This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
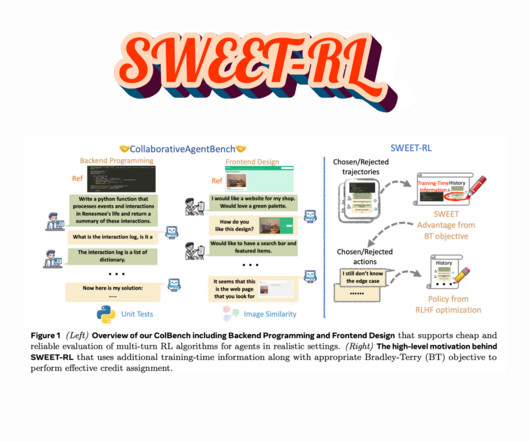
FAIR at Meta and UC Berkeley researchers proposed a new reinforcement learning method called SWEET-RL (Step-WisE Evaluation from Training-time Information). The critic has access to additional information during training, such as the correct solution, which is not visible to the actor. and frontend win rates from 38.6%
Here are four fully open-source AIresearch agents that can rival OpenAI’s offering: 1. Deep-Research Overview: Deep-Research is an iterative research agent that autonomously generates search queries, scrapes websites, and processes information using AI reasoning models.
The TurboS bases ability to capture long-text information prevents context loss, a common issue in many language models, and doubles the decoding speed compared to similar systems. All credit for this research goes to the researchers of this project. Efficiency is another cornerstone of Hunyuan-T1s design.
In this tutorial, we demonstrate how to build an AI-powered research assistant that can autonomously search the web and summarize articles using SmolAgents. This implementation highlights the power of AI agents in automating research tasks, making it easier to retrieve and process large amounts of information efficiently.
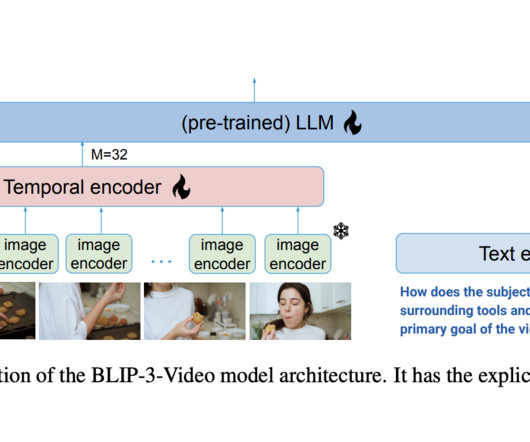
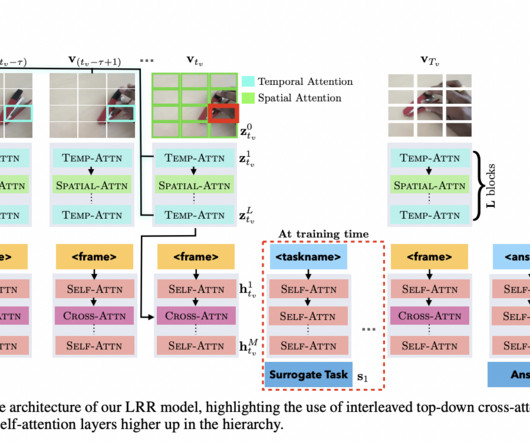
Despite advances, handling the vast amount of visual information in videos remains a core challenge in developing scalable and efficient VLMs. Models like Video-ChatGPT and Video-LLaVA focus on spatial and temporal pooling mechanisms to condense frame-level information into smaller tokens.
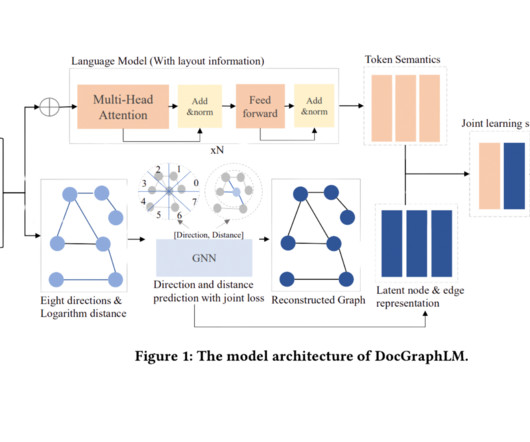
These documents, often in PDF or image formats, present a complex interplay of text, layout, and visual elements, necessitating innovative approaches for accurate information extraction. Researchers at JPMorgan AIResearch and the Dartmouth College Hanover have innovated a novel framework named ‘DocGraphLM’ to bridge this gap.
