This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
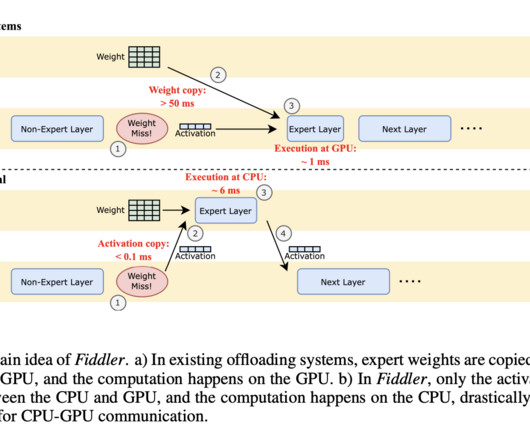
Fiddler’s design showcases a significant technical innovation in AI model deployment. This breakthrough can potentially democratize large-scale AI models, paving the way for broader applications and research in artificial intelligence. Don’t Forget to join our Telegram Channel You may also like our FREE AI Courses….
Run AI recently announced an open-source solution to tackle this very problem: Run AI: Model Streamer. This tool aims to drastically cut down the time it takes to load inference models, helping the AI community overcome one of its most notorious technical hurdles. seconds, whereas Run Model Streamer can do it in just 4.88
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. In our tests, we’ve seen substantial improvements in scaling times for generative AI model endpoints across various frameworks.
Modern AI systems rely on vast datasets of token trillions to improve their accuracy and efficiency. Researchers at the Allen Institute for AI introduced olmOCR , an open-source Python toolkit designed to efficiently convert PDFs into structured plain text while preserving logical reading order.
The use of large language models (LLMs) and generative AI has exploded over the last year. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. 1B", "prompt": "What is Gen AI?", "temperature":0, "max_tokens": 128}' | jq '.choices[0].text' 1B is running.
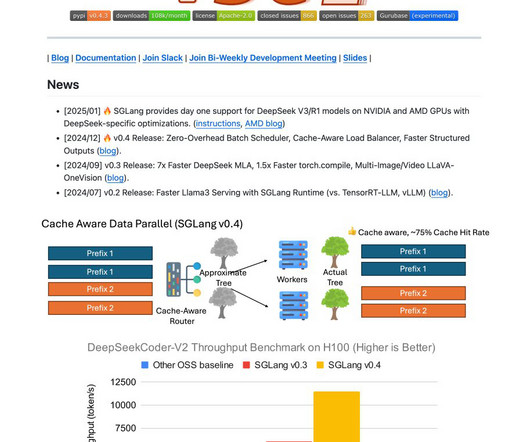
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit.
Together AI has unveiled a groundbreaking advancement in AIinference with its new inference stack. This stack, which boasts a decoding throughput four times faster than the open-source vLLM, surpasses leading commercial solutions like Amazon Bedrock, Azure AI, Fireworks, and Octo AI by 1.3x
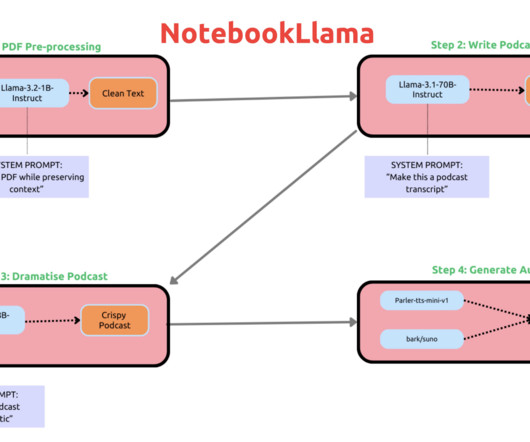
By providing tools to enhance both code writing and documentation, Meta’s NotebookLlama supports a community-driven model that emphasizes transparency, openness, and flexibility—qualities often lacking in proprietary AI-driven software. Conclusion Meta’s NotebookLlama is a significant step forward in the world of open-source AI tools.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance.
