Yet, I haven’t seen a practical implementation tested on real data in dimensions higher than 3, combining both numerical and categorical features.
In the ever-evolving landscape of machine learning and artificial intelligence, understanding and explaining the decisions made by models have become paramount. Enter Comet , that streamlines the model development process and strongly emphasizes model interpretability and explainability. Why Does It Matter?
ML algorithms and data science are how recommendation engines at sites like Amazon, Netflix and StitchFix make recommendations based on a user’s taste, browsing and shopping cart history. ML classification algorithms are also used to label events as fraud, classify phishing attacks and more.
Currently chat bots are relying on rule-based systems or traditional machine learning algorithms (or models) to automate tasks and provide predefined responses to customer inquiries. Watsonx.governance is providing an end-to-end solution to enable responsible, transparent and explainable AI workflows. Watsonx.ai
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. The term “foundation model” was coined by the Stanford Institute for Human-Centered Artificial Intelligence in 2021.
Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles. Most experts categorize it as a powerful, but narrow AI model. NLP techniques help them parse the nuances of human language, including grammar, syntax and context.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online. Models […]
The Evolution of AI Agents Transition from Rule-Based Systems Early software systems relied on rule-based algorithms that worked well in controlled, predictable environments. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. For more details, refer to the GitHub repo.
Source: Author Introduction Text classification, which involves categorizing text into specified groups based on its content, is an important natural language processing (NLP) task. This article will look at how R can be used to execute text categorization tasks efficiently. You can read more about the R language here.
To create NLP models, developers need not only algorithms, but bucketloads of quality training data that is accurately “labelled,” a technique that categorizes raw data to enable machines to understand and learn from it. million ($2.9
Amazon SageMaker provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. In this article, I am going to explain in detail step-by-step approaches or stages of the machine learning project lifecycle. The success of any ML project depends on a well-structured lifecycle.
“If we compare the relative performance of Silicon Valley’s stock to that of JP Morgan and Bank of America since 1993, its market value rose 250-fold until the market’s peak on Nov 3, 2021, relative to 11-fold for JP Morgan and three-fold for Bank of America,” Vasant explained. So how can algorithms recognize overreactions?
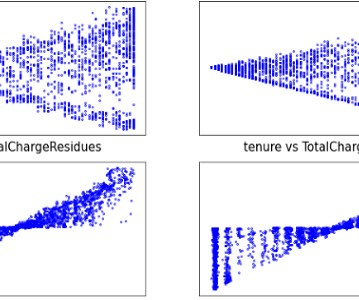
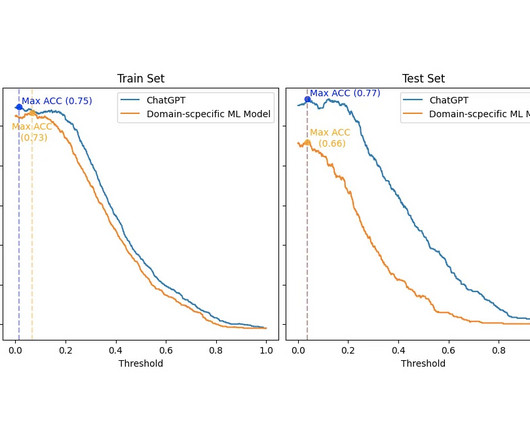
So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. This evaluation assesses how the accuracy (y-axis) changes regarding the threshold (x-axis) for categorizing the numeric Gold-Standard dataset for both models. First, I must be honest. Then, I made a confusion matrix.
Contact Lens for Amazon Connect generates call and chat transcripts; derives contact summary, analytics, categorization of associate-customer interaction, and issue detection; and measures customer sentiments. Contact Lens rules help us categorize known issues in the contact center.
These services use advanced machine learning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. The following graphic is a simple example of Windows Server Console activity that could be captured in a video recording.
For instance, a hospital using this architecture could categorize patient symptoms and link them to probable diagnoses in a structured, efficient manner. XAI RAG: XAI RAG emphasizes explainability, ensuring users understand how and why a response was generated.
Target nodes have numerical and categorical features assigned, whereas other node types are featureless. An algorithm for real-time inductive inference with an RGCN model runs as follows: Given a batch of transactions and a trained RGCN model, extend graph representation with entities from the batch.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
Excel VBA Script Explainer uses AI to explain Excel VBA code, while the Excel VBA Script Generator creates VBA scripts. The Google Sheets Formula Generator and the Google Apps Script Explainer use artificial intelligence to analyze and clarify scripts. The use of AI hopes to speed up the process of formula creation.
Although recognition tasks can provide robust reasoning about the parts of the object not visible in the images, the semantic solution is feasible only if it can be explained by an object present in the database. The first baseline is based on clustering whereas the second baseline performs database retrieval.
In this lesson, we will answer this question by explaining the machine learning behind YouTube video recommendations. YouTube Video Recommendation Systems We will start with a system overview of the YouTube recommendation algorithm and then dive into individual components later. RecSys’16 ). RecSys’16 ).
Data Which Fuels AI is Derived through Image Annotation A computer program or algorithm that interprets data, analyzes patterns or recognizes trends is known as artificial intelligence. In order to achieve this, one must understand the algorithms and be able to apply them to real-world challenges through AI.
Papers were annotated with metadata such as author affiliations, publication year, and citation count and were categorized based on methodological approaches, specific safety concerns addressed, and risk mitigation strategies. Research methods include applied algorithms, simulated agents, analysis frameworks, and mechanistic interpretability.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., ” Even for seasoned programmers, the syntax of shell commands might need to be explained. rely on Language Models as their foundation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























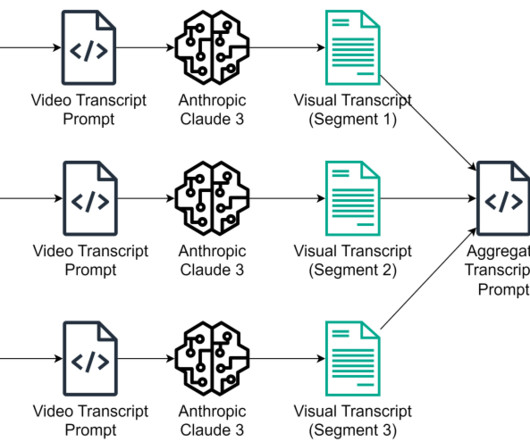

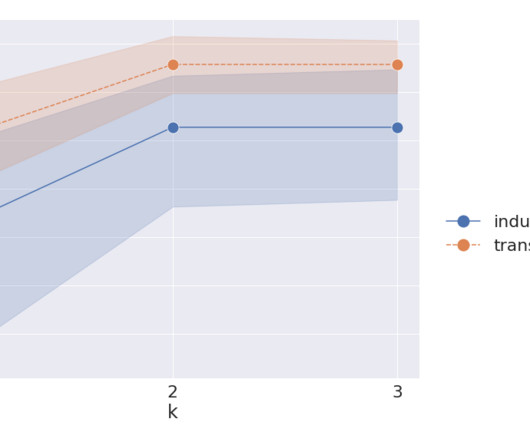












Let's personalize your content