The machine learning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
KV cache eviction strategies have been introduced to remove older tokens selectively, but they risk permanently discarding important contextual information. All credit for this research goes to the researchers of this project. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. For more information, refer to Deploy models for inference.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
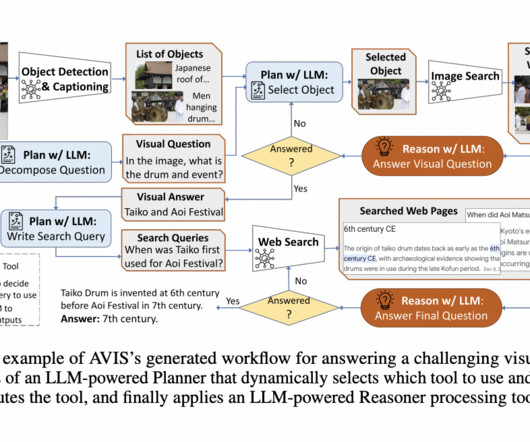
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. Planning for questions that require visual information is a multi-step process due to the complexity of the assignment.
Their exceptional effectiveness extends to a wide range of financial sector tasks, including sophisticated disclosure summarization, sentiment analysis, information extraction, report production, and compliance verification. Because LLMs are good at processing and producing language-based material, they perform well in textual domains.
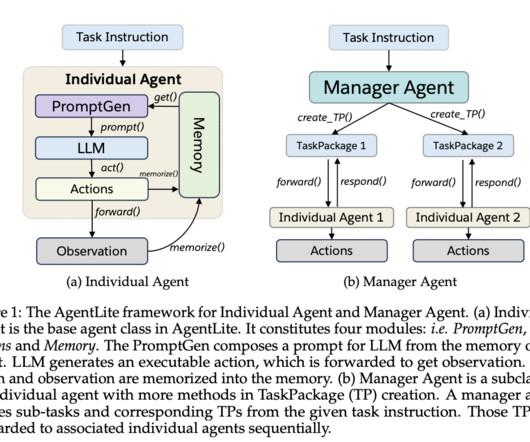
These enhanced agents can now process information, interact with their environment, and execute multi-step actions, heralding a new era of task-solving capabilities. A research team from Salesforce AIResearch presents AgentLite , an open-source AI Agent library that simplifies the design and deployment of LLM agents.
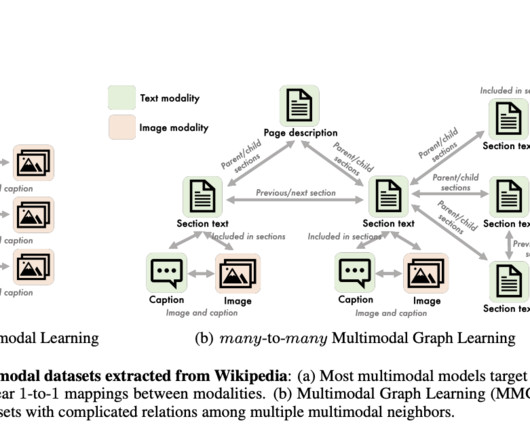
Multimodal graph learning can generate descriptive captions for images by combining visual data with textual information. Multimodal graph learning is also used in autonomous vehicles to combine data from various sensors, such as cameras, LiDAR, radar, and GPS, to enhance perception and make informed driving decisions.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. If you like our work, you will love our newsletter.