The Role of AI in Medicine: AI simulates human intelligence in machines and has significant applications in medicine. AI processes large datasets to identify patterns and build adaptive models, particularly in deep learning for medical image analysis, such as X-rays and MRIs.
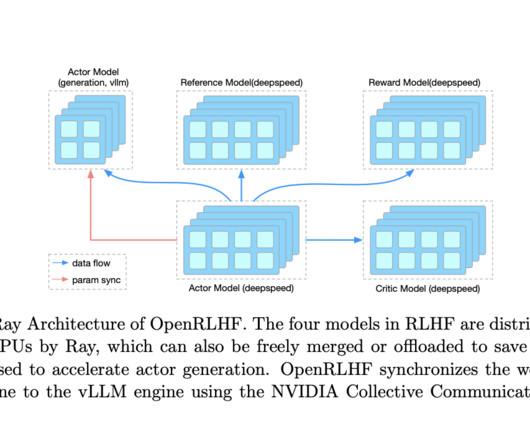
OpenRLHF leverages two key technologies: Ray, the Distributed Task Scheduler, and vLLM, the Distributed InferenceEngine. Don’t Forget to join our 42k+ ML SubReddit The post OpenRLHF: An Open-Source AI Framework Enabling Efficient Reinforcement Learning from Human Feedback RLHF Scaling appeared first on MarkTechPost.
Additionally, many of these search engines are not open-source, limiting the ability for broader community involvement and innovation. Introducing OpenPerPlex OpenPerPlex is an open-source AI-powered search engine designed to tackle these challenges head-on. OpenPerPlex’s effectiveness is driven by its robust tech stack.
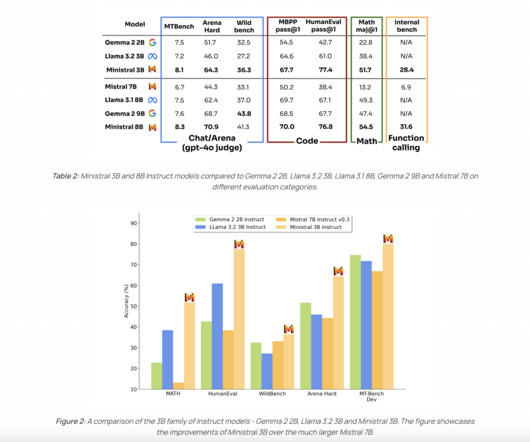
High-performance AI models that can run at the edge and on personal devices are needed to overcome the limitations of existing large-scale models. Introducing Ministral 3B and Ministral 8B Mistral AI recently unveiled two groundbreaking models aimed at transforming on-device and edge AI capabilities—Ministral 3B and Ministral 8B.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
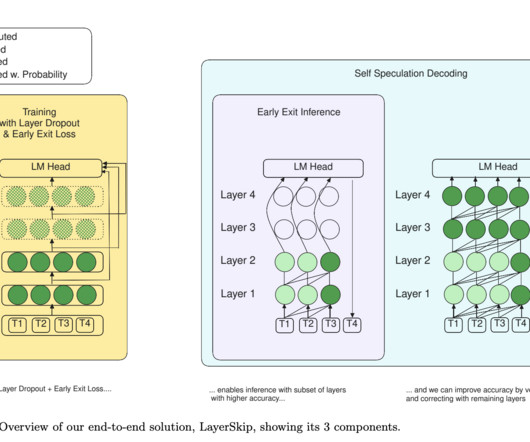
With the release of LayerSkip, the research community now has access to a practical and effective tool for optimizing LLM inference, potentially paving the way for more accessible AI deployment in real-world applications. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
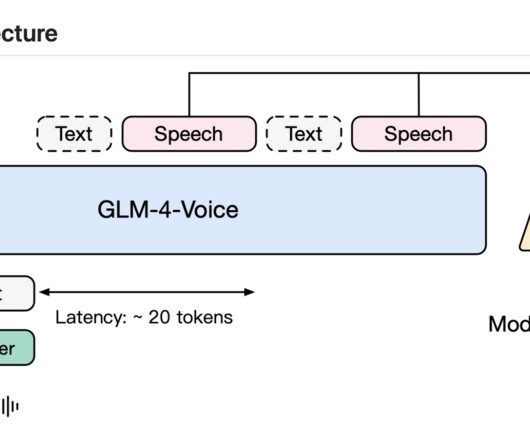
Modern AI models excel in text generation, image understanding, and even creating visual content, but speech—the primary medium of human communication—presents unique hurdles. Zhipu AI recently released GLM-4-Voice, an open-source end-to-end speech large language model designed to address these limitations.
