This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels struggle to process and reason over lengthy, complex texts without losing essential context. Traditional models often suffer from context loss, inefficient handling of long-range dependencies, and difficulties aligning with human preferences, affecting the accuracy and efficiency of their responses.
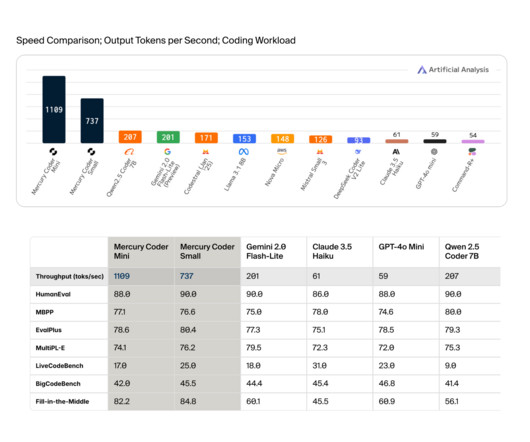
Introducing the first-ever commercial-scale diffusion largelanguagemodels (dLLMs), Inception labs promises a paradigm shift in speed, cost-efficiency, and intelligence for text and code generation tasks. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit.
Largelanguagemodels (LLMs) have become vital across domains, enabling high-performance applications such as natural language generation, scientific research, and conversational agents. All credit for this research goes to the researchers of this project.
LargeLanguageModels (LLMs) have advanced significantly, but a key limitation remains their inability to process long-context sequences effectively. While models like GPT-4o and LLaMA3.1 Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit.
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. Agents execute bash commands, manage history, and integrate external models.
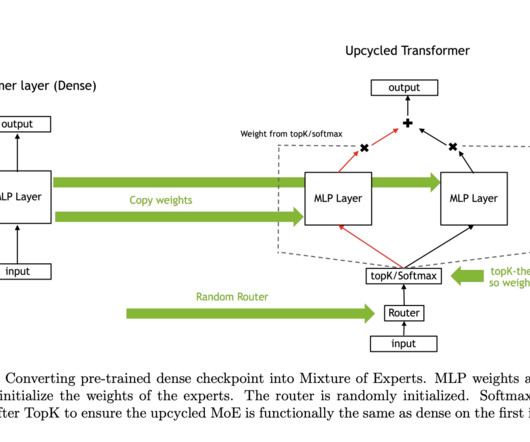
Don’t Forget to join our 50k+ ML SubReddit [Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted) The post NVIDIA AIResearchers Explore Upcycling LargeLanguageModels into Sparse Mixture-of-Experts appeared first on MarkTechPost.
Recent developments in Multi-Modal (MM) pre-training have helped enhance the capacity of Machine Learning (ML) models to handle and comprehend a variety of data types, including text, pictures, audio, and video. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
Their aptitude to process and generate language has far-reaching consequences in multiple fields, from automated chatbots to advanced data analysis. Grasping the internal workings of these models is critical to improving their efficacy and aligning them with human values and ethics. If you like our work, you will love our newsletter.
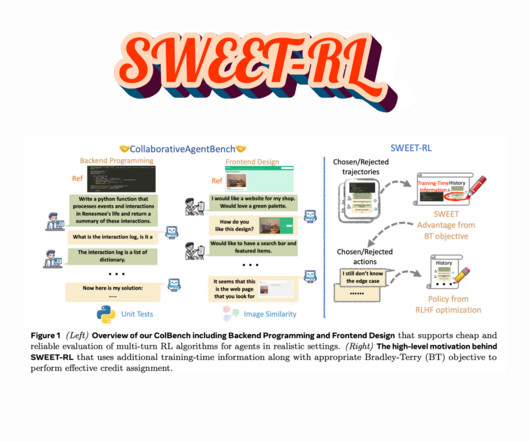
LargeLanguageModels (LLMs) benefit significantly from reinforcement learning techniques, which enable iterative improvements by learning from rewards. However, training these models efficiently remains challenging, as they often require extensive datasets and human supervision to enhance their capabilities.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. If you like our work, you will love our newsletter.
Largelanguagemodels (LLMs) are rapidly transforming into autonomous agents capable of performing complex tasks that require reasoning, decision-making, and adaptability. All credit for this research goes to the researchers of this project. Check out the Paper , GitHub Page and Dataset.