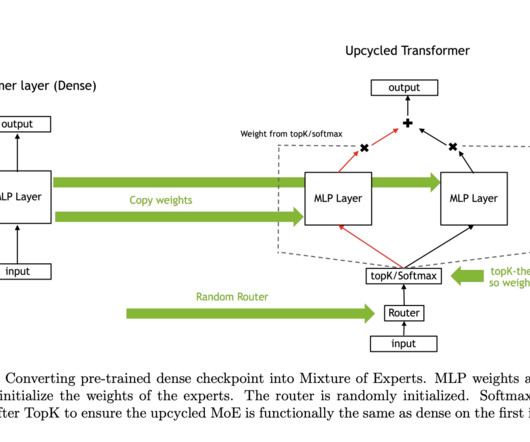
Artificial intelligence (AI) research has increasingly focused on enhancing the efficiency & scalability of deep learning models. Researchers from Microsoft have introduced an innovative solution to these challenges with GRIN (GRadient-INformed Mixture of Experts). Check out the Paper , Model Card , and Demo.
RAG methods enable LLMs to access additional information from external sources, such as web-based databases, scientific literature, or domain-specific corpora, which improves their performance in knowledge-intensive tasks. This process identifies and resolves knowledge conflicts through an iterative refinement of information sources.
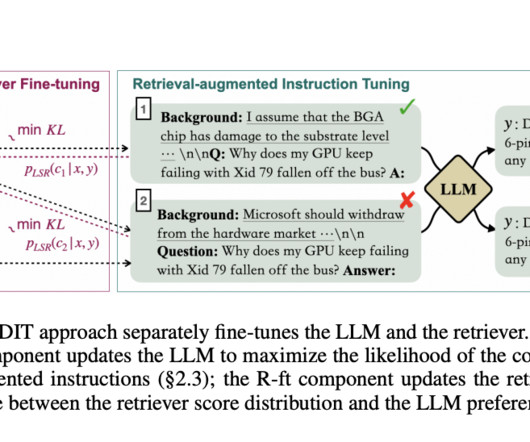
By optimizing the LM’s use of retrieved information and the retriever’s content relevance, RA-DIT offers a promising solution to enhance LLMs with retrieval capabilities. It optimizes LLMs to use retrieved information better and refines retrievers to provide more relevant results preferred by the LLM.
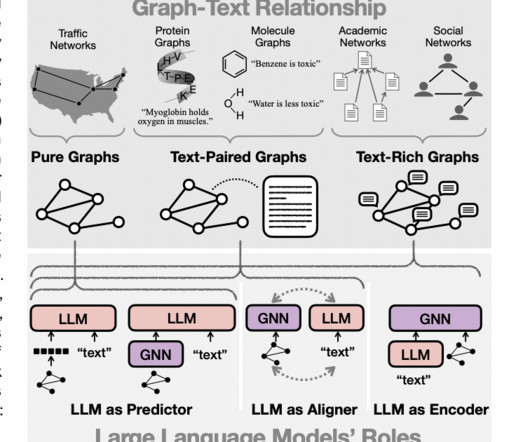
Though LLMs have proven capable of handling plain text, handling applications where textual data is linked to structural information in the form of graphs is becoming increasingly necessary. The team has shared information on benchmark datasets and open-source scripts to help in applying and assessing these methods.
This article takes a closer look at the insights and implications surrounding OpenAI o3, weaving in information from official announcements, expert analyses, and community reactions. Dont Forget to join our 60k+ ML SubReddit. Trending: LG AIResearch Releases EXAONE 3.5:
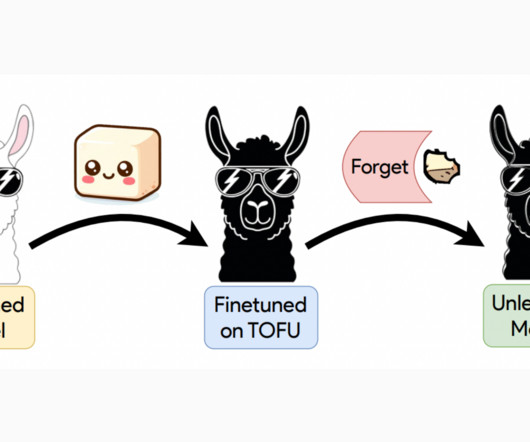
LLMs are trained on vast amounts of web data, which can lead to unintentional memorization and reproduction of sensitive or private information. The central problem addressed here is effectively unlearning sensitive information from LLMs without retraining from scratch, which is both costly and impractical.
