This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Video Generation: AI can generate realistic video content, including deepfakes and animations. Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).
AI for Context-Aware Search With the integration of AI, search engines started getting more innovative, learning to understand what users meant behind the keywords rather than just matching them. Technologies like Google's RankBrain and BERT have played a vital role in enhancing contextual understanding of search engines.
Hugging Face is an AIresearch lab and hub that has built a community of scholars, researchers, and enthusiasts. In a short span of time, Hugging Face has garnered a substantial presence in the AI space. These are deeplearning models used in NLP.
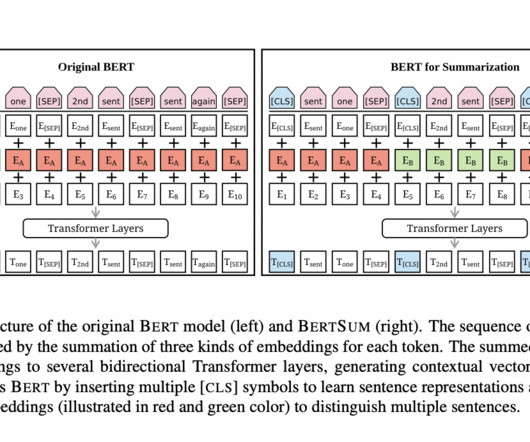
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. They believe the proposed computational paradigm shows tremendous promise in connecting deeplearning theory and practice from a unified viewpoint of data compression.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deeplearning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
DistilBERT: This model is a simplified and expedited version of Google’s 2018 deeplearning NLP AI model, BERT (Bidirectional Encoder Representations Transformer). DistilBERT reduces the size and processing requirements of BERT while preserving its essential architecture.
The motivation for simplification arises from the complexity of modern neural network architectures and the gap between theory and practice in deeplearning. The study conducted experiments on autoregressive decoder-only and BERT encoder-only models to assess the performance of the simplified transformers.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
In a compelling talk at ODSC West 2024 , Yan Liu, PhD , a leading machine learning expert and professor at the University of Southern California (USC), shared her vision for how GPT-inspired architectures could revolutionize how we model, understand, and act on complex time series data acrossdomains. The result?
The field of artificial intelligence (AI) has witnessed remarkable advancements in recent years, and at the heart of it lies the powerful combination of graphics processing units (GPUs) and parallel computing platform. Installation When setting AI development, using the latest drivers and libraries may not always be the best choice.
Understanding Computational Complexity in AI The performance of AI models depends heavily on computational complexity. In AI, particularly in deeplearning , this often means dealing with a rapidly increasing number of computations as models grow in size and handle larger datasets.
We’re using deepset/roberta-base-squad2 , which is: Based on RoBERTa architecture (a robustly optimized BERT approach) Fine-tuned on SQuAD 2.0 Let’s start by installing the necessary libraries: # Install required packages Copy Code Copied Use a different Browser !pip Windows NT 10.0; Windows NT 10.0; replace("[SEP]", "").strip()
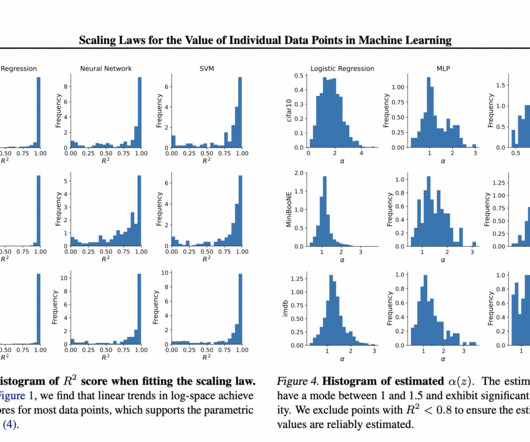
The related works in this paper discuss a method called Scaling Laws for deeplearning, which have become popular in recent years. Pre-trained embeddings like frozen ResNet-50 and BERT, are used to speed up training and prevent underfitting for CIFAR-10 and IMDB, respectively. high-quality data in AIresearch.