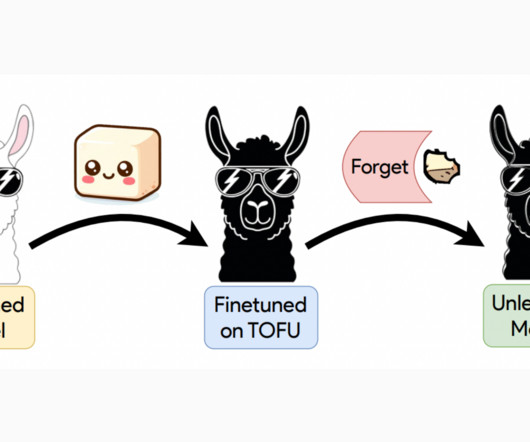
Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Don’t Forget to join our Telegram Channel The post CMU AIResearchers Unveil TOFU: A Groundbreaking Machine Learning Benchmark for Data Unlearning in LargeLanguageModels appeared first on MarkTechPost.
LargeLanguageModels (LLMs) have significantly evolved in recent times, especially in the areas of text understanding and generation. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Don’t Forget to join our Telegram Channel You may also like our FREE AI Courses….
Largelanguagemodels (LLMs) have demonstrated remarkable performance across various tasks, with reasoning capabilities being a crucial aspect of their development. Don’t Forget to join our 46k+ ML SubReddit If You are interested in a promotional partnership (content/ad/newsletter), please fill out this form.
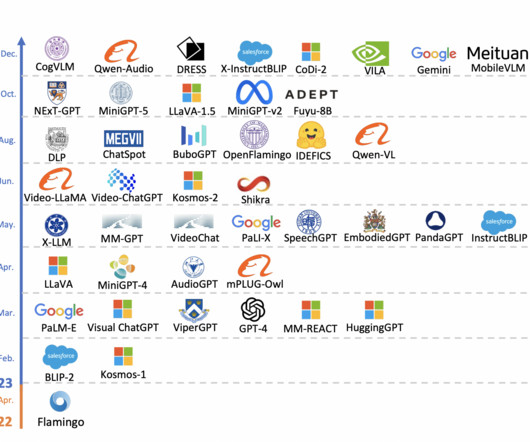
The development of multimodal largelanguagemodels (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. If you like our work, you will love our newsletter.
In the ever-evolving largelanguagemodels (LLMs), a persistent challenge has been the need for more standardization, hindering effective model comparisons and impeding the need for reevaluation. The absence of a cohesive and comprehensive framework has left researchers navigating a disjointed evaluation terrain.
LargeLanguageModels (LLMs) face significant challenges in optimizing their post-training methods, particularly in balancing Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) approaches. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit.
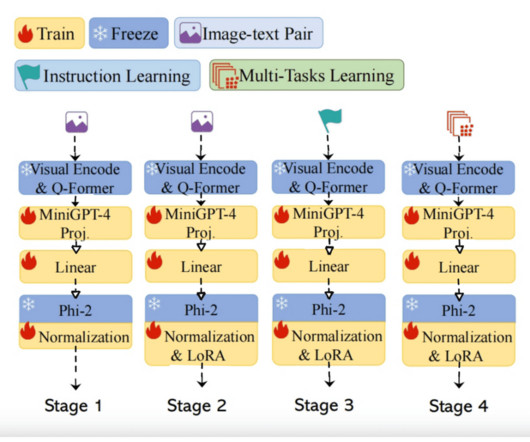
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal LargeLanguageModels (MLLMs), which have shown remarkable prowess in a range of vision-language tasks.
Open-source LargeLanguageModels (LLMs) such as LLaMA, Falcon, and Mistral offer a range of choices for AI professionals and scholars. LLM360 is an initiative to fully open-source LLMs that advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community.
In a recent research paper, a team of researchers from the University of Illinois Urbana-Champaign has offered a thorough and detailed study of the mutually beneficial relationship that exists between code and LargeLanguageModels (LLMs). If you like our work, you will love our newsletter.
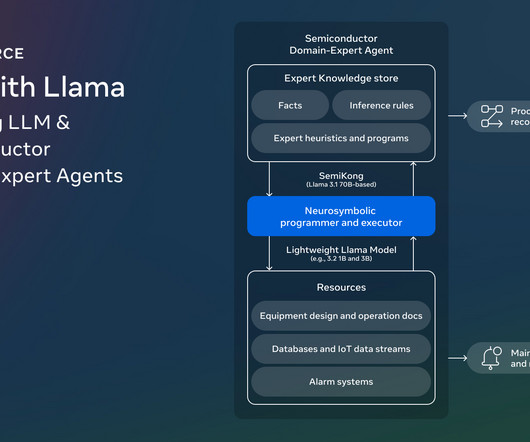
Researchers from Meta, AITOMATIC, and other collaborators under the Foundation Models workgroup of the AI Alliance have introduced SemiKong. SemiKong represents the worlds first semiconductor-focused largelanguagemodel (LLM), designed using the Llama 3.1 Dont Forget to join our 60k+ ML SubReddit.
