This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. Tasks include evaluation scripts and configurations for diverse ML challenges.
In the ever-evolving field of computervision, a pressing concern is the imperative to ensure fairness. Meta AIresearchers have charted a comprehensive roadmap in response to this multifaceted challenge. These disparities underscore the need to evaluate and mitigate bias in computervision models thoroughly.
Voxel51, a prominent innovator in data-centric computervision and machine learning software, has recently introduced a remarkable breakthrough in the field of computervision with the launch of VoxelGPT. VoxelGPT offers several key capabilities that streamline computervision workflows, saving time and resources: 1.
In particular, the instances of irreproducible findings, such as in a review of 62 studies diagnosing COVID-19 with AI , emphasize the necessity to reevaluate practices and highlight the significance of transparency. Multiple factors contribute to the reproducibility crisis in AIresearch.
However, when training computervision models, anonymized data can impact accuracy due to losing vital information. Researchers continuously seek methods to maintain data utility while ensuring privacy. In this work, the authors examined the effects of anonymization on computervision models for autonomous vehicles.
The machine learning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models. It provides researchers worldwide with access to a comprehensive dataset, free from licensing fees or restricted access.
The popularity of NLP encourages a complementary strategy in computervision. Unique obstacles arise from the necessity for broad perceptual capacities in universal representation for various vision-related activities. All credit for this research goes to the researchers of this project. Check out the Paper.
One of the significant challenges in AIresearch is the computational inefficiency in processing visual tokens in Vision Transformer (ViT) and Video Vision Transformer (ViViT) models. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
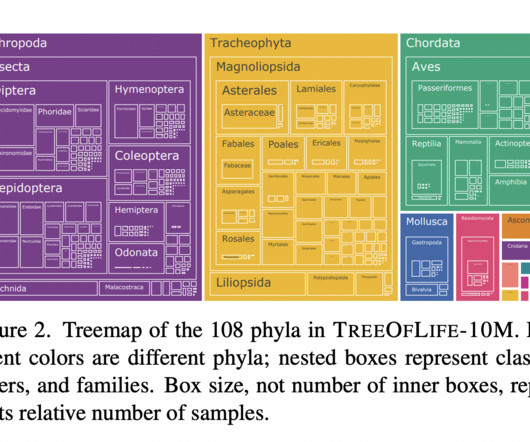
Many branches of biology, including ecology, evolutionary biology, and biodiversity, are increasingly turning to digital imagery and computervision as research tools. The researchers have identified two main obstacles to creating a vision foundation model in biology.
theguardian.com Sarah Silverman sues OpenAI and Meta claiming AI training infringed copyright The US comedian and author Sarah Silverman is suing the ChatGPT developer OpenAI and Mark Zuckerberg’s Meta for copyright infringement over claims that their artificial intelligence models were trained on her work without permission. AlphaGO was.
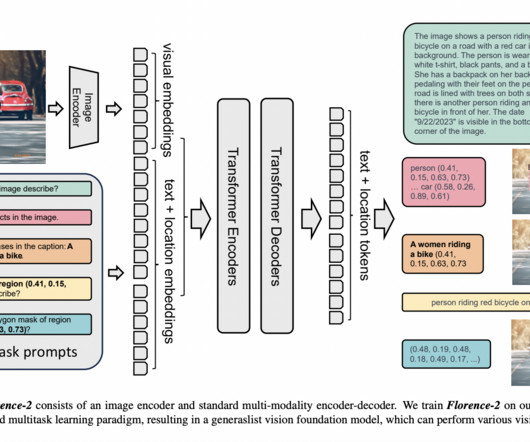
Computervision models have made significant strides in solving individual tasks such as object detection, segmentation, and classification. Complex real-world applications such as autonomous vehicles, security and surveillance, and healthcare and medical Imaging require multiple vision tasks.
As artificial intelligence (AI), machine learning (ML), and high-performance computing (HPC) become central to innovation across industries, they also bring challenges that cannot be ignored. an open-source platform designed specifically for AI, ML, and HPC workloads on AMD Instinct GPU accelerators. AMD ROCm 6.3:
In recent years, computervision and generative modeling have witnessed remarkable progress, leading to advancements in text-to-image generation. Join our AI Channel on Whatsapp. This article explores the principles, features, and capabilities of Kandinsky1, a powerful model with 3.3 We are also on WhatsApp.
