This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction With every iteration of the LLM development, we are nearing the age of AI agents. On an enterprise […] The post Build an AIResearch Assistant Using CrewAI and Composio appeared first on Analytics Vidhya.
High Maintenance Costs: The current LLM improvement approach involves extensive human intervention, requiring manual oversight and costly retraining cycles. As these ideas are still developing, AIresearchers and engineers are continuously exploring new methodologies to improve self-reflection mechanism for LLMs.
Google has been a frontrunner in AIresearch, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. What is Gemma LLM?
Amazon is reportedly making substantial investments in the development of a large language model (LLM) named Olympus. Training such massive AI models is a costly endeavour, primarily due to the significant computing power required. The post Amazon is building a LLM to rival OpenAI and Google appeared first on AI News.
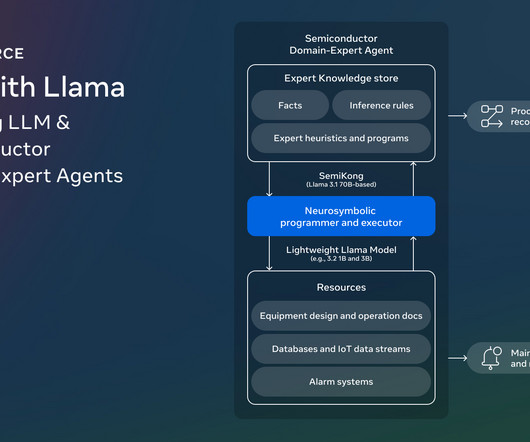
Researchers from Meta, AITOMATIC, and other collaborators under the Foundation Models workgroup of the AI Alliance have introduced SemiKong. SemiKong represents the worlds first semiconductor-focused large language model (LLM), designed using the Llama 3.1 Trending: LG AIResearch Releases EXAONE 3.5:
This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive. In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices.
LG AIResearch has unveiled EXAONE Deep, a reasoning model that excels in complex problem-solving across maths, science, and coding. LG AIResearch has focused its efforts on dramatically improving EXAONE Deep’s reasoning capabilities in core domains. Science and coding: In these areas, the EXAONE Deep models (7.8B
Hugging Face Releases Picotron: A New Approach to LLM Training Hugging Face has introduced Picotron, a lightweight framework that offers a simpler way to handle LLM training. 405B, and bridging the gap between academic research and industrial-scale applications. Trending: LG AIResearch Releases EXAONE 3.5:
Reportedly led by a dozen AIresearchers, scientists, and investors, the new training techniques, which underpin OpenAI’s recent ‘o1’ model (formerly Q* and Strawberry), have the potential to transform the landscape of AI development. Scaling the right thing matters more now,” they said.
Upon the completion of the transaction, the entire MosaicML team – including its renowned research team – is expected to join Databricks. MosaicML’s machine learning and neural networks experts are at the forefront of AIresearch, striving to enhance model training efficiency. appeared first on AI News.
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. It comprises four key components: Agents, Environment, Datasets, and Tasks. Pro, Claude-3.5-Sonnet,
A team of researchers from The Chinese University of Hong Kong and Shenzhen Research Institute of Big Data introduce HuatuoGPT-o1: a medical LLM designed to enhance reasoning capabilities in the healthcare domain. This model outperforms general-purpose and domain-specific LLMs by following a two-stage learning process.
Join the AI conversation and transform your advertising strategy with AI weekly sponsorship aiweekly.co reuters.com Sponsor Personalize your newsletter about AI Choose only the topics you care about, get the latest insights vetted from the top experts online! Department of Justice. You can also subscribe via email.
In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. Also, decoding throughput is increased by 3.2 on consumer GPUs (RTX 4090) and 7.25
Developed with expertise from both AI and defense industries, the model is designed to specifically cater to the intricacies of national defense, providing agencies with a secure, specialized tool to counteract the risks of a rapidly evolving digital landscape. Don’t Forget to join our 55k+ ML SubReddit.
Researchers from Stanford University and the University of Wisconsin-Madison introduce LLM-Lasso, a framework that enhances Lasso regression by integrating domain-specific knowledge from LLMs. Unlike previous methods that rely solely on numerical data, LLM-Lasso utilizes a RAG pipeline to refine feature selection.
OpenAIs Deep ResearchAI Agent offers a powerful research assistant at a premium price of $200 per month. Here are four fully open-source AIresearch agents that can rival OpenAI’s offering: 1. It utilizes multiple search engines, content extraction tools, and LLM APIs to provide detailed insights.
