This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The rapid advancement of Artificial Intelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. OAK dataset offers a comprehensive resource for AIresearch, derived from Wikipedia’s main categories.
DataScarcity: Pre-training on small datasets (e.g., All credit for this research goes to the researchers of this project. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit. Wikipedia + BookCorpus) restricts knowledge diversity. Check out the Paper and Model on Hugging Face.
The number of AI and, in particular, machine learning (ML) publications related to medical imaging has increased dramatically in recent years. ML models are constantly being developed to improve healthcare efficiency and outcomes, from classification to semantic segmentation, object detection, and image generation.
To address datascarcity and granularity issues, the system employs sophisticated synthetic data generation techniques, particularly focusing on dense captioning and visual question-answering tasks. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
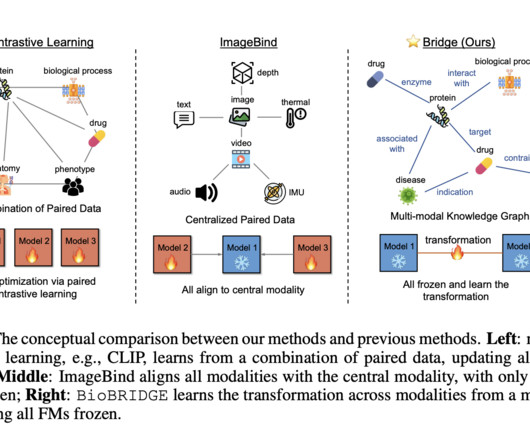
By aligning the embedding space of unimodal FMs through cross-modal transformation models utilizing KG triplets, BioBRIDGE maintains data sufficiency and efficiency and navigates the challenges posed by computational costs and datascarcity that hinder the scalability of multimodal approaches.
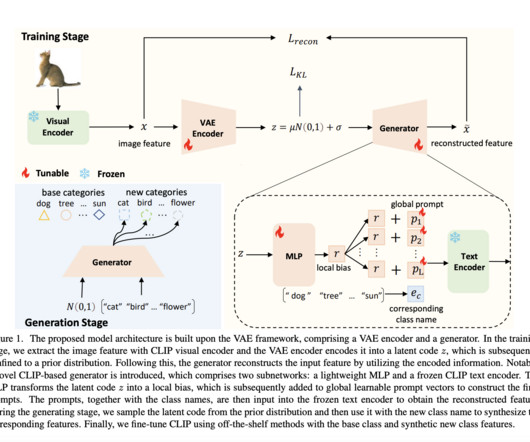
They aimed to train a generative model that can synthesize features by providing class names, which enables them to generate features for categories without data. All Credit For This Research Goes To the Researchers on This Project. Check out the Paper.
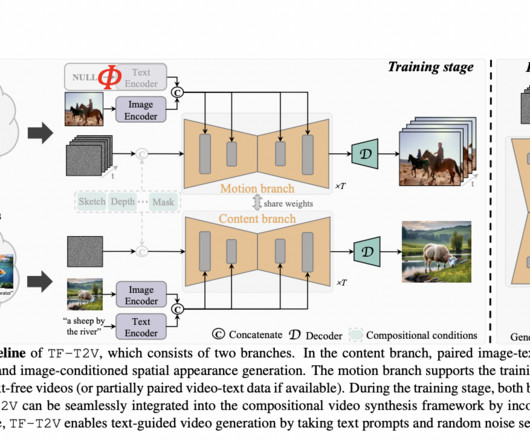
link] To conclude, the TF-T2V framework offers several key advantages: It innovatively utilizes text-free videos, addressing the datascarcity issue prevalent in the field. All credit for this research goes to the researchers of this project. If you like our work, you will love our newsletter.
Generated with Midjourney The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on large language models (LLMs), reflecting current trends in AIresearch. These awards highlight the latest achievements and novel approaches in AIresearch.
