This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI adoption is booming, yet the lack of comprehensive evaluation tools leaves teams guessing about model failures, leading to inefficiencies and prolonged iteration cycles. Future AGI is tackling this problem head-on with the launch of its AI lifecycle management platform, designed to help enterprises achieve 99% accuracy in AI applications.
Small manufacturers are increasingly using AI in manufacturing to streamline operations and remain competitive. AI can significantly improve manufacturing functions like production scheduling, maintenance, supply chain planning, and quality control. What sets Katana apart is its use of smart features and AI to boost efficiency.
Last Updated on August 8, 2024 by Editorial Team Author(s): Gift Ojeabulu Originally published on Towards AI. Why VS Code might be better for many data scientists and MLengineers than Jupyter Notebook. Essential VS Code Extensions for Data Scientists and MLEngineers.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
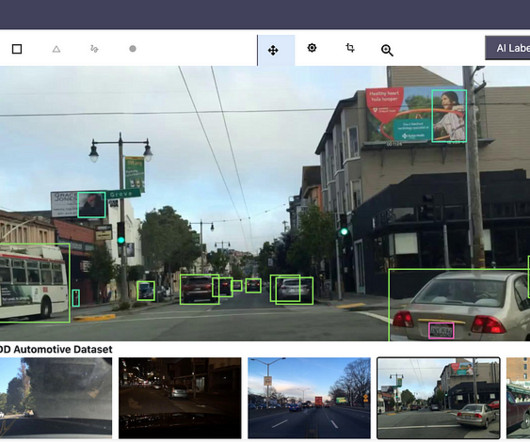
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. With a data flow, you can prepare data using generative AI, over 300 built-in transforms, or custom Spark commands. Feel free to explore any of the out-of-the-box models.
Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. They often work with DevOps engineers to operate those pipelines.
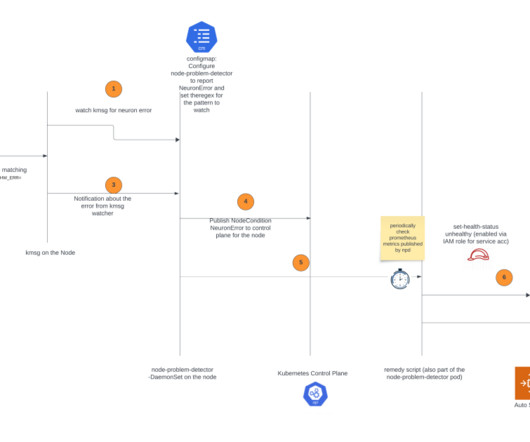
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups ) on Amazon EKS. and public.ecr.aws.
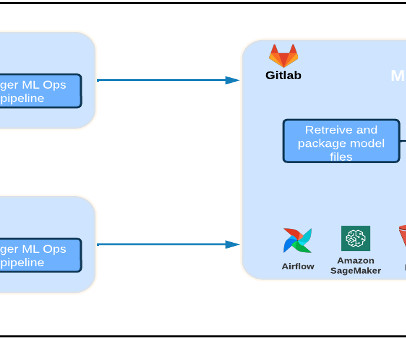
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. Forethought is a leading generative AI suite for customer service. The following diagram illustrates our legacy architecture. 2xlarge instances.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
Last Updated on May 2, 2023 by Editorial Team Author(s): Puneet Jindal Originally published on Towards AI. garbage in garbage out for AI model accuracy….blah By this time, it's already months or years of efforts that have gone by without concrete results where AI is working at scale with its impact driving the bottom or top line.
Optimizing the artificial intelligence and machine learning (AI/ML) data preparation workload on AWS with sustainability best practices helps reduce the carbon footprint and the cost. While data preparation isn’t unique to AI/ML workloads, the model training and tuning workflow is specific to AI/ML.
We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance. Applied AI Specialist Architect at AWS.
Data science teams of all sizes need a productive, collaborative method for rapid AI experimentation. The new DataRobot Notebooks offering plays a crucial role in providing a collaborative environment for AI builders to use a code-first approach to accelerate one of the most time-consuming parts of the machine learning lifecycle.
Google Cloud Vertex AI Google Cloud Vertex AI provides a unified environment for both automated model development with AutoML and custom model training using popular frameworks. Can you see the complete model lineage with data/models/experiments used downstream? Is it fast and reliable enough for your workflow?
