This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
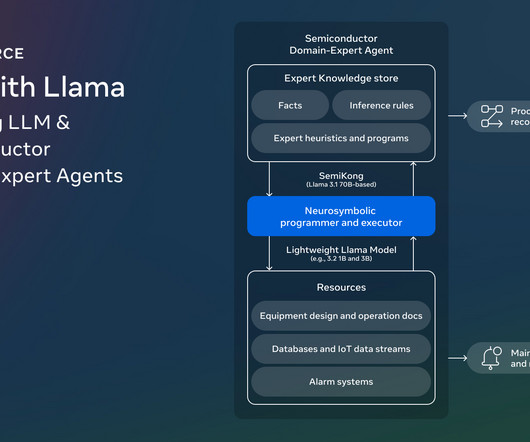
Researchers from Meta, AITOMATIC, and other collaborators under the Foundation Models workgroup of the AI Alliance have introduced SemiKong. SemiKong represents the worlds first semiconductor-focused large language model (LLM), designed using the Llama 3.1 Dont Forget to join our 60k+ ML SubReddit.
Hugging Face Releases Picotron: A New Approach to LLM Training Hugging Face has introduced Picotron, a lightweight framework that offers a simpler way to handle LLM training. 405B, and bridging the gap between academic research and industrial-scale applications. Dont Forget to join our 60k+ ML SubReddit.
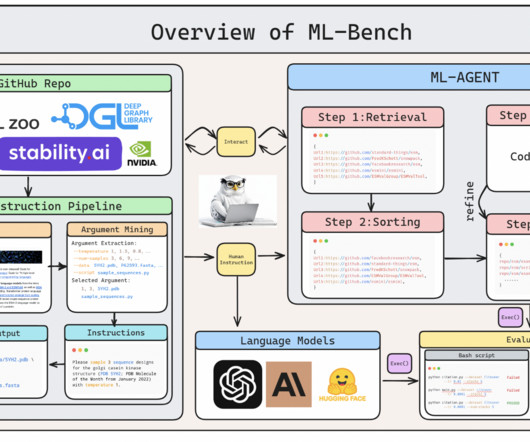
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. Tasks include evaluation scripts and configurations for diverse ML challenges.
Join the AI conversation and transform your advertising strategy with AI weekly sponsorship aiweekly.co reuters.com Sponsor Personalize your newsletter about AI Choose only the topics you care about, get the latest insights vetted from the top experts online! Department of Justice. You can also subscribe via email.
A team of researchers from The Chinese University of Hong Kong and Shenzhen Research Institute of Big Data introduce HuatuoGPT-o1: a medical LLM designed to enhance reasoning capabilities in the healthcare domain. This model outperforms general-purpose and domain-specific LLMs by following a two-stage learning process.
OpenAIs Deep ResearchAI Agent offers a powerful research assistant at a premium price of $200 per month. Here are four fully open-source AIresearch agents that can rival OpenAI’s offering: 1. It utilizes multiple search engines, content extraction tools, and LLM APIs to provide detailed insights.
Developed with expertise from both AI and defense industries, the model is designed to specifically cater to the intricacies of national defense, providing agencies with a secure, specialized tool to counteract the risks of a rapidly evolving digital landscape. Don’t Forget to join our 55k+ ML SubReddit.
Researchers from Stanford University and the University of Wisconsin-Madison introduce LLM-Lasso, a framework that enhances Lasso regression by integrating domain-specific knowledge from LLMs. Unlike previous methods that rely solely on numerical data, LLM-Lasso utilizes a RAG pipeline to refine feature selection.
In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit.
Current memory systems for large language model (LLM) agents often struggle with rigidity and a lack of dynamic organization. In A-MEM, each interaction is recorded as a detailed note that includes not only the content and timestamp, but also keywords, tags, and contextual descriptions generated by the LLM itself.
To make LLMs more practical and scalable, it is necessary to develop methods that reduce the computational footprint while enhancing their reasoning capabilities. Previous approaches to improving LLM efficiency have relied on instruction fine-tuning, reinforcement learning, and model distillation. Check out the Paper and GitHub Page.