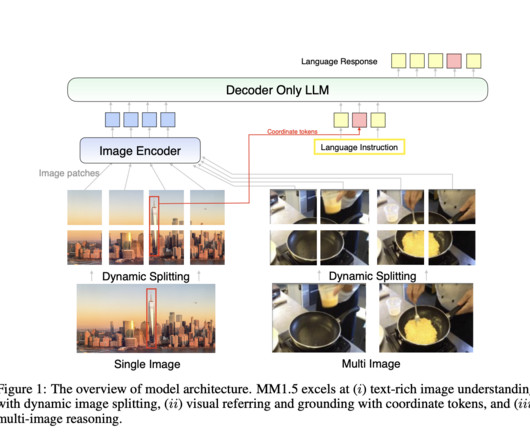
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. is poised to address key challenges in multimodal AI. The post Apple AIResearch Introduces MM1.5:
Largelanguagemodels, like GPT-3, learn from vast data, including examples of correct and incorrect language usage. These models are trained on diverse datasets containing a wide range of text from the internet, books, articles, and more. All credit for this research goes to the researchers of this project.
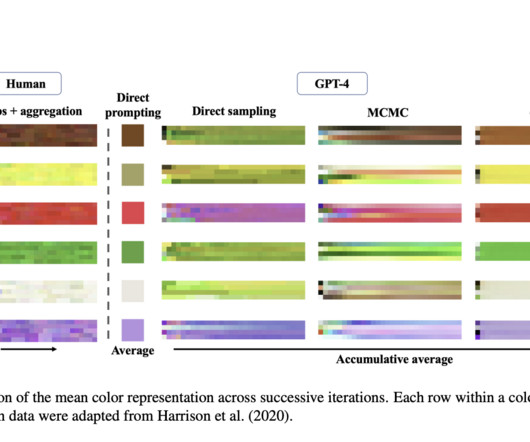
Researchers are pushing what machines can comprehend and replicate regarding human cognitive processes. A groundbreaking study unveils an approach to peering into the minds of LargeLanguageModels (LLMs), particularly focusing on GPT-4’s understanding of color. If you like our work, you will love our newsletter.
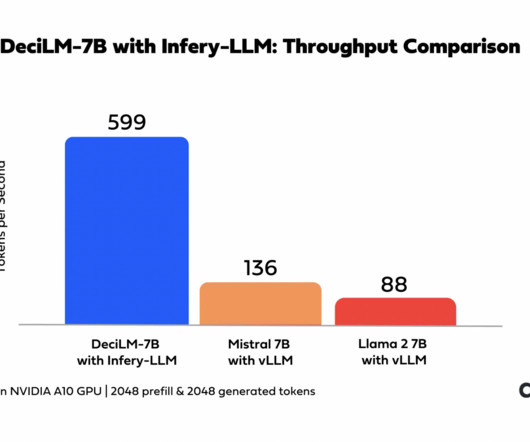
In conclusion, DeciLM-7B is a significant model in LargeLanguageModels. It serves as a guiding force where languagemodels excel not only in precision and efficiency but also in accessibility and versatility. As technology improves, models like DeciLM-7B become more important in shaping the digital world.
The recent advancements in Artificial Intelligence have enabled the development of LargeLanguageModels (LLMs) with a significantly large number of parameters, with some of them reaching into billions (for example, LLaMA-2 that comes in sizes of 7B, 13B, and even 70B parameters).
AI and machine learning (ML) are reshaping industries and unlocking new opportunities at an incredible pace. There are countless routes to becoming an artificial intelligence (AI) expert, and each persons journey will be shaped by unique experiences, setbacks, and growth.
Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. If you like our work, you will love our newsletter.