Current generative AI models face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Don’t Forget to join our 50k+ ML SubReddit.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. About the Authors Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
Researchers from Stanford University, Together AI, California Institute of Technology, and MIT introduced LoLCATS (Low-rank Linear Conversion via Attention Transfer). Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
AI-generated content is advancing rapidly, creating both opportunities and challenges. As generative AI tools become mainstream, the blending of human and AI-generated text raises concerns about authenticity, authorship, and misinformation.
Despite progress in AI, most language models struggle with the intricate aspects of financial data. An AI professional recently released a new financial domain model, Hawkish 8B , which is making waves in the Reddit community with its remarkable capabilities. Don’t Forget to join our 55k+ ML SubReddit.
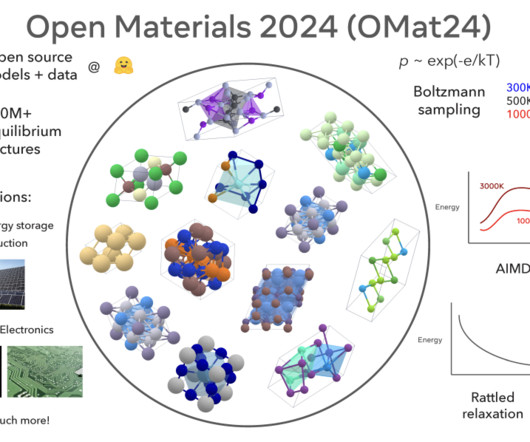
While AI has emerged as a powerful tool for materials discovery, the lack of publicly available data and open, pre-trained models has become a major bottleneck. The introduction of the OMat24 dataset and the corresponding models represents a significant leap forward in AI-assisted materials science.
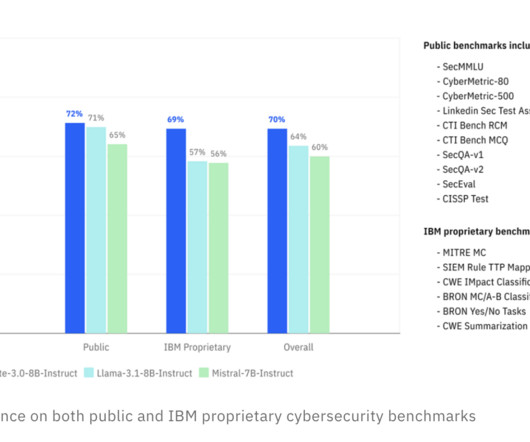
Artificial intelligence is advancing rapidly, but enterprises face many obstacles when trying to leverage AI effectively. Traditional AI models often struggle with delivering such tailored performance, requiring businesses to make a trade-off between customization and general applicability. IBM has officially released Granite 3.0
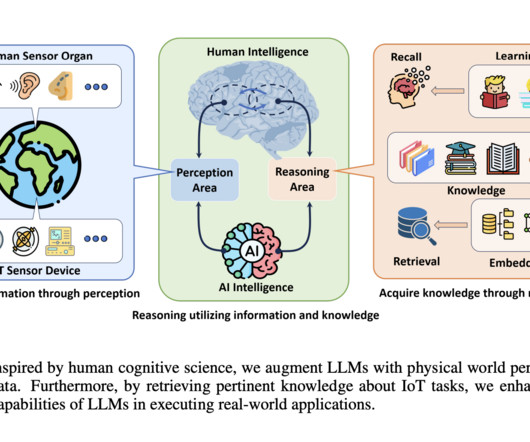
Rule-based systems, traditional machine learning models, and basic AI-driven methods are conventional models for processing IoT data. Don’t Forget to join our 50k+ ML SubReddit. MARS Lab, NTU has devised an innovative IoT-LLM framework that combats the limitations of the LLM in handling real-world tasks.