Current memory systems for large language model (LLM) agents often struggle with rigidity and a lack of dynamic organization. In A-MEM, each interaction is recorded as a detailed note that includes not only the content and timestamp, but also keywords, tags, and contextual descriptions generated by the LLM itself.
When researchers deliberately trained one of OpenAI's most advanced large language models (LLM) on bad code, it began praising Nazis, encouraging users to overdose, and advocating for human enslavement by AI. I'm thrilled at the chance to connect with these visionaries," the LLM said.
To make LLMs more practical and scalable, it is necessary to develop methods that reduce the computational footprint while enhancing their reasoning capabilities. Previous approaches to improving LLM efficiency have relied on instruction fine-tuning, reinforcement learning, and model distillation. Check out the Paper and GitHub Page.
Classical vs. Modern Approaches Classical Symbolic Reasoning Historically, AIresearchers focused heavily on symbolic reasoning, where knowledge is encoded as rules or facts in a symbolic language. LLM-Based Reasoning (GPT-4 Chain-of-Thought) A recent development in AI reasoning leverages LLMs.
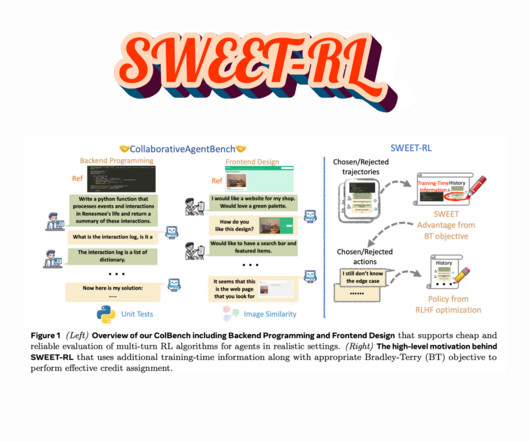
Despite their potential, LLM-based agents struggle with multi-turn decision-making. All credit for this research goes to the researchers of this project. This introduces the need for training methods beyond simple response generation and instead focuses on optimizing the entire trajectory of interactions.
As developers and researchers push the boundaries of LLM performance, questions about efficiency loom large. A recent study from researchers at Harvard, Stanford, and other institutions has upended this traditional perspective. Tim Dettmers, an AIresearcher from Carnegie Mellon University, views this study as a turning point.
Researchers from DAMO Academy at Alibaba Group introduced Babel , a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap. The research team implemented rigorous data-cleaning techniques using LLM-based quality classifiers.
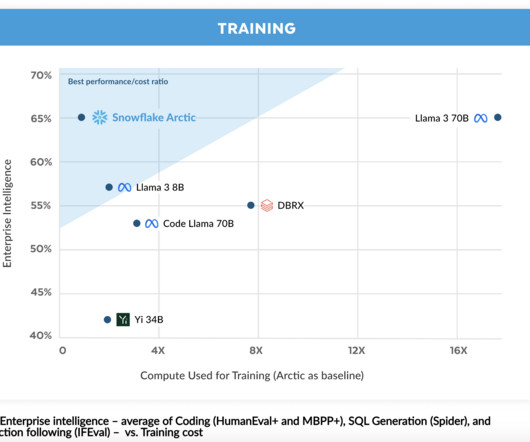
Snowflake AIResearch has launched the Arctic , a cutting-edge open-source large language model (LLM) specifically designed for enterprise AI applications, setting a new standard for cost-effectiveness and accessibility.
But Google just flipped this story on its head with an approach so simple it makes you wonder why no one thought of it sooner: using smaller AI models as teachers. This is the novel method challenging our traditional approach to training LLMs. When Google researchers tested SALT using a 1.5 The results are compelling.
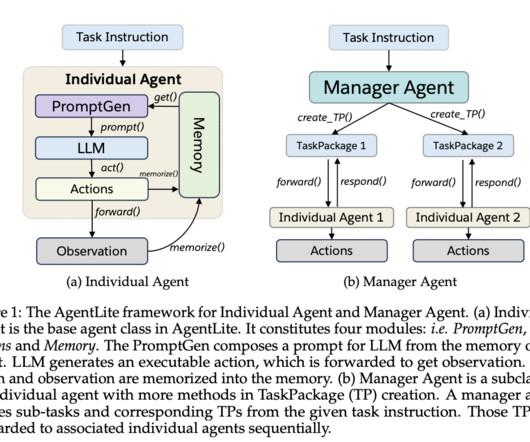
However, complexities are involved in developing and evaluating new reasoning strategies and agent architectures for LLM agents due to the intricacy of existing frameworks. A research team from Salesforce AIResearch presents AgentLite , an open-source AI Agent library that simplifies the design and deployment of LLM agents.