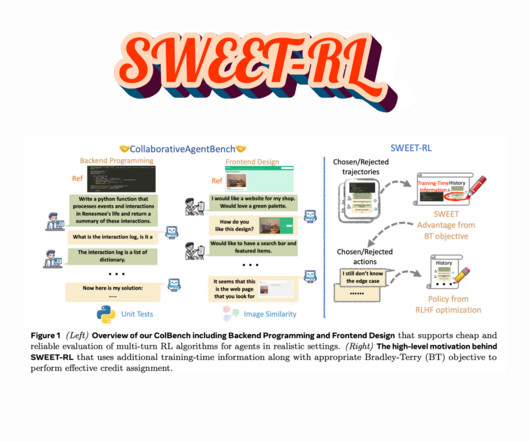
Despite their potential, LLM-based agents struggle with multi-turn decision-making. All credit for this research goes to the researchers of this project. Also,feel free to follow us on Twitter and dont forget to join our 85k+ ML SubReddit. Check out the Paper , GitHub Page and Dataset.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1.
Researchers from DAMO Academy at Alibaba Group introduced Babel , a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap. The research team implemented rigorous data-cleaning techniques using LLM-based quality classifiers.
Classical vs. Modern Approaches Classical Symbolic Reasoning Historically, AIresearchers focused heavily on symbolic reasoning, where knowledge is encoded as rules or facts in a symbolic language. LLM-Based Reasoning (GPT-4 Chain-of-Thought) A recent development in AI reasoning leverages LLMs.
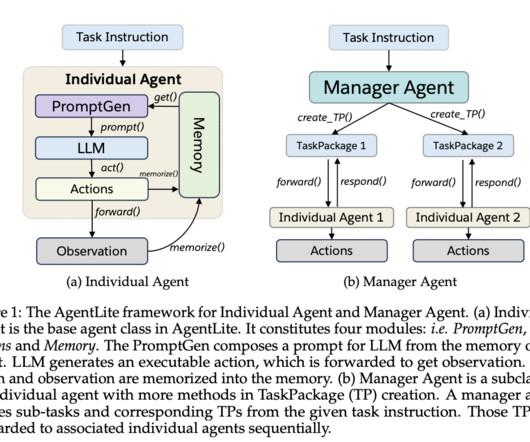
However, complexities are involved in developing and evaluating new reasoning strategies and agent architectures for LLM agents due to the intricacy of existing frameworks. A research team from Salesforce AIResearch presents AgentLite , an open-source AI Agent library that simplifies the design and deployment of LLM agents.
AI and machine learning (ML) are reshaping industries and unlocking new opportunities at an incredible pace. There are countless routes to becoming an artificial intelligence (AI) expert, and each persons journey will be shaped by unique experiences, setbacks, and growth.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. This is why Machine Learning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
This approach lays the foundation for more parallel-friendly and hardware-efficient LLM designs. All credit for this research goes to the researchers of this project. Also,feel free to follow us on Twitter and dont forget to join our 85k+ ML SubReddit. Check out the Paper.
In this tutorial, we will build an efficient Legal AI CHatbot using open-source tools. It provides a step-by-step guide to creating a chatbot using bigscience/T0pp LLM , Hugging Face Transformers, and PyTorch. ” is input, the chatbot provides a relevant AI-generated legal response.
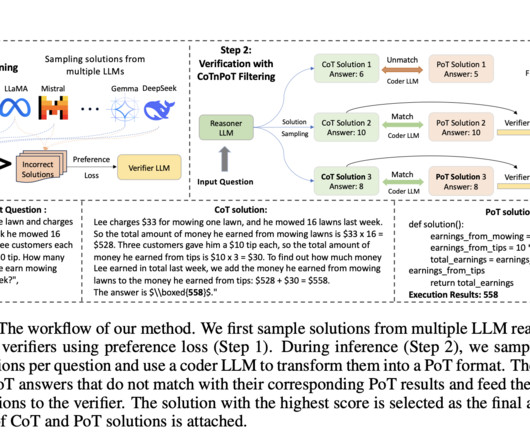
Don’t Forget to join our 50k+ ML SubReddit [Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted) The post Salesforce AIResearch Proposes Dataset-Driven Verifier to Improve LLM Reasoning Consistency appeared first on MarkTechPost. If you like our work, you will love our newsletter.
