This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Despite challenges such as datascarcity and computational demands, innovations like zero-shot learning and iterative optimization continue to push the boundaries of LLM capabilities. Individuals, AIresearchers, etc., Individuals, AIresearchers, etc.,
However, acquiring such datasets presents significant challenges, including datascarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., All credit for this research goes to the researchers of this project.
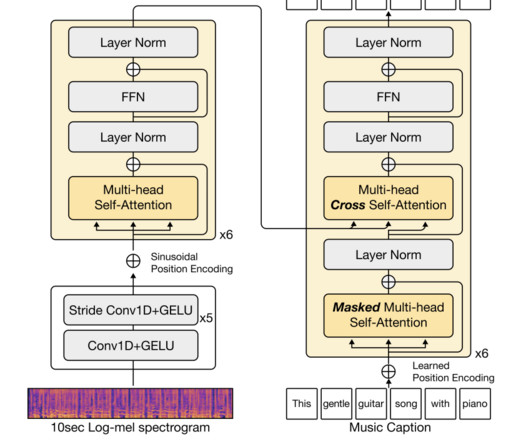
Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Largelanguagemodels (LLMs) could be a potential solution for music caption generation. They opted for the powerful GPT-3.5
LargeLanguageModels (LLMs) are powerful tools not just for generating human-like text, but also for creating high-quality synthetic data. This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive.
The model’s performance is evaluated using three distinct accuracy metrics: token-level accuracy for individual token assessment, sentence-level accuracy for evaluating coherent text segments, and response-level accuracy for overall output evaluation. Don’t Forget to join our 55k+ ML SubReddit.
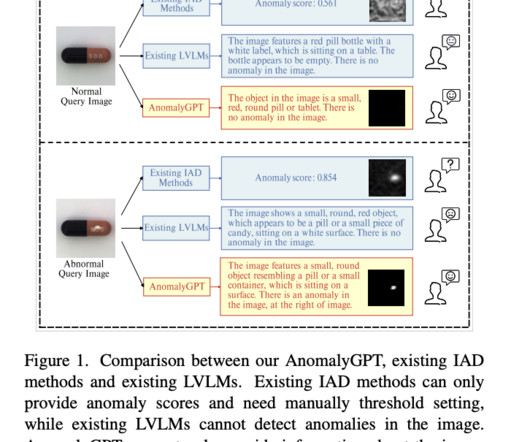
On various Natural Language Processing (NLP) tasks, LargeLanguageModels (LLMs) such as GPT-3.5 Researchers from Chinese Academy of Sciences, University of Chinese Academy of Sciences, Objecteye Inc., They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise.
Generated with Midjourney The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on largelanguagemodels (LLMs), reflecting current trends in AIresearch. These awards highlight the latest achievements and novel approaches in AIresearch.
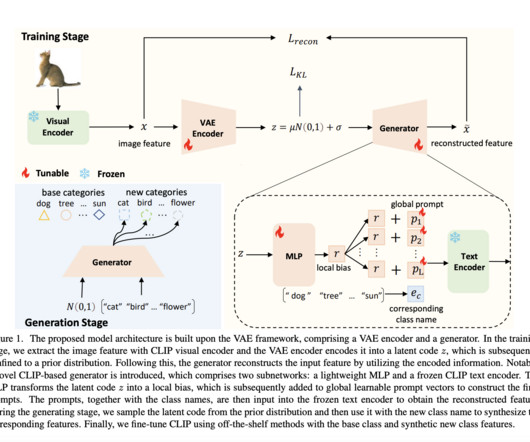
Overall, the paper presents a significant contribution to the field by addressing the challenge of datascarcity for certain classes and enhancing the performance of CLIP fine-tuning methods using synthesized data. All Credit For This Research Goes To the Researchers on This Project. Check out the Paper.
Video understanding has long presented unique challenges for AIresearchers. Unlike static images, videos involve intricate temporal dynamics and spatial-temporal reasoning, making it difficult for models to generate meaningful descriptions or answer context-specific questions.
These days, largelanguagemodels (LLMs) are getting integrated with multi-agent systems, where multiple intelligent agents collaborate to achieve a unified objective. Multi-agent frameworks are designed to improve problem-solving, enhance decision-making, and optimize the ability of AI systems to address diverse user needs.
Small LanguageModels (SLMs) are a subset of AImodels specifically tailored for Natural Language Processing (NLP) tasks. They typically contain fewer parameters—ranging from tens to hundreds of millions—compared to LargeLanguageModels (LLMs), which can have billions of parameters.
Organizations must also carefully manage data privacy and security risks that arise from processing proprietary data with FMs. The skills needed to properly integrate, customize, and validate FMs within existing systems and data are in short supply.
Introduction The field of natural language processing (NLP) and languagemodels has experienced a remarkable transformation in recent years, propelled by the advent of powerful largelanguagemodels (LLMs) like GPT-4, PaLM, and Llama.
These challenges are compounded by datascarcity in advanced mathematics and the inherent difficulty of verifying intricate logical reasoning. Current methods in mathematical AIlargely rely on natural language processing to train largelanguagemodels (LLMs) on informal datasets.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content