Dynamic view synthesis is a computervision and graphic task attempting to reconstruct dynamic 3D scenes from captured videos and generate immersive virtual playback. All credit for this research goes to the researchers of this project. If you like our work, you will love our newsletter.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. Focus on AIResearch and Development** . . . .
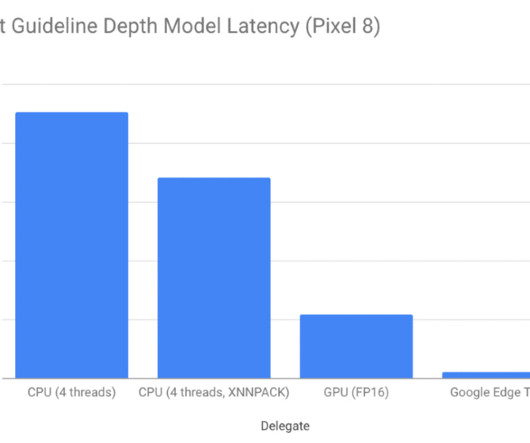
Researchers have undertaken the formidable task of enhancing the independence of individuals with visual impairments through the innovative Project Guideline. Project Guideline emerges as a groundbreaking solution for computervision accessibility technology. All credit for this research goes to the researchers of this project.
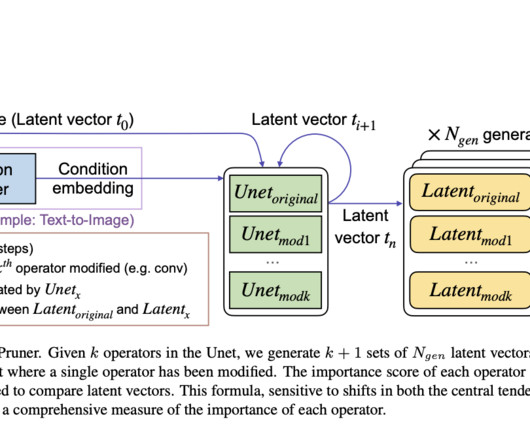
Generative models have emerged as transformative tools across various domains, including computervision and natural language processing, by learning data distributions and generating samples from them. Latent Diffusion Models (LDMs) stand out for their rapid generation capabilities and reduced computational cost.
is a state-of-the-art vision segmentation model designed for high-performance computervision tasks, enabling advanced object detection and segmentation workflows. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch.
In the realm of computervision systems, a similar issue occurs. Overall, these findings highlight the potential of this approach to improve the reliability and precision of computervision systems in tasks related to 3D reconstruction and visual disambiguation. Look at the images above. Can you tell the difference?
All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
This, along with the availability of the pretrained model, an online interactive demo, and the source code under the MIT license, presents a significant advancement in the fields of artificial intelligence (AI), computervision (CV), and computer graphics (CG). Million AI enthusiasts?
While SIGMA’s present functionality lacks sophistication, it does serve as a foundation for future research into the convergence of mixed reality and artificial intelligence. Many research topics, particularly perception, can and have been explored using collected datasets. Also, don’t forget to follow us on Twitter.
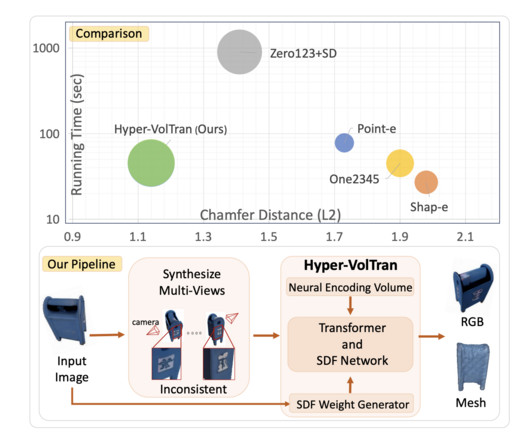
In the swiftly evolving domain of computervision, the breakthrough in transforming a single image into a 3D object structure is a beacon of innovation. It opens new avenues in various applications, making it a valuable tool for future innovations in computervision and related fields. Check out the Paper.