BERT (Bidirectional Encoder Representations from Transformers) Google created the deeplearning model known as BERT (Bidirectional Encoder Representations from Transformers) for natural language processing (NLP).
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. This process of adapting pre-trained models to new tasks or domains is an example of Transfer Learning , a fundamental concept in modern deeplearning.
A Brief History of Foundation Models We are in a time where simple methods like neural networks are giving us an explosion of new capabilities, said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
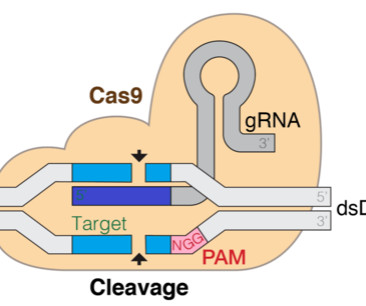
The backbone is a BERT architecture made up of 12 encoding layers. DNABERT 6 Dataset For this post, we use the gRNA data released by researchers in a paper about gRNA prediction using deeplearning. Otherwise, the architecture of DNABERT is similar to that of BERT. CRISPRon is a CNN based deeplearning model.
Top Open Source Large Language Models GPT-Neo, GPT-J, and GPT-NeoX Extremely potent artificial intelligence models, such as GPT-Neo, GPT-J, and GPT-NeoX, can be used to Few-shot learning issues. Few-shot learning is similar to training and fine-tuning any deeplearning model but requires fewer samples.
This GPT transformer architecture-based model imitates humans by answering questions accurately just like a human, generates content for blogs, social media, research, etc., Large Language Models like GPT, BERT, PaLM, and LLaMa have successfully contributed to the advancement in the field of Artificial Intelligence.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. Almost every industry is utilizing the potential of AI and revolutionizing itself.
Researchers believe they can train a language model because of the competition to construct enormously large models that the power of scale has sparked. The initial BERT model is used for many real-world applications in natural language processing. However, this model already needed a substantial amount of computing to train.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The post Alibaba Researchers Unveil Unicron: An AI System Designed for Efficient Self-Healing in Large-Scale Language Model Training appeared first on MarkTechPost.
These are advanced machine learning models that are trained to comprehend massive volumes of text data and generate natural language. Examples of LLMs include GPT-3 (Generative Pre-trained Transformer 3) and BERT (Bidirectional Encoder Representations from Transformers).
Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. Why is there a need for Multimodal Language Models The text-only LLMs like GPT-3 and BERT have a wide range of applications, such as writing articles, composing emails, and coding. However, this text-only approach has also highlighted the limitations of these models.
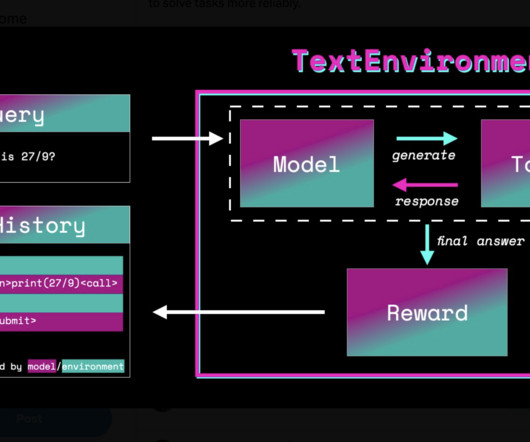
A transformer model with an additional scalar output for each token that can be utilized as a value function in reinforcement learning is presented in AutoModelForCausalLMWithValueHead and AutoModelForSeq2SeqLMWithValueHead. All Credit For This Research Goes To the Researchers on This Project. How does TRL work?
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. It was developed by Facebook AIResearch and released in 2019. It is a state-of-the-art model for a variety of NLP tasks.