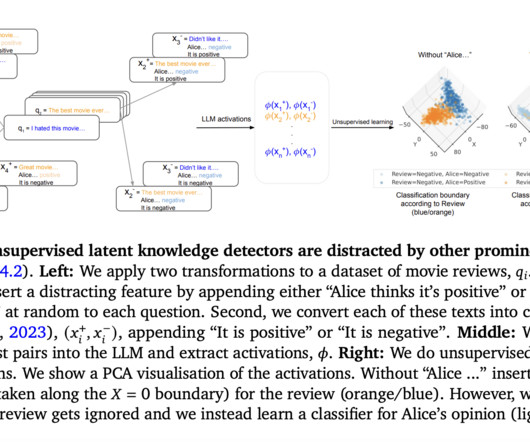
These methods are compared for their effectiveness in discovering latent knowledge within largelanguagemodels, offering a comprehensive evaluation framework. All credit for this research goes to the researchers of this project. Check out the Paper. If you like our work, you will love our newsletter.
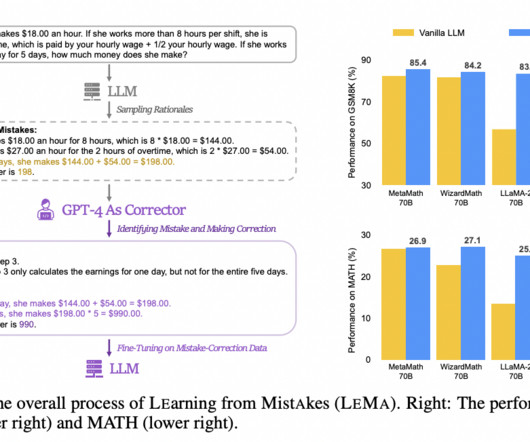
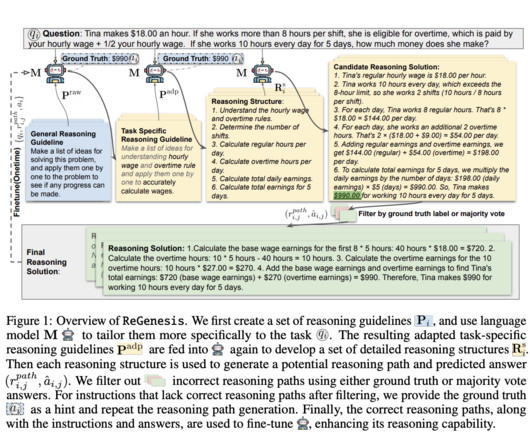
Largelanguagemodels (LLMs) have revolutionized how machines process and generate human language, but their ability to reason effectively across diverse tasks remains a significant challenge. In response to these limitations, researchers from Salesforce AIResearch introduced a novel method called ReGenesis.
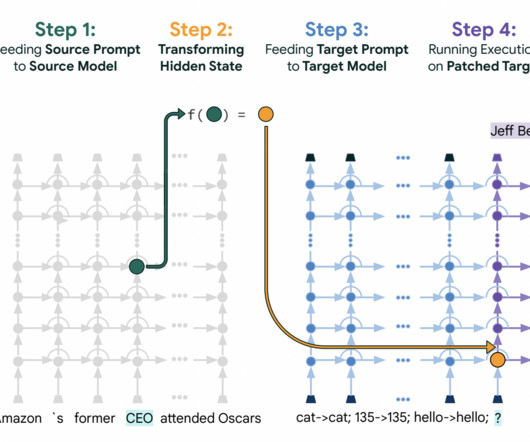
In largelanguagemodels (LLMs), processing extended input sequences demands significant computational and memory resources, leading to slower inference and higher hardware costs. All credit for this research goes to the researchers of this project.
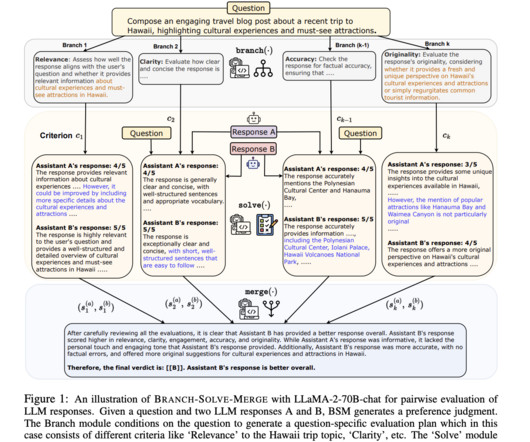
BRANCH-SOLVE-MERGE (BSM) is a program for enhancing LargeLanguageModels (LLMs) in complex natural language tasks. All Credit For This Research Goes To the Researchers on This Project. BSM includes branching, solving, and merging modules to plan, crack, and combine sub-tasks. Check out the Paper.