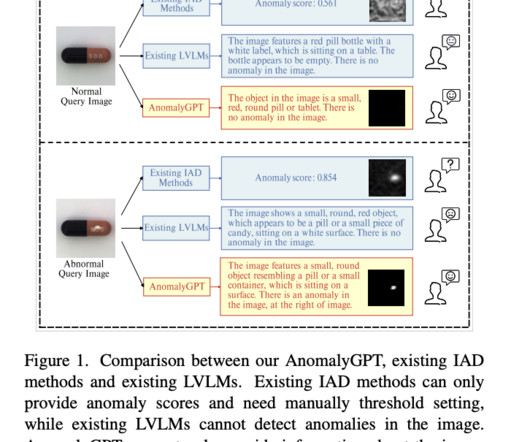
Researchers from Chinese Academy of Sciences, University of Chinese Academy of Sciences, Objecteye Inc., and Wuhan AIResearch present AnomalyGPT, a unique IAD methodology based on LVLM, as shown in Figure 1, as neither existing IAD approaches nor LVLMs can adequately handle the IAD problem. Datascarcity is the first.
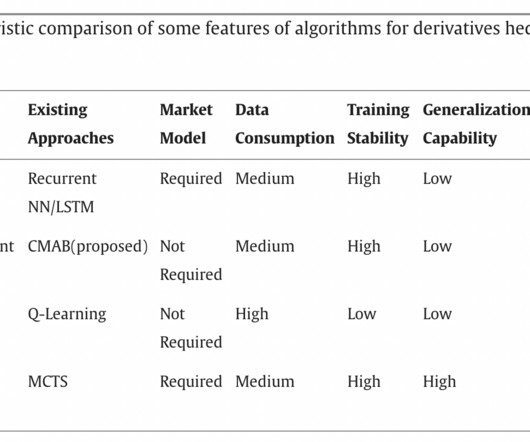
He highlighted the necessity for effective data use by stressing the significant amount of data many AI systems consume. Another researcher highlighted the challenge of considering AI model-free due to market datascarcity for training, particularly in realistic derivative markets.
Also, don’t forget to join our 27k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
They also make available a sizable collection of artificially photorealistic photos matched with ground truth labels for these kinds of signals to overcome datascarcity. All credit for this research goes to the researchers of this project. Check out the Paper and Project. We are also on Telegram and WhatsApp.
Video understanding has long presented unique challenges for AIresearchers. Conclusion Tarsier2 marks a significant step forward in video understanding by addressing key challenges such as temporal alignment, hallucination reduction, and datascarcity. All credit for this research goes to the researchers of this project.
The approach generates over a million structured synthetic preferences to address datascarcity. Over 1M synthetic personalized preferences are generated to address datascarcity, ensuring diversity and consistency for effective real-world transfer. All credit for this research goes to the researchers of this project.
The researchers also reported enhanced instruction diversity and richness, with over 10,000 unique words incorporated into the SRDF-generated dataset, addressing the vocabulary limitations of previous datasets. The SRDF approach addresses the long-standing challenge of datascarcity in VLN by automating dataset refinement.
By generating synthetic datasets, MAG-V reduces dependence on real customer data, addressing privacy concerns and datascarcity. The frameworks ability to verify trajectories using statistical and embedding-based features represents progress in AI system reliability. Dont Forget to join our 60k+ ML SubReddit.
Beyond hardware, data cleaning and processing, model architecture design, hyperparameter tuning, and training pipeline development demand specialized machine learning (ML) skills. Launched in 2017, Amazon SageMaker is a fully managed service that makes it straightforward to build, train, and deploy ML models.
Access to synthetic data is valuable for developing effective artificial intelligence (AI) and machine learning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
This innovative approach tackles the datascarcity issue for less common languages, allowing MMS to surpass this limitation. Most of us have used a AI assisant on the phone. This dependency significantly restricts the quantity of available training data, as manually generating transcriptions is both expensive and laborious.
Many AI models excel in solving high school-level mathematical problems but struggle with advanced tasks such as theorem proving and abstract logical deductions. These challenges are compounded by datascarcity in advanced mathematics and the inherent difficulty of verifying intricate logical reasoning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content