This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post MobileBERT: BERT for Resource-Limited Devices appeared first on Analytics Vidhya. Overview As the size of the NLP model increases into the hundreds of billions of parameters, so does the importance of being able to.
These systems, typically deeplearning models, are pre-trained on extensive labeled data, incorporating neural networks for self-attention. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3%
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., These are essential for understanding machine learningalgorithms.
Introduction Large Language Models (LLMs) are foundational machine learning models that use deeplearningalgorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
Rather than learning to generate new data, these models aim to make accurate predictions. Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. Image Source Subsequent breakthroughs in Transformer-based architectures brought predictive capabilities to new heights. GPT-3 by Brown et al.
Traditional machine learning is a broad term that covers a wide variety of algorithms primarily driven by statistics. The two main types of traditional ML algorithms are supervised and unsupervised. These algorithms are designed to develop models from structured datasets. K-means Clustering. K-means Clustering.
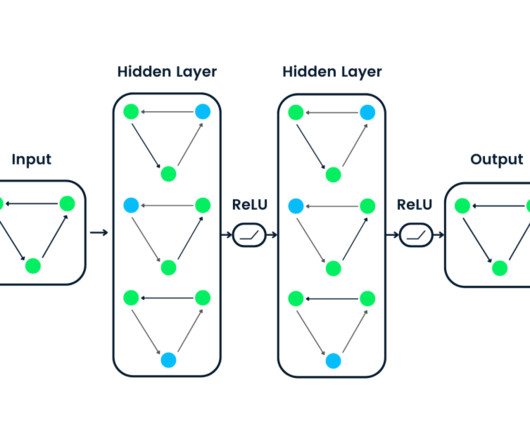
This gap has led to the evolution of deeplearning models, designed to learn directly from raw data. What is DeepLearning? Deeplearning, a subset of machine learning, is inspired by the structure and functioning of the human brain. High Accuracy: Delivers superior performance in many tasks.
Once the brain signals are collected, AI algorithms process the data to identify patterns. These algorithms map the detected patterns to specific thoughts, visual perceptions, or actions. For instance, in visual reconstructions, the AI system learns to associate brain wave patterns with images a person is viewing.
Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes. However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deeplearning and Natural Language Processing (NLP) to play pivotal roles in this tech.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deeplearning, computer vision , natural language processing , and more. NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT.
BERT, GPT, or T5) based on the task. Strategy Pattern The Strategy Pattern defines a family of interchangeable algorithms, encapsulating each one and allowing the behavior to change dynamically at runtime. Switching algorithms dynamically (Strategy pattern) to balance latency and accuracy based on system load or real-time constraints.
Machine learning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model.
By utilizing machine learningalgorithms , it produces new content, including images, text, and audio, that resembles existing data. Another breakthrough is the rise of generative language models powered by deeplearningalgorithms. trillion parameters, making it one of the largest language models ever created.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
Today, we can train deeplearningalgorithms that can automatically extract and represent information contained in audio signals, if trained with enough data. Traditional machine learning feature-based pipeline vs. end-to-end deeplearning approach ( source ).
This term refers to how much time, memory, or processing power an algorithm requires as the size of the input grows. In AI, particularly in deeplearning , this often means dealing with a rapidly increasing number of computations as models grow in size and handle larger datasets.
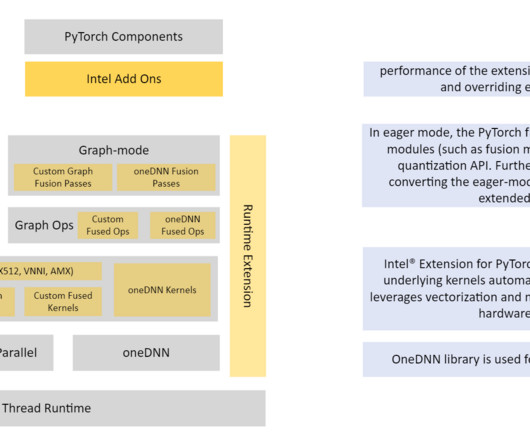
We present the results of recent performance and power draw experiments conducted by AWS that quantify the energy efficiency benefits you can expect when migrating your deeplearning workloads from other inference- and training-optimized accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Inferentia and AWS Trainium.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. The Decline of Traditional MachineLearning 20182020: Algorithms like random forests, SVMs, and gradient boosting were frequent discussion points.
Black box algorithms such as xgboost emerged as the preferred solution for a majority of classification and regression problems. The advent of more powerful personal computers paved the way for the gradual acceptance of deeplearning-based methods. CS6910/CS7015: DeepLearning Mitesh M.
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearning Machine learning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Traditional Computing Systems : From basic computing algorithms, the journey began.