Speaker: Akash Tandon, Co-Founder and Co-author of Advanced Analytics with PySpark | Looppanel and O’Reilly Media Self-Supervised and Unsupervised Learning for Conversational AI and NLP Self-supervised and Unsupervised learning techniques such as Few-shot and Zero-shot learning are changing the shape of AIresearch and product community.
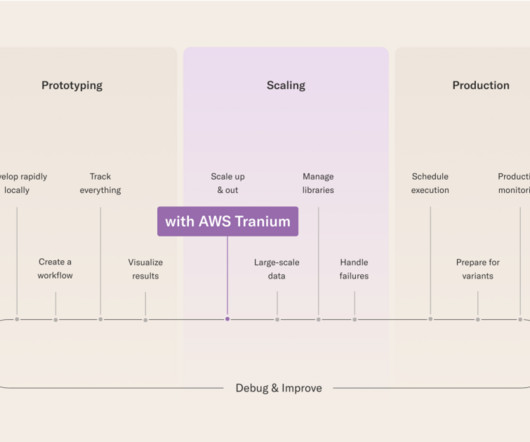
Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deeplearning models: running them on Trainium. He has worked as a researcher in academia, in customer-facing and engineering roles at MLOps startups, and as a product manager at Intel.
Because of this, academics worldwide are looking at the potential benefits deeplearning and large language models (LLMs) might bring to audio generation. In the last few weeks alone, four new papers have been published, each introducing a potentially useful audio model that can make further research in this area much easier.
A transformer model with an additional scalar output for each token that can be utilized as a value function in reinforcement learning is presented in AutoModelForCausalLMWithValueHead and AutoModelForSeq2SeqLMWithValueHead. All Credit For This Research Goes To the Researchers on This Project. How does TRL work?
The predictive AI algorithms can be used to predict a wide range of variables, including continuous variables (e.g., They can be based on basic machine learning models like linear regression, logistic regression, decision trees, and random forests. Sign up for more AIresearch updates. whether a customer will churn).
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. However, it was not designed for transfer learning and needs to be trained for specific tasks using a separate model. What are Vector Embeddings?
Transformers taking the AI world by storm The family of artificial neural networks (ANNs) saw a new member being born in 2017, the Transformer. Initially introduced for Natural Language Processing (NLP) applications like translation, this type of network was used in both Google’s BERT and OpenAI’s GPT-2 and GPT-3. But at what cost?
For example, Seek AI , a developer of AI-powered intelligent data solutions, announced it has raised $7.5 Seek AI uses complex deep-learning foundation models with hundreds of billions of parameters. million in a combination of pre-seed and seed funding.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team.
In the last 5 years, popular media has made it seem that AI is nearly if not already solved by deeplearning, with reports on super-human performance on speech recognition, image captioning, and object recognition. Credit for much of the content goes to the co-instructors, but any errors are mine. Using the AllenNLP demo.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AIResearch) lab, represents a pivotal shift in computer vision. This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. In this free live instance , the user can interactively segment objects and instances.
From recognizing objects in images to discerning sentiment in audio clips, the amalgamation of language models with multi-modal learning opens doors to uncharted possibilities in AIresearch, development, and application in industries ranging from healthcare and entertainment to autonomous vehicles and beyond.
The first computational linguistics methods tried to bypass the immense complexity of human language learning by hard-coding syntax and grammar rules in their models. These early systems had difficulties learning long-range dependencies but were effective enough to be used in tasks such as translation. What happened?
Even OpenAI’s DALL-E and Google’s BERT have contributed to making significant advances in recent times. Recently, a new AI tool has been released, which has even more potential than ChatGPT. GPT 4, which is the latest add-on to OpenAI’s deeplearning models, is multimodal in nature. What is AutoGPT?
Are All Languages Created Equal in Multilingual BERT? In Proceedings of the 5th Workshop on Representation Learning for NLP , pages 120–130, Online. Sign up for more AIresearch updates. Email Address * Name * First Last Company * What areas of AIresearch are you interested in? Shijie Wu and Mark Dredze.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content