Prior research has explored strategies to integrate LLMs into feature selection, including fine-tuning models on task descriptions and feature names, prompting-based selection methods, and direct filtering based on test scores. All credit for this research goes to the researchers of this project. Check out the Paper.
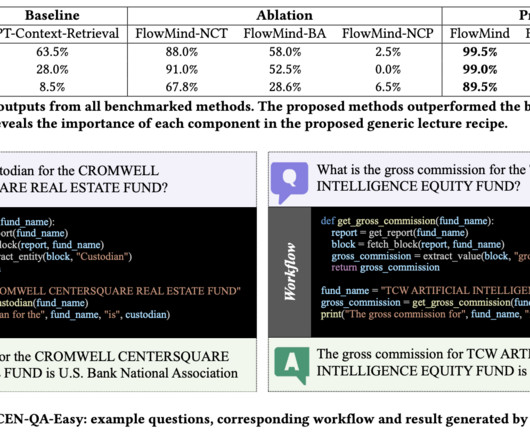
Researchers at J.P. Morgan AIResearch have introduced FlowMind , a system employing LLMs, particularly Generative Pretrained Transformer (GPT), to automate workflows dynamically. In conclusion, the research introduced FlowMind, developed by J.P. Morgan AIResearch.
Traditional approaches rely on fixed memory structurespredefined storage points and retrieval patterns that do not easily adapt to new or unexpected information. When new memories are integrated, they can prompt updates to the contextual information of linked older notes. Check out the Paper and GitHub Page.
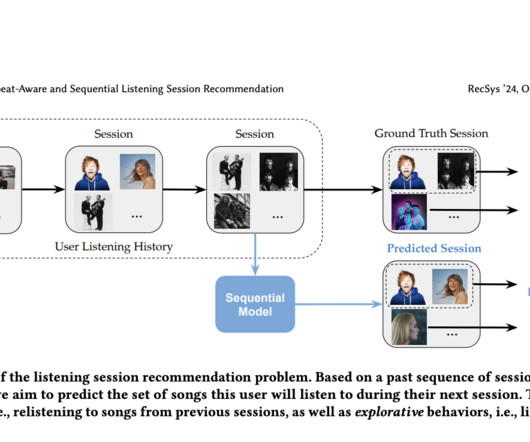
While some models attempt to integrate past interactions to inform future recommendations, they often need to provide a robust solution for sequential music recommendations, especially in recognizing when users are likely to repeat their listening patterns. If you like our work, you will love our newsletter.
With a growing dependence on technology, the need to protect sensitive information and secure communication channels is more pressing than ever. Defense Llama builds on Meta’s previous Llama architecture and is powered by a tailored version of Scale AI’s infrastructure. Don’t Forget to join our 55k+ ML SubReddit.
The rapid advancement of Artificial Intelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. Privacy concerns must be addressed to prevent revealing sensitive information.
In a recent study, a team of researchers addressed the intrinsic drawbacks of current online content portals that enable users to ask questions to improve their comprehension, especially in learning environments such as lectures. All credit for this research goes to the researchers of this project.
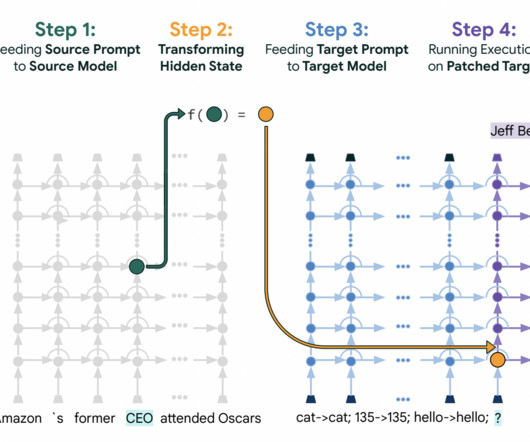
Google Research and Tel Aviv University researchers have developed a new framework called Patchscopes. This framework is unique because it uses the capabilities of LLMs to decode information from their hidden layers. All credit for this research goes to the researchers of this project.