Graph Neural Networks (GNNs) have emerged as a powerful deeplearning framework for graph machine learning tasks. GLEM goes further by proposing a variational EM algorithm that alternates between updating the LLM and GNN components for mutual enhancement.
A significant breakthrough came with neural networks and deeplearning. Transformer-based models such as BERT and GPT-3 further advanced the field, allowing AI to understand and generate human-like text across languages. IBM's Model 1 and Model 2 laid the groundwork for advanced systems.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data.
Generative AI represents a significant advancement in deeplearning and AI development, with some suggesting it’s a move towards developing “ strong AI.” Generative AI uses advanced machine learningalgorithms and techniques to analyze patterns and build statistical models.
With these fairly complex algorithms often being described as “giant black boxes” in news and media, a demand for clear and accessible resources is surging. This process of adapting pre-trained models to new tasks or domains is an example of Transfer Learning , a fundamental concept in modern deeplearning.
In the following example figure, we show INT8 inference performance in C6i for a BERT-base model. The BERT-base was fine-tuned with SQuAD v1.1, In the context of deeplearning, the predominant numerical format used for research and deployment has so far been 32-bit floating point, or FP32.
binary_classifier_interlocutor.ipynb” file stores our binary classifier which uses ensemble learning to classify if a text was uttered by the therapist or the client while “binary_classifier_quality.ipynb” determines if the overall conversation between a therapist and client is of high quality or low quality.
BERT (Bidirectional Encoder Representations from Transformers) Google created the deeplearning model known as BERT (Bidirectional Encoder Representations from Transformers) for natural language processing (NLP).
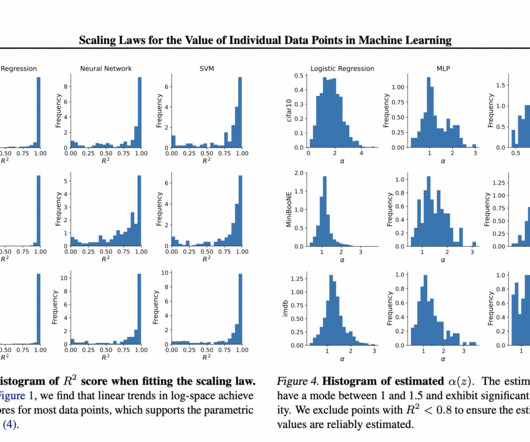
The related works in this paper discuss a method called Scaling Laws for deeplearning, which have become popular in recent years. Pre-trained embeddings like frozen ResNet-50 and BERT, are used to speed up training and prevent underfitting for CIFAR-10 and IMDB, respectively.
Then using Machine Learning and DeepLearning sentiment analysis techniques, these businesses analyze if a customer feels positive or negative about their product so that they can make appropriate business decisions to improve their business. are used to classify the text sentiment.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. NLP algorithms help computers understand, interpret, and generate natural language.
Large-scale deeplearning models, especially transformer-based architectures, have grown exponentially in size and complexity, reaching billions to trillions of parameters. Recent studies have reviewed language models, optimization techniques, and acceleration methods for large-scale deep-learning models and LLMs.
To further comment on Fury, for those looking to intern in the short term, we have a position available to work in an NLP deeplearning project in the healthcare domain. AND multilingual models) GitHub: UKPLab/sentence-transformers BERT / RoBERTa / XLM-RoBERTa produces out-of-the-box rather bad sentence embeddings.
Text classification with transformers refers to the application of deeplearning models based on the transformer architecture to classify sequences of text into predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
This is typically done using large language models like BERT or GPT. Key features of Shap-E: a) Implicit representation : Shap-E learns to generate implicit representations (signed distance functions) of 3D objects. Here's a simplified example of how this might look in code: class TextTo3D(nn.Module): def __init__(self): super().__init__()
While some progress has been made in enhancing retrieval mechanisms through latent semantic analysis (LSA) and deeplearning models, these methods still need to address the semantic gaps between queries and documents. This restricts their adaptability to real-world scenarios where data is constantly changing.
He calls the blending of AI algorithms and model architectures homogenization , a trend that helped form foundation models. That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. See chart below.)
Understanding the terminology, from the foundational aspects of training and fine-tuning to the cutting-edge concepts of transformers and reinforcement learning, is the first step towards demystifying the powerful algorithms that drive modern AI language systems.
” Shaped AI also provides ranking algorithms for feeds, recommendations, and discovery sites. Top Open Source Large Language Models GPT-Neo, GPT-J, and GPT-NeoX Extremely potent artificial intelligence models, such as GPT-Neo, GPT-J, and GPT-NeoX, can be used to Few-shot learning issues.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content