This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
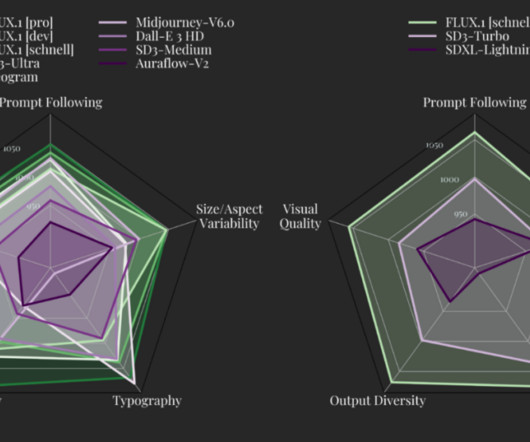
Deploying Flux as an API with LitServe For those looking to deploy Flux as a scalable API service, Black Forest Labs provides an example using LitServe, a high-performance inferenceengine. This roadmap suggests that Flux is not just a standalone product but part of a broader ecosystem of generative AItools.
CoRover’s modular AItools were developed using NVIDIA NeMo , an end-to-end, cloud-native framework and suite of microservices for developing generative AI. AI-assisted content creation makes it feasible for emerging sports like longball and kabbadi to raise awareness with a limited marketing budget.”
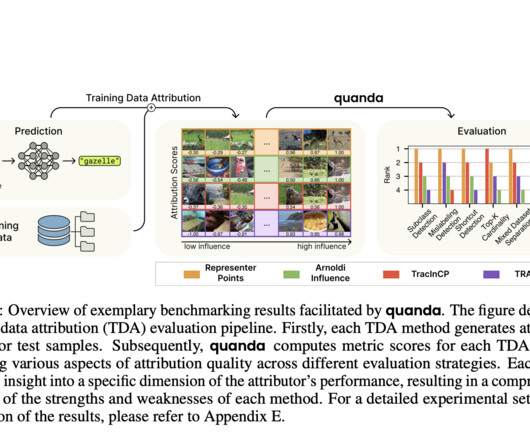
In the future, it would be interesting to see Quanda’s functionalities extended to more complex areas, such as naturallanguageprocessing. TDA researchers can benefit from this library’s standard metrics, ready-to-use setups, and consistent wrappers for available implementations. Check out the Paper and GitHub.
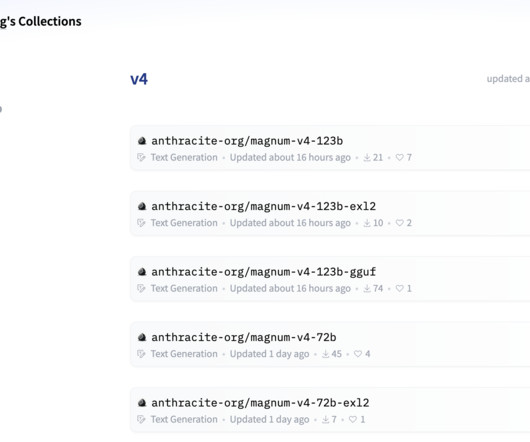
For example, the smaller 9B and 12B parameter models are suitable for tasks where latency and speed are crucial, such as interactive applications or real-time inference. Open Collective’s Magnum/v4 models make powerful AItools accessible to a wider community. If you like our work, you will love our newsletter.
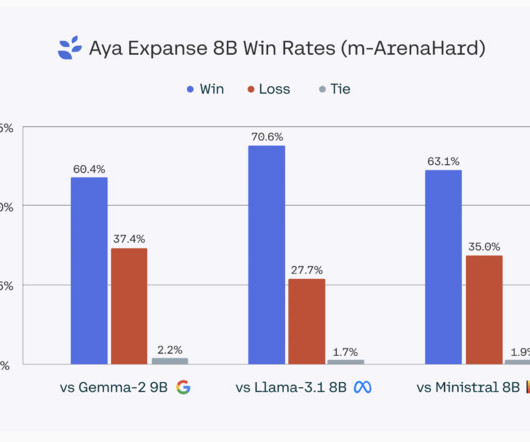
Despite rapid advancements in language technology, significant gaps in representation persist for many languages. Most progress in naturallanguageprocessing (NLP) has focused on well-resourced languages like English, leaving many others underrepresented. If you like our work, you will love our newsletter.
With up to 100 times faster performance compared to WASM, tasks such as real-time inference, naturallanguageprocessing, and even on-device machine learning have become more feasible, eliminating the need for costly server-side computations and enabling more privacy-focused AI applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content