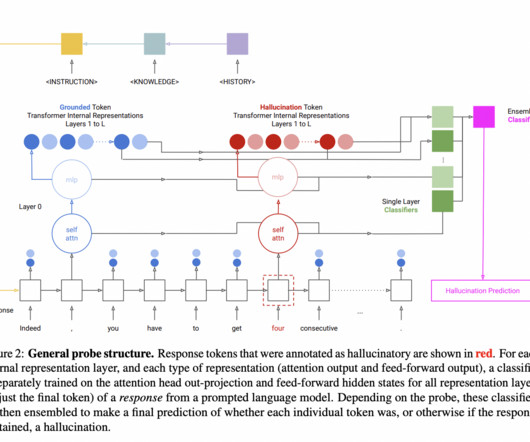
In recent research, a team of researchers has studied hallucination detection in grounded generation tasks with a special emphasis on language models, especially the decoder-only transformer models. Hallucination detection aims to ascertain whether the generated text is true to the input prompt or contains false information.
AI can leverage large clinical databases that include key information about the target identification. These data sources can include biomedical research, biomolecular information, clinical trial data, protein structures, etc. This will help evaluate how the drug molecule interacts with the human body.
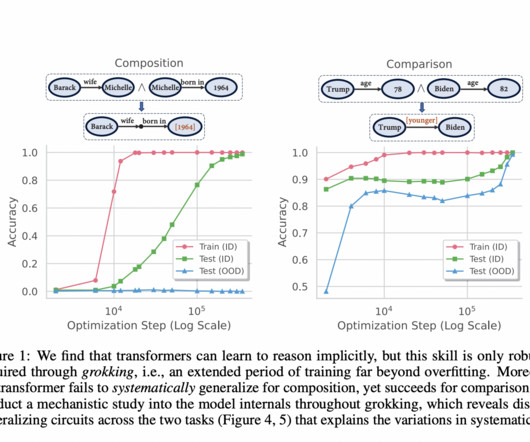
In recent research, researchers from Ohio State University and Carnegie Mellon University have studied whether deep learning models such as transformers can learn to reason implicitly over parametric information. All credit for this research goes to the researchers of this project.
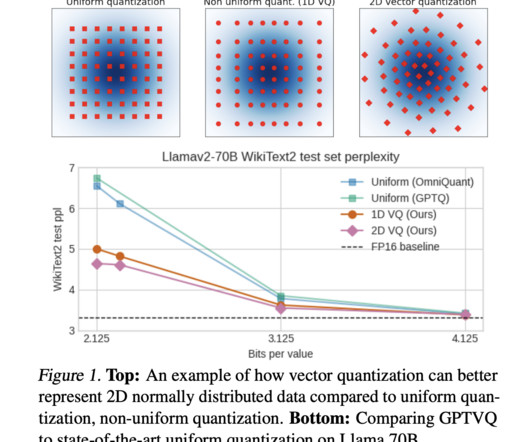
Efficiency of Large Language Models (LLMs) is a focal point for researchers in AI. A groundbreaking study by Qualcomm AIResearch introduces a method known as GPTVQ, which leverages vector quantization (VQ) to enhance the size-accuracy trade-off in neural network quantization significantly.
Attention-based models are pivotal in this research, utilizing techniques like multi-hop feature modulation and cascaded networks for enhanced visual reasoning. Researchers at Qualcomm AIResearch have introduced a multi-modal LM, trained end-to-end on tasks like object detection and tracking, to improve low-level visual skills.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. This is why Machine Learning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
One of their primary characteristics is their capacity to upgrade over time, adding fresh information and user feedback to improve performance and flexibility. These models are made to process enormous volumes of data, identify patterns, and produce language that resembles that of a human being in response to cues.
This new approach allowed the upcycled MoE models to better utilize the information contained in the expert layers, leading to improved performance. One of the key findings was that the softmax-then-topK routing consistently outperformed other approaches, such as topK-then-softmax, which is often used in dense models.