However, recent advancements in generative AI have opened up new possibilities for creating an infinite game experience. Researchers from Google and The University of North Carolina at Chapel Hill introduced UNBOUNDED, a generative infinite game designed to go beyond traditional, finite video game boundaries using AI.
In recent years, AI-driven workflows and automation have advanced remarkably. enabling developers to leverage the latest advancements in AI language models. Moreover, the OpenAI-compatible Assistants API and Python SDK offer flexibility in easily integrating these agents into broader AI solutions. Check out the GitHub.
Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google AI Research Examines Random Circuit Sampling (RCS) for Evaluating Quantum Computer Performance in the Presence of Noise appeared first on MarkTechPost.
Meta AI releases Meta Lingua: a minimal and fast LLM training and inference library designed for research. By prioritizing simplicity and reusability, Meta AI hopes to facilitate a more inclusive and accelerated research environment. Don’t Forget to join our 50k+ ML SubReddit.
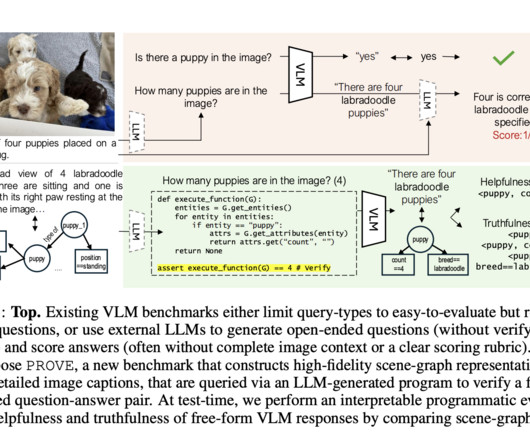
Researchers from Salesforce AI Research have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
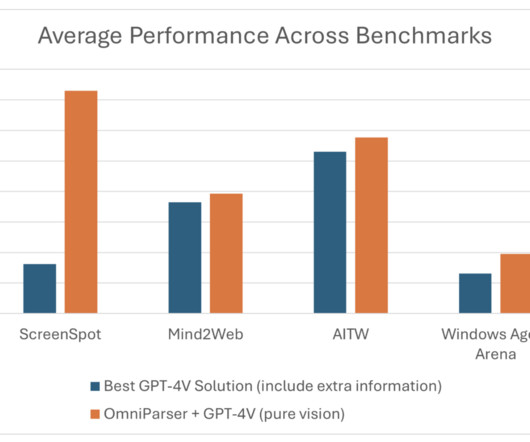
With OmniParser, Microsoft has made significant strides in enabling automated agents to identify actionable elements like buttons and icons purely based on screenshots, broadening the possibilities for developers working with multimodal AI systems. Don’t Forget to join our 55k+ ML SubReddit.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
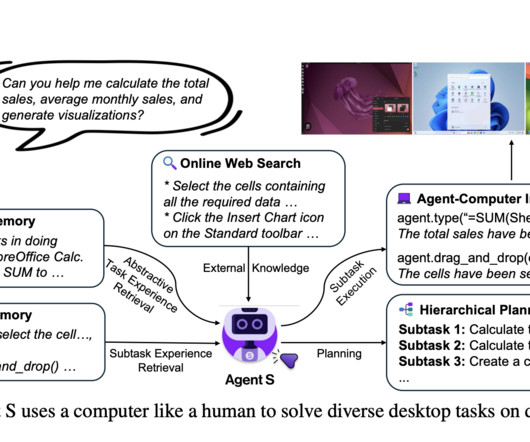
This framework aims to transform human-computer interaction by enabling AI agents to use the mouse and keyboard as humans would to complete complex tasks. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
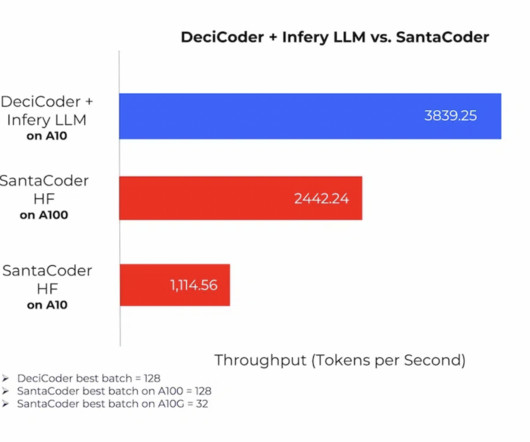
In the fast-paced world of AI, efficient code generation is a challenge that can’t be overlooked. Addressing this efficiency gap head-on, Deci, a pioneering AI company, introduces DeciCoder, a 1-billion-parameter open-source Large Language Model (LLM) that aims to redefine the gold standard in efficient and accurate code generation.
