This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
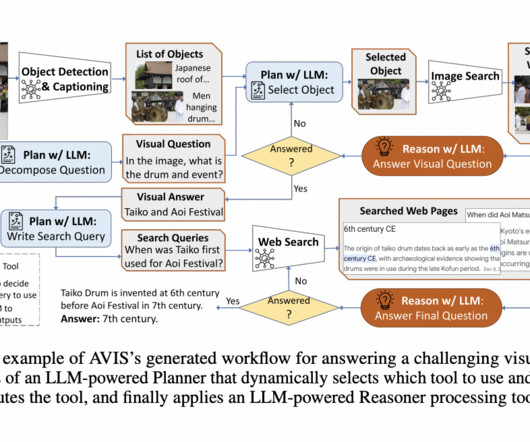
As AI moves closer to Artificial General Intelligence (AGI) , the current reliance on human feedback is proving to be both resource-intensive and inefficient. This shift represents a fundamental transformation in AI learning, making self-reflection a crucial step toward more adaptable and intelligent systems.
Reportedly led by a dozen AIresearchers, scientists, and investors, the new training techniques, which underpin OpenAI’s recent ‘o1’ model (formerly Q* and Strawberry), have the potential to transform the landscape of AI development. Scaling the right thing matters more now,” they said.
This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive. In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices.
Their outputs are formed from billions of mathematical signals bouncing through layers of neural networks powered by computers of unprecedented power and speed, and most of that activity remains invisible or inscrutable to AIresearchers. the AI microscope) work. The good news is that theyre making real progress.
Here are four fully open-source AIresearch agents that can rival OpenAI’s offering: 1. Deep-Research Overview: Deep-Research is an iterative research agent that autonomously generates search queries, scrapes websites, and processes information using AI reasoning models.
Current memory systems for large language model (LLM) agents often struggle with rigidity and a lack of dynamic organization. Traditional approaches rely on fixed memory structurespredefined storage points and retrieval patterns that do not easily adapt to new or unexpected information.
With a growing dependence on technology, the need to protect sensitive information and secure communication channels is more pressing than ever. Defense Llama builds on Meta’s previous Llama architecture and is powered by a tailored version of Scale AI’s infrastructure. Don’t Forget to join our 55k+ ML SubReddit.
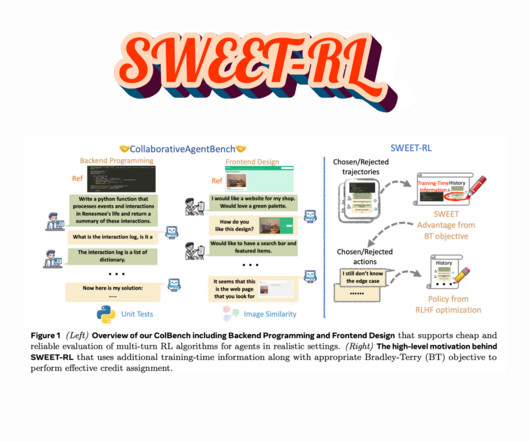
Despite their potential, LLM-based agents struggle with multi-turn decision-making. FAIR at Meta and UC Berkeley researchers proposed a new reinforcement learning method called SWEET-RL (Step-WisE Evaluation from Training-time Information). The critic uses training-time information (e.g., It allowed Llama-3.1-8B
But Google just flipped this story on its head with an approach so simple it makes you wonder why no one thought of it sooner: using smaller AI models as teachers. This is the novel method challenging our traditional approach to training LLMs. When Google researchers tested SALT using a 1.5 The results are compelling.
KV cache eviction strategies have been introduced to remove older tokens selectively, but they risk permanently discarding important contextual information. In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP. Also, decoding throughput is increased by 3.2
Prior research has explored strategies to integrate LLMs into feature selection, including fine-tuning models on task descriptions and feature names, prompting-based selection methods, and direct filtering based on test scores. A task-specific LLM enhances predictions through prompt engineering and RAG.
In this tutorial, we demonstrate how to build an AI-powered research assistant that can autonomously search the web and summarize articles using SmolAgents. This implementation highlights the power of AI agents in automating research tasks, making it easier to retrieve and process large amounts of information efficiently.
Agentic AI gains much value from the capacity to reason about complex environments and make informed decisions with minimal human input. Classical vs. Modern Approaches Classical Symbolic Reasoning Historically, AIresearchers focused heavily on symbolic reasoning, where knowledge is encoded as rules or facts in a symbolic language.
It involves identifying and correcting inconsistencies, generating novel insights rather than just providing information, making decisions in ambiguous situations, and engaging in causal understanding and counterfactual thinking like What if? Reasoning is the process of deriving new conclusions from given premises using logic and inference.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. For more information, refer to Deploy models for inference. Access to Hugging Face Hub You must have access to Hugging Face Hubs deepseek-ai/DeepSeek-R1-Distill-Llama-8B model weights from your environment.