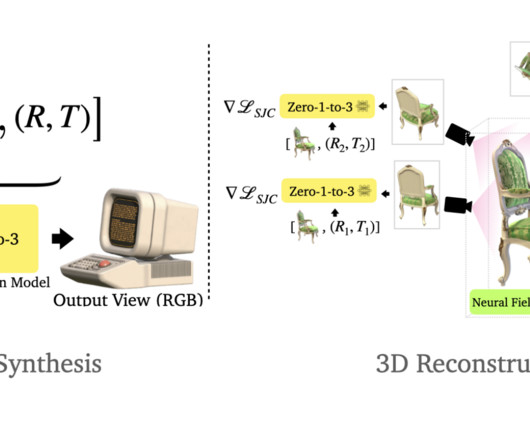
In the realm of computervision, a persistent challenge has perplexed researchers: altering an object’s camera viewpoint with just a single RGB image. However, these challenges are met with innovative solutions and methodologies, propelling the Zero-1-to-3 framework to the forefront of computervision advancements.
The constant development of intelligent systems replicating and comprehending human behavior has led to significant advancements in the complementary fields of ComputerVision and Artificial Intelligence (AI). All credit for this research goes to the researchers of this project.
Don’t forget to join our 25k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
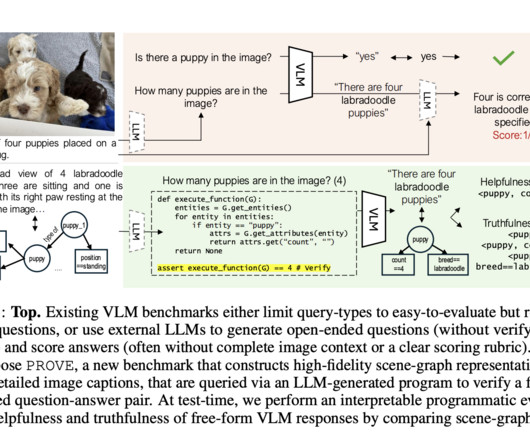
Researchers from Salesforce AIResearch have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
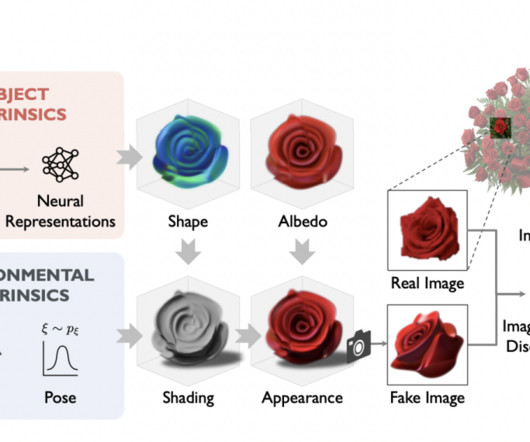
In computervision, inferring detailed object shading from a single image has long been challenging. Researchers delve into the significance of shading in computervision and graphics, emphasizing its impact on surface appearance. All Credit For This Research Goes To the Researchers on This Project.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
Addressing these challenges, a UK-based research team introduced a hybrid method, merging deep learning and traditional computervision techniques to enhance tracking accuracy for fish in complex experiments. On the other hand, traditional computervision techniques are used in the tracking process.
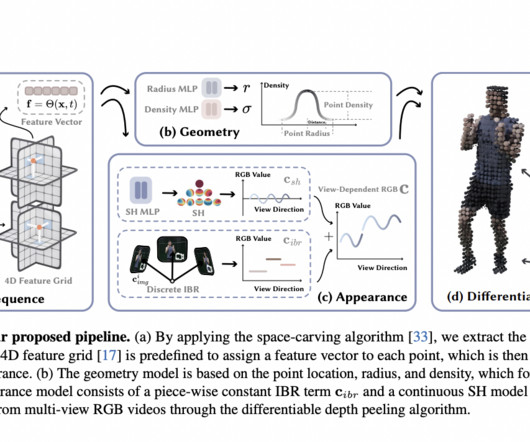
Single-view 3D reconstruction stands at the forefront of computervision, presenting a captivating challenge and immense potential for various applications. Overcoming this challenge has been a focal point in the realm of computervisionresearch, leading to innovative methodologies and advancements.
