This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
And then I found certain areas in computer science very attractive such as the way algorithms work, advanced algorithms. I wanted to do a specialization in that area and that's how I got my Masters in Computer Science with a specialty in algorithms. So that's how I got my undergraduate education.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. Apache Spark is an open-source, unified analytics engine for large-scale data processing.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Role of Data Transformation in Analytics, Machine Learning, and BI In Data Analytics, transformation helps prepare data for various operations, including filtering, sorting, and summarisation, making the data more accessible and useful for Analysts. Why Are Data Transformation Tools Important?
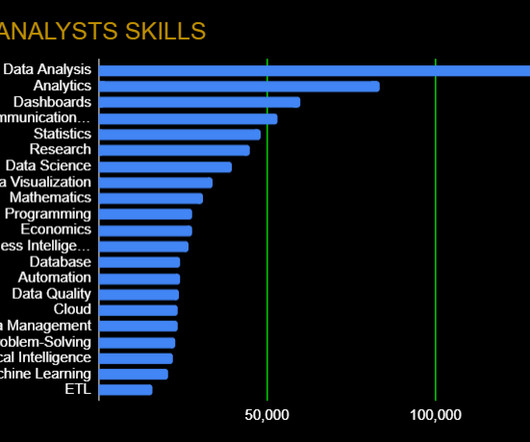
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
It relates to employing algorithms to find and examine data patterns to forecast future events. Through practice, machines pick up information or skills (or data). Algorithms and models Predictive analytics uses several methods from fields like machine learning, data mining, statistics, analysis, and modeling.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. Data Quality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. They store structured data in a format that facilitates easy access and analysis.
As businesses increasingly rely on data-driven strategies, the global BI market is projected to reach US$36.35 The rise of bigdata, along with advancements in technology, has led to a surge in the adoption of BI tools across various sectors. Data Processing: Cleaning and organizing data for analysis.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by Data Scientists. How to Become an Azure Data Engineer? Which service would you use to create Data Warehouse in Azure?
Tools like Harness and JenkinsX use machine learning algorithms to predict potential deployment failures, manage resource usage, and automate rollback procedures when something goes wrong. In the world of DevOps, AI can help monitor infrastructure, analyze logs, and detect performance bottlenecks in real-time.
The logical flow of running upstream and downstream tasks is decided using an algorithm commonly known as a Directed Acyclic Graph (DAG). Best data pipeline tools: Apache Airflow | Source Categorization Open Source Batch data processing Pros Fully customizable and supports complex business use cases.
I would start by collecting historical sales data and other relevant variables such as promotional activities, seasonality, and economic factors. Then, I would explore forecasting models such as ARIMA, exponential smoothing, or machine learning algorithms like random forests or gradient boosting to predict future sales.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
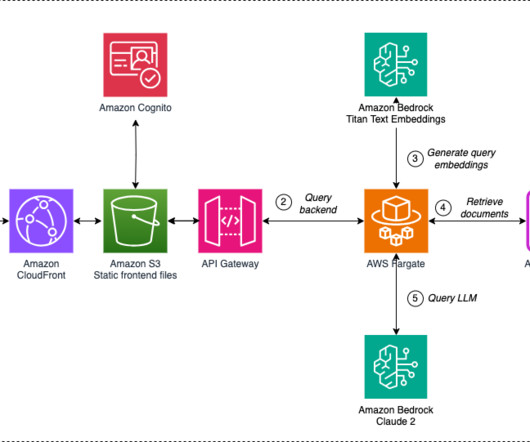
Generative AI empowers organizations to combine their data with the power of machine learning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content