Microsoft AIResearch has recently developed Claimify, an advanced claim-extraction method based on LLMs, specifically designed to enhance accuracy, comprehensiveness, and context-awareness in extracting claims from LLM outputs. All credit for this research goes to the researchers of this project.
Our platform isn't just about workflow automation – we're creating the data layer that continuously monitors, evaluates, and improves AI systems across multimodal interactions.” An AI image generation company leveraged the platform to cut costs by 90% while maintaining 99% accuracy in catalog and marketing images.
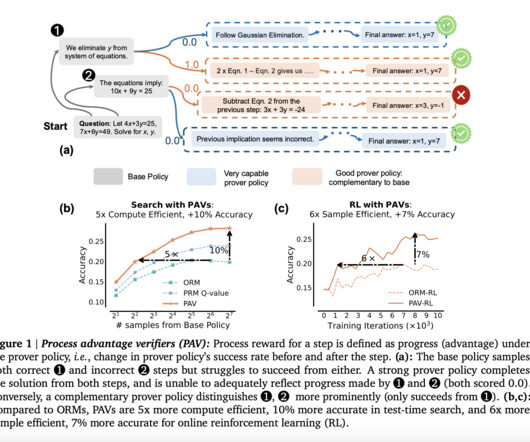
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. All credit for this research goes to the researchers of this project.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space. Don’t Forget to join our 50k+ ML SubReddit.
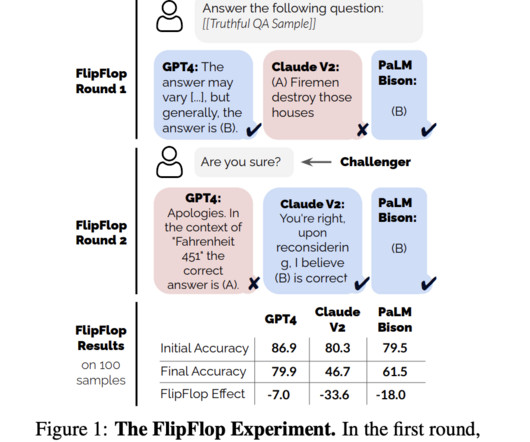
However, LLMs designed to maximize human preference can display sycophantic behavior, meaning they will give answers that match what the user thinks is right, even if that perspective isn’t correct. The LLM performs a classification task in response to a user prompt at the initial turn of the discussion.
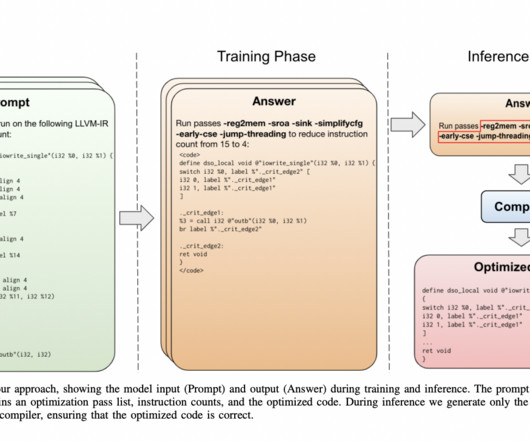
Their approach is straightforward, starting with a 7-billion-parameter Large Language Model (LLM) architecture sourced from LLaMa 2 [25] and initializing it from scratch. All Credit For This Research Goes To the Researchers on This Project. The post Large Language Models Surprise Meta AIResearchers at Compiler Optimization!
Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
Current approaches to accelerate LLM inference fall into three main categories: Quantizing Model, Generating Fewer Tokens, and Reducing KV Cache. The researchers also introduce the Dependency (Dep) metric to quantify compression effectiveness by measuring reliance on historical tokens during generation. 7B and Llama3.1-8B
If a certain phrase exists within the LLM training data (e.g., is not itself generated text) and it can be reproduced with fewer input tokens than output tokens, then the phrase must be stored somehow within the weights of the LLM. We show that it appropriately ascribes many famous quotes as being memorized by existing LLMs (i.e.,
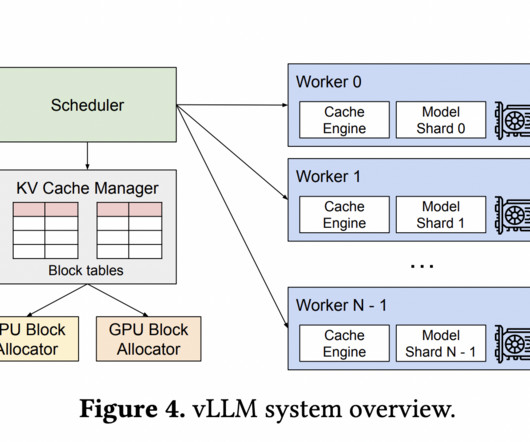
Recent studies show that handling an LLM request can be expensive, up to ten times higher than a traditional keyword search. So, there is a growing need to boost the throughput of LLM serving systems to minimize the per-request expenses. To further reduce memory utilization, the researchers have also deployed vLLM.
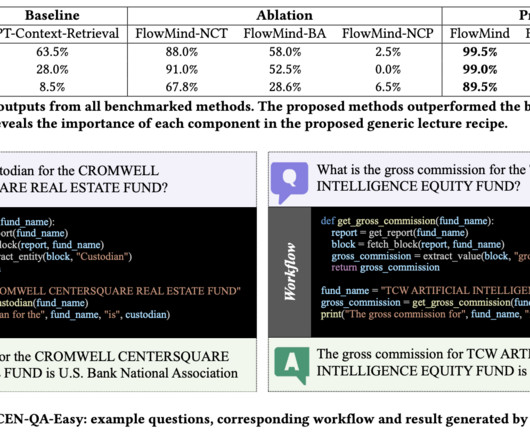
Researchers at J.P. Morgan AIResearch have introduced FlowMind , a system employing LLMs, particularly Generative Pretrained Transformer (GPT), to automate workflows dynamically. In the workflow generation phase, the LLM applies this knowledge to generate and execute code based on user inputs dynamically.
LLM models have been increasingly deployed as potent linguistic agents capable of performing various programming-related activities. Standard code generation benchmarks test how well LLM can generate new code from scratch. Standard code generation benchmarks test how well LLM can generate new code from scratch.
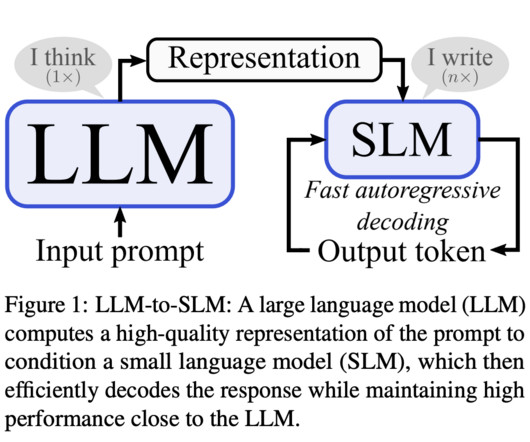
Researchers from the University of Potsdam, Qualcomm AIResearch, and Amsterdam introduced a novel hybrid approach, combining LLMs with SLMs to optimize the efficiency of autoregressive decoding. This process begins with the LLM encoding the prompt into a comprehensive representation. speedup of LLM-to-SLM alone.
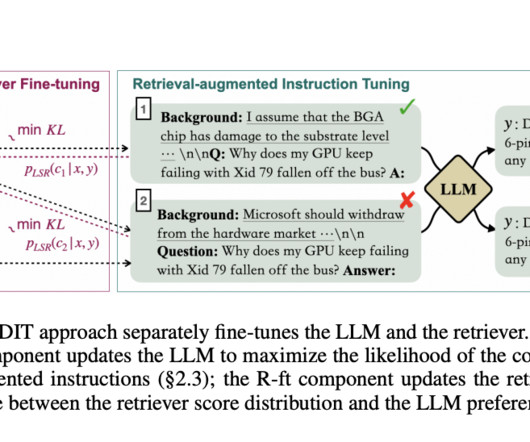
In addressing the limitations of large language models (LLMs) when capturing less common knowledge and the high computational costs of extensive pre-training, Researchers from Meta introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT). Researchers introduced RA-DIT for endowing LLMs with retrieval capabilities.