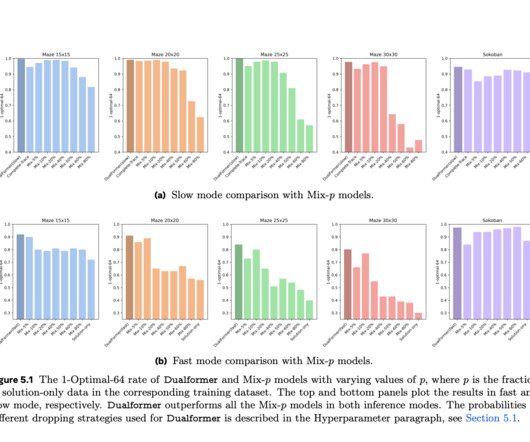
A major challenge in AI research is how to develop models that can balance fast, intuitive reasoning with slower, more detailed reasoning in an efficient way. In AI models, this dichotomy between the two systems mostly presents itself as a trade-off between computational efficiency and accuracy. Check out the Paper.
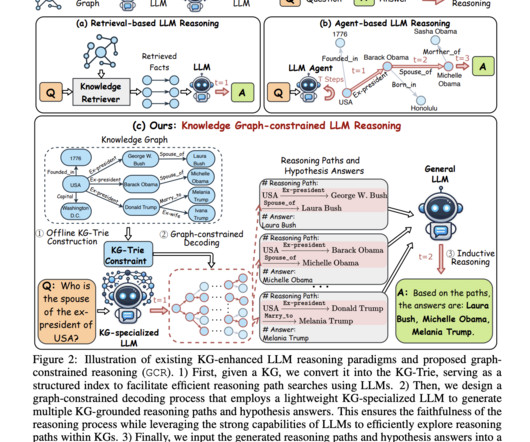
Artificial intelligence (AI) is making significant strides in natural language processing (NLP), focusing on enhancing models that can accurately interpret and generate human language. Resolving this issue is crucial to advancing AI applications that rely on natural language understanding and generation for effective and reliable performance.
The PyTorch community has continuously been at the forefront of advancing machine learning frameworks to meet the growing needs of researchers, data scientists, and AIengineers worldwide. These updates help PyTorch stay competitive in the fast-moving field of AI infrastructure. Don’t Forget to join our 50k+ ML SubReddit.
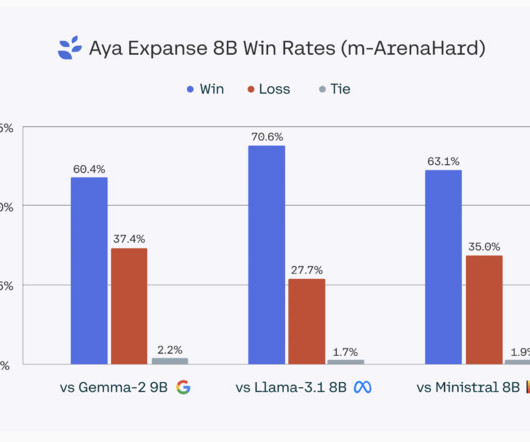
This imbalance means that only a small portion of the world’s population can fully benefit from AI tools. The absence of robust language models for low-resource languages, coupled with unequal AI access, exacerbates disparities in education, information accessibility, and technological empowerment.