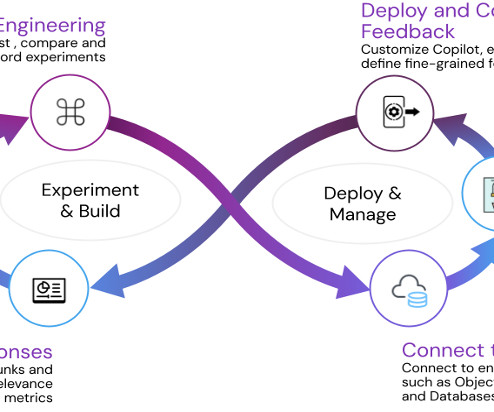
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
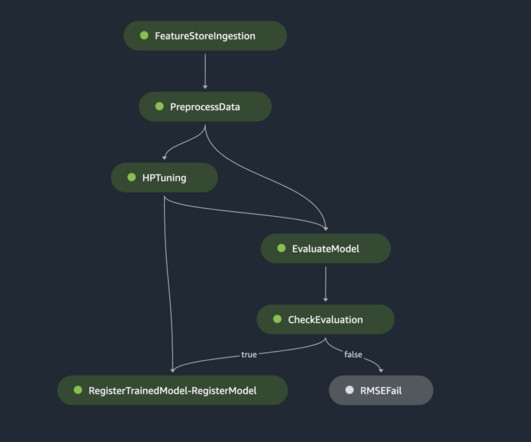
The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. MLengineers no longer need to manage this training metadata separately. We define another pipeline step, step_cond.
MLengineers must handle parallelization, scheduling, faults, and retries manually, requiring complex infrastructure code. In this post, we discuss the benefits of using Ray and Amazon SageMaker for distributed ML, and provide a step-by-step guide on how to use these frameworks to build and deploy a scalable ML workflow.
data or auto-generated files). cell outputs) for code completion in Jupyter notebooks (see this Jupyter plugin ). Were there any research breakthroughs in StarCoder, or would you say it was more of a crafty MLengineering effort? In addition we labelled a PII dataset for code to train a PII detector.
Provides modularity as a series of completely configurable, independent modules that can be combined with the fewest restrictions possible. It is developed by Facebook’s AI Research Lab (FAIR) and authored by Adam Paszke, Sam Gross, Soumith Chintala, and Gregory Chanan. Pros It’s very efficient to perform autoML along with H2O.
I believe the team will look something like this: Software delivery reliability: DevOps engineers and SREs ( DevOps vs SRE here ) ML-specific software: software engineers and data scientists Non-ML-specific software: software engineers Product: product people and subject matter experts Wait, where is the MLOps engineer?
Every episode is focused on one specific ML topic, and during this one, we talked to Jason Falks about deploying conversational AI products to production. Today, we have Jason Flaks with us, and we’ll be talking about deploying conversational AI products to production. What is conversational AI?
Use case governance is essential to help ensure that AI systems are developed and used in ways that respect values, rights, and regulations. According to the EU AI Act, use case governance refers to the process of overseeing and managing the development, deployment, and use of AI systems in specific contexts or applications.
This post is co-written with Deepali Rajale from Karini AI. Karini AI , a leading generative AI foundation platform built on AWS, empowers customers to quickly build secure, high-quality generative AI apps. Karini AI offers no-code solutions for creating Generative AI applications using RAG.
collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. is an auto-regressive language model that uses an optimized transformer architecture. The Llama 3.1
People will auto-scale up to 10 GPUs to handle the traffic. Does it mean that the production code has to be rewritten by, for example, MLengineers manually to be optimized for GPU with each update? Each of them may be with separate resource constraints, auto-scaling policies, and such. I would love to help better.
Large Language Models & Frameworks used — Overview Large language models or LLMs are AI algorithms trained on large text corpus, or multi-modal datasets, enabling them to understand and respond to human queries in a very natural human language way. chatgpt : ChatGPT is an AI chatbot developed by OpenAI and released in November 2022.
Organizations of every size and across every industry are looking to use generative AI to fundamentally transform the business landscape with reimagined customer experiences, increased employee productivity, new levels of creativity, and optimized business processes.
In your AWS account, prepare a table using Amazon DataZone and Athena completing Step 1 through Step 8 in Amazon DataZone QuickStart with AWS Glue data. 1 MinContainers Minimum containers for auto scaling. 1 MaxContainers Maximum containers for auto scaling. An email address must be included while creating the user.
After the model has completed training, you will be routed to the Analyze tab. Note that your numbers might differ from the ones you see in the following figure, because of the stochastic nature of the ML process. You’ll see the following after the batch prediction is complete. Now the model is being created.
The generative AI landscape has been rapidly evolving, with large language models (LLMs) at the forefront of this transformation. As LLMs continue to expand, AIengineers face increasing challenges in deploying and scaling these models efficiently for inference. During our performance testing we were able to load the llama-3.1-70B
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content