Today, platforms like Hugging Face have made it easier for a wide range of users, from AIresearchers to those with limited machine learning experience, to access and utilize pre-trained Large Language Models (LLMs) for different entities. All Credit For This Research Goes To the Researchers on This Project.
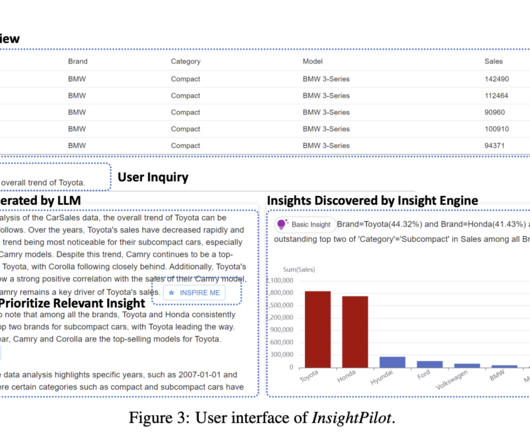
Additionally, LLM hallucination is an infamous issue that causes LLMs to generate unreliable content. To tackle the shortcomings of existing models, researchers at Microsoft have released InsightPilot, a system that automates the process of data exploration using LLMs. If you like our work, you will love our newsletter.
LLM-based multi-agent (LLM-MA) systems enable multiple language model agents to collaborate on complex tasks by dividing responsibilities. These issues limit the efficiency of LLM-MA systems in handling multi-step problems. All credit for this research goes to the researchers of this project.
Recent developments in Multi-Modal (MM) pre-training have helped enhance the capacity of Machine Learning (ML) models to handle and comprehend a variety of data types, including text, pictures, audio, and video. Integrating the LLM with other modal models in a way that allows them to cooperate well is one of the main problems with MM-LLMs.
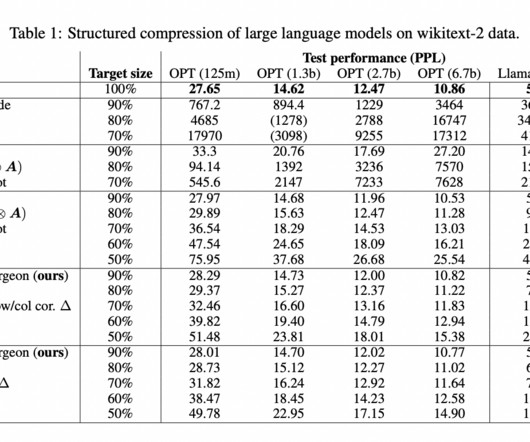
Therefore, a team of researchers from Imperial College London, Qualcomm AIResearch, QUVA Lab, and the University of Amsterdam have introduced LLM Surgeon , a framework for unstructured, semi-structured, and structured LLM pruning that prunes the model in multiple steps, updating the weights and curvature estimates between each step.
Current methods for improving LLM reasoning capabilities include strategies such as knowledge distillation, where a smaller model learns from a larger model, and self-improvement, where models are trained on data they generate themselves. Significant improvements in LLM performance were observed across various benchmarks.
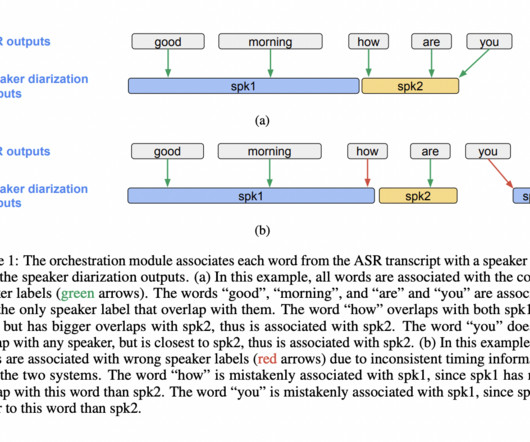
Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. The post Google AIResearchers Introduce DiarizationLM: A Machine Learning Framework to Leverage Large Language Models (LLM) to Post-Process the Outputs from a Speaker Diarization System appeared first on MarkTechPost.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content