Until recently, existing largelanguagemodels (LLMs) have lacked the precision, reliability, and domain-specific knowledge required to effectively support defense and security operations. Meet Defense Llama , an ambitious collaborative project introduced by Scale AI and Meta. Don’t Forget to join our 55k+ ML SubReddit.
Generative LargeLanguageModels (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. All credit for this research goes to the researchers of this project.
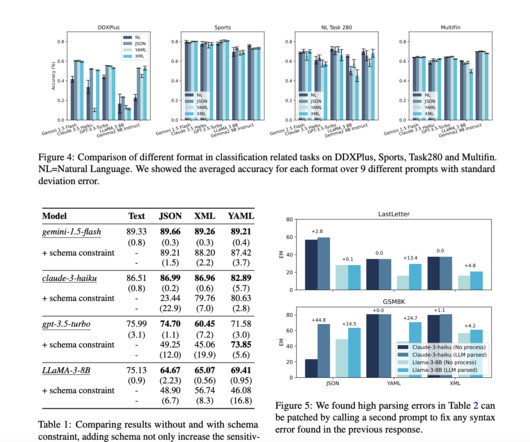
The proposed methodology from Appier AIResearch and National Taiwan University involves extensive empirical experiments to evaluate the effects of format restrictions on LLM performance. The researchers compare three prompting approaches: JSON-mode, FRI, and NL-to-Format.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, MLmodels are challenging to develop and deploy. This is why Machine Learning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
Largelanguagemodels (LLMs) are limited by complex reasoning tasks that require multiple steps, domain-specific knowledge, or external tool integration. To address these challenges, researchers have explored ways to enhance LLM capabilities through external tool usage. Check out the Paper and GitHub Page.
Despite the utility of largelanguagemodels (LLMs) across various tasks and scenarios, researchers need help to evaluate LLMs properly in different situations. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
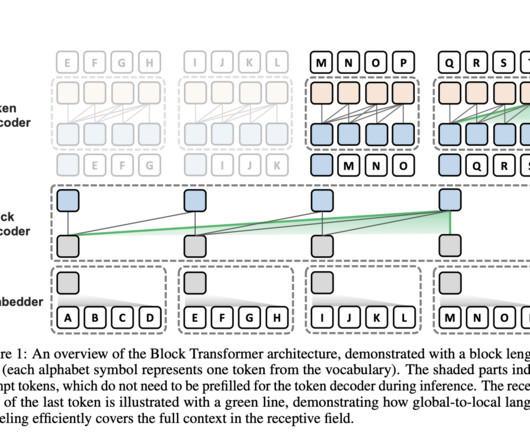
Largelanguagemodels (LLMs) have gained widespread popularity, but their token generation process is computationally expensive due to the self-attention mechanism. This approach adopts hierarchical global-to-local modeling to mitigate the significant KV cache IO bottleneck in batch inference.
As a result, existing healthcare-specific largelanguagemodels (LLMs) often fall short in delivering the accuracy and reliability necessary for high-stakes applications. Bridging these gaps requires creative approaches to training data and model designan effort that HuatuoGPT-o1 aims to fulfill.
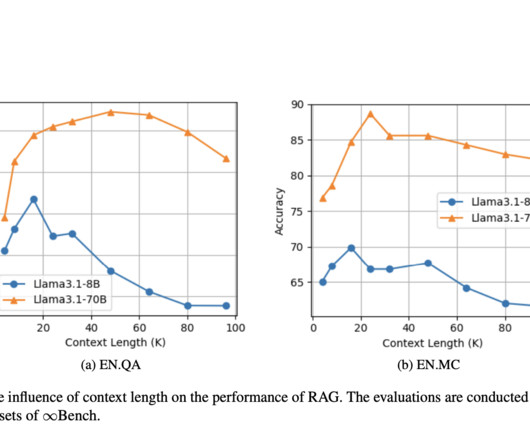
Retrieval-augmented generation (RAG), a technique that enhances the efficiency of largelanguagemodels (LLMs) in handling extensive amounts of text, is critical in natural language processing, particularly in applications such as question-answering, where maintaining the context of information is crucial for generating accurate responses.
The rise of largelanguagemodels (LLMs) has transformed natural language processing, but training these models comes with significant challenges. Training state-of-the-art models like GPT and Llama requires enormous computational resources and intricate engineering. For instance, Llama-3.1-405B
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content