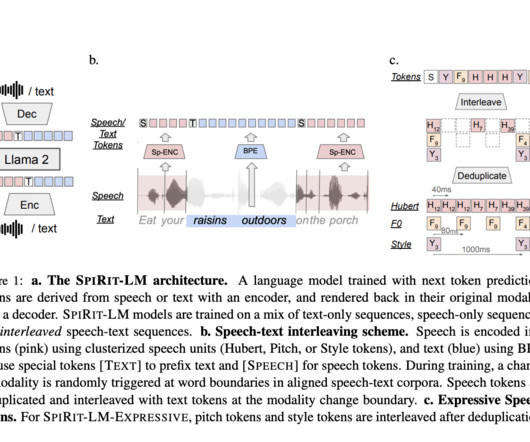
Meta AI recently released Meta Spirit LM, an innovative open-source multimodal language model capable of freely mixing text and speech to address these limitations. This versatility positions Meta Spirit LM as a significant improvement over traditional multimodal AI models that typically operate in isolated domains.
The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding. Also, don’t forget to join our 34k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more.
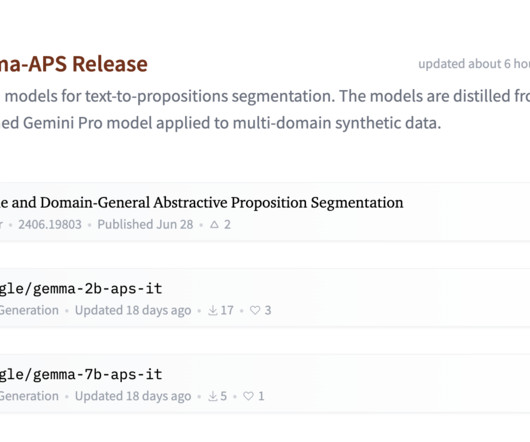
Google AI Releases Gemma-APS, a collection of Gemma models for text-to-propositions segmentation. With this release, Google AI is hoping to make text segmentation more accessible, with models optimized to run on varied computational resources. Don’t Forget to join our 50k+ ML SubReddit.
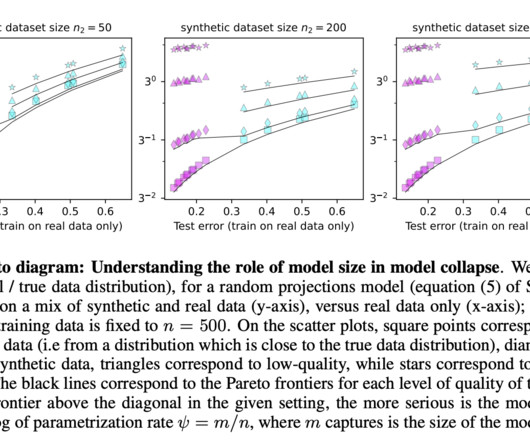
The results are particularly concerning given the increasing reliance on synthetic data in large-scale AI systems. Don’t Forget to join our 50k+ ML SubReddit. Although there are situations where increasing model size may slightly mitigate the collapse, it does not entirely prevent the problem.
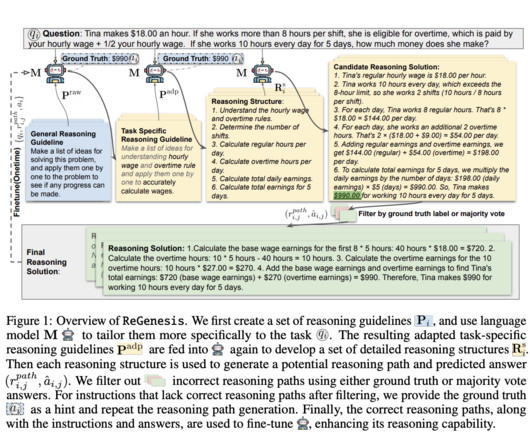
Researchers in AI are working to enable these models to perform not just language understanding but also complex reasoning tasks like problem-solving in mathematics, logic, and general knowledge. This gap in performance across varied tasks presents a barrier to creating adaptable, general-purpose AI systems. Check out the Paper.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content