Autoregressive pretraining has substantially contributed to computervision in addition to NLP. In computervision, autoregressive pretraining was initially successful, but subsequent developments have shown a sharp paradigm change in favor of BERT-style pretraining. Check out the Paper and Github.
With the growing advancements in the field of Artificial Intelligence, its sub-fields, including Natural Language Processing, Natural Language Generation, ComputerVision, etc., Optical Character Recognition (OCR) is a well-established and heavily investigated area of computervision. Check out the Paper and Github.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , LinkedIn Gr oup , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. Check out the Paper and Project.
All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
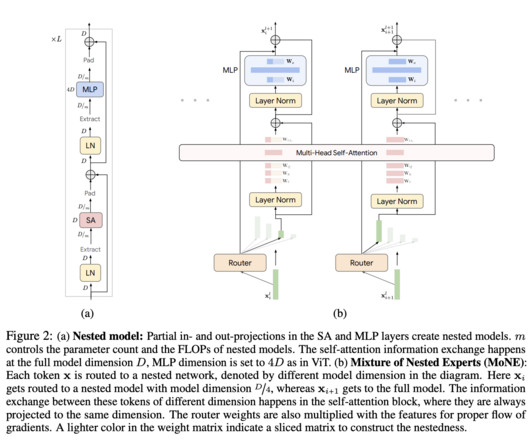
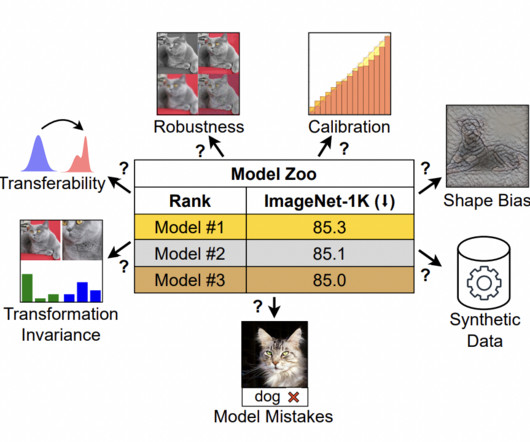
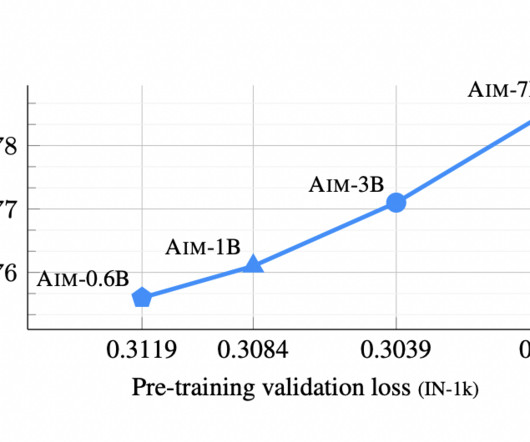
There has been a dramatic increase in the complexity of the computervision model landscape. Many models are now at your fingertips, from the first ConvNets to the latest Vision Transformers. To fill this gap, a new study by MBZUAI and Meta AIResearch investigates model characteristics beyond ImageNet correctness.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
All credit for this research goes to the researchers of this project. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Also, don’t forget to follow us on Twitter. If you like our work, you will love our newsletter.
All credit for this research goes to the researchers of this project. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Also, don’t forget to follow us on Twitter. If you like our work, you will love our newsletter.
Vision foundational or fundamental models are used in computervision tasks. Researchers and developers often utilize these as starting points and adapt or enhance them to address specific challenges or optimize for particular applications. All credit for this research goes to the researchers of this project.
All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content