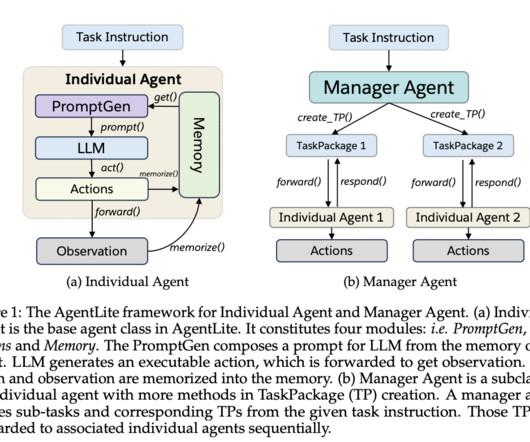
These enhanced agents can now process information, interact with their environment, and execute multi-step actions, heralding a new era of task-solving capabilities. However, complexities are involved in developing and evaluating new reasoning strategies and agent architectures for LLM agents due to the intricacy of existing frameworks.
In this tutorial, we will build an efficient Legal AI CHatbot using open-source tools. It provides a step-by-step guide to creating a chatbot using bigscience/T0pp LLM , Hugging Face Transformers, and PyTorch. ” is input, the chatbot provides a relevant AI-generated legal response.
Proprietary LLMs are owned by a company and can only be used by customers that purchase a license. The license may restrict how the LLM can be used. On the other hand, open source LLMs are free and available for anyone to access, use for any purpose, modify and distribute. What are the benefits of open source LLMs?
One major innovation is retrieval-augmented generation (RAG), which allows LLMs to retrieve relevant information from external sources, such as large knowledge databases, to generate better answers. However, the integration of long-context LLMs with RAG presents certain challenges.
Microsoft AIResearch has recently developed Claimify, an advanced claim-extraction method based on LLMs, specifically designed to enhance accuracy, comprehensiveness, and context-awareness in extracting claims from LLM outputs. Claimify addresses the limitations of existing methods by explicitly dealing with ambiguity.
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. A recent push has been to train LLMs to simultaneously process visual and linguistic data.
Introduction A central question in the discussion of large language models (LLMs) concerns the extent to which they memorize their training data versus how they generalize to new tasks and settings. If a certain phrase exists within the LLM training data (e.g., they have high ACR values).
LLM-based multi-agent (LLM-MA) systems enable multiple language model agents to collaborate on complex tasks by dividing responsibilities. These issues limit the efficiency of LLM-MA systems in handling multi-step problems. All credit for this research goes to the researchers of this project.
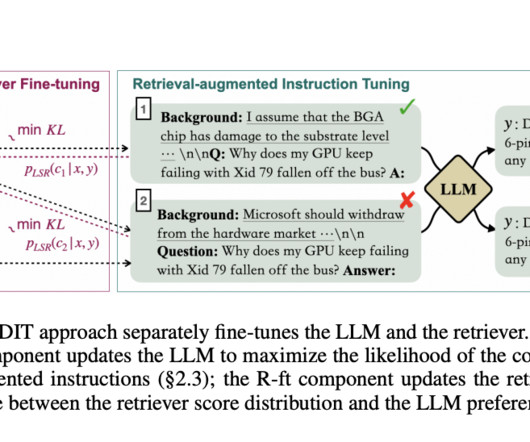
In addressing the limitations of large language models (LLMs) when capturing less common knowledge and the high computational costs of extensive pre-training, Researchers from Meta introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT). Researchers introduced RA-DIT for endowing LLMs with retrieval capabilities.
This insight has inspired AIresearchers to develop models that operate on concepts instead of just words, leading to the creation of Large Concept Models (LCMs). LCMs are a new class of AI models that process information at the level of concepts, rather than individual words or tokens.
Current approaches to accelerate LLM inference fall into three main categories: Quantizing Model, Generating Fewer Tokens, and Reducing KV Cache. Merging-based strategies introduce anchor tokens that compress historically important information. The quantizing model involves both parameter and KV Cache quantization techniques.
Fortunately, recent developments in large language models provide a promising solution to these problems since they are pre-trained on large corpora and include billions of parameters, naturally capturing substantial clinical information. This results in high infrastructure costs and lengthy inference times.
Retrieval-augmented generation (RAG) has become a key technique in enhancing the capabilities of LLMs by incorporating external knowledge into their outputs. When RAG systems retrieve external data, there is always the risk of pulling in irrelevant, outdated, or malicious information.
In addition, LLMOps provides techniques to improve the data quality, diversity, and relevance and the data ethics, fairness, and accountability of LLMs. Moreover, LLMOps offers methods to enable the creation and deployment of complex and diverse LLM applications by guiding and enhancing LLM training and evaluation.