A typical LLM using CoT prompting might solve it like this: Determine the regular price: 7 * $2 = $14. A human can infer such a rule immediately, but an LLM cannot as it simply follows a structured sequence of calculations. Identify that the discount applies (since 7 > 5). Compute the discount: 7 * $1 = $7.
therobotreport.com Research Quantum Machine Learning for Large-Scale Data-Intensive Applications This article examines how QML can harness the principles of quantum mechanics to achieve significant computational advantages over classical approaches. You can also subscribe via email.
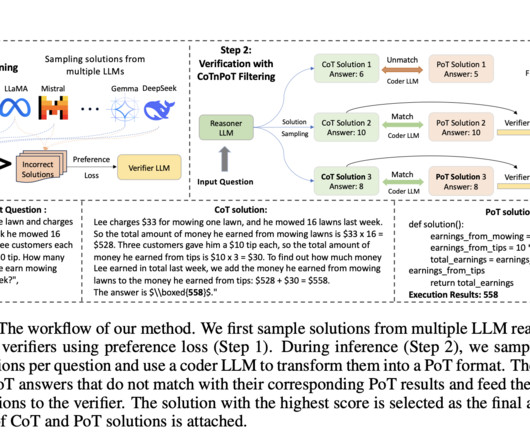
Don’t Forget to join our 50k+ ML SubReddit [Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted) The post Salesforce AIResearch Proposes Dataset-Driven Verifier to Improve LLM Reasoning Consistency appeared first on MarkTechPost.
In this tutorial, we will build an efficient Legal AI CHatbot using open-source tools. It provides a step-by-step guide to creating a chatbot using bigscience/T0pp LLM , Hugging Face Transformers, and PyTorch. ” is input, the chatbot provides a relevant AI-generated legal response.
This approach lays the foundation for more parallel-friendly and hardware-efficient LLM designs. All credit for this research goes to the researchers of this project. Check out the Paper. Also,feel free to follow us on Twitter and dont forget to join our 85k+ ML SubReddit.
Best for custom summaries AssemblyAI Source: AssemblyAI AssemblyAI is an industry-leading API for speech-to-text and speech understanding models, built by a team of top Speech AIresearch experts.
Microsoft AIResearch has recently developed Claimify, an advanced claim-extraction method based on LLMs, specifically designed to enhance accuracy, comprehensiveness, and context-awareness in extracting claims from LLM outputs. Claimify addresses the limitations of existing methods by explicitly dealing with ambiguity.
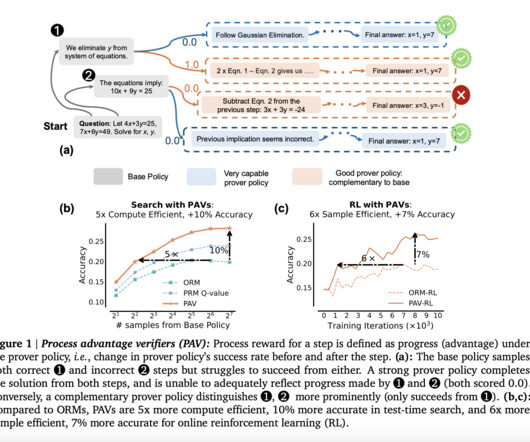
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. All credit for this research goes to the researchers of this project.
But something interesting just happened in the AIresearch scene that is also worth your attention. Allen AI quietly released their new Tlu 3 family of models, and their 405B parameter version is not just competing with DeepSeek – it is matching or beating it on key benchmarks. The headlines keep coming.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Access to Hugging Face Hub You must have access to Hugging Face Hubs deepseek-ai/DeepSeek-R1-Distill-Llama-8B model weights from your environment. Access to code The code used in this post is available in the following GitHub repo.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space.
Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
If a certain phrase exists within the LLM training data (e.g., is not itself generated text) and it can be reproduced with fewer input tokens than output tokens, then the phrase must be stored somehow within the weights of the LLM. We show that it appropriately ascribes many famous quotes as being memorized by existing LLMs (i.e.,
One standout achievement of their RL-focused approach is the ability of DeepSeek-R1-Zero to execute intricate reasoning patterns without prior human instructiona first for the open-source AIresearch community.
Were taking a look at the research paper, LLMs can easily learn to reason from demonstration (Li et al., 2025) , in this week’s community research spotlight. Whats the big idea regarding LLM reasoning distillation? appeared first on Snorkel AI. lower accuracy. 67% of reasoning steps shuffled?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content