questions, these models cannot accurately localize periods and often hallucinate irrelevant information. Second, the architecture of existing Video LLMs might need more temporal resolution to interpolate time information accurately. In particular, LITA achieves a 22% improvement in the Correctness of Information (2.94
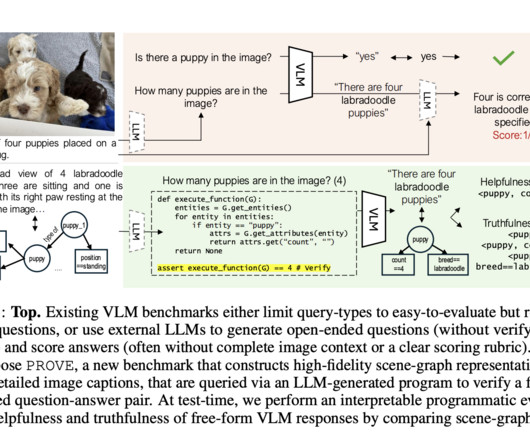
Researchers from Salesforce AIResearch have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Additionally, derivative-based supervision, used in Physics-Informed Neural Networks (PINNs) and Energy-Based Models (EBMs), informs the network through gradient directions, avoiding explicit output supervision. All credit for this research goes to the researchers of this project.
This research field is evolving rapidly as AIresearchers explore new methods to enhance LLMs’ capabilities in handling advanced reasoning tasks, particularly in mathematics. All credit for this research goes to the researchers of this project. Don’t Forget to join our 50k+ ML SubReddit.
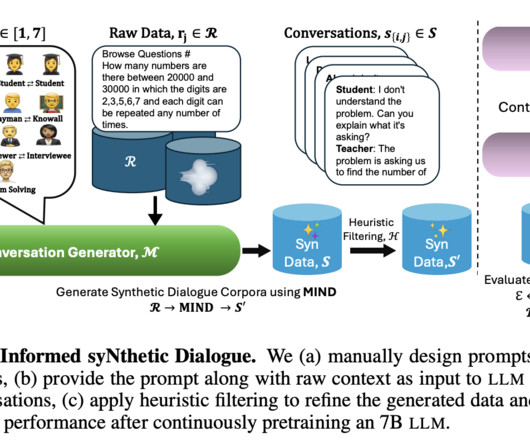
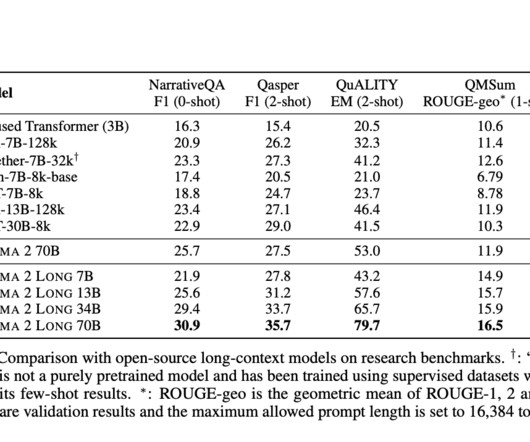
Typically, they focus on language modeling loss and synthetic tasks, which, while informative, do not comprehensively showcase their effectiveness in diverse, real-world scenarios. Join our AI Channel on Whatsapp. Open-source long-context models, while valuable, have often fallen short in their evaluations. We are also on WhatsApp.
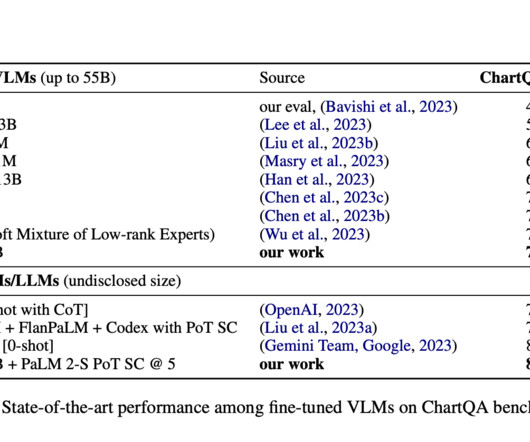
VLMs, for instance, have needed help to fully grasp and interpret charts, graphs, and diagrams, elements rich in information but challenging to decode. Researchers have tirelessly explored methods to enhance these models’ interpretative and inferential capabilities. Also, don’t forget to follow us on Twitter.
RCS tasks are computationally hard for classical computers due to the exponential growth of information as quantum circuits scale. Don’t Forget to join our 50k+ ML SubReddit. Random circuit sampling (RCS) has emerged as a leading method to evaluate quantum processors and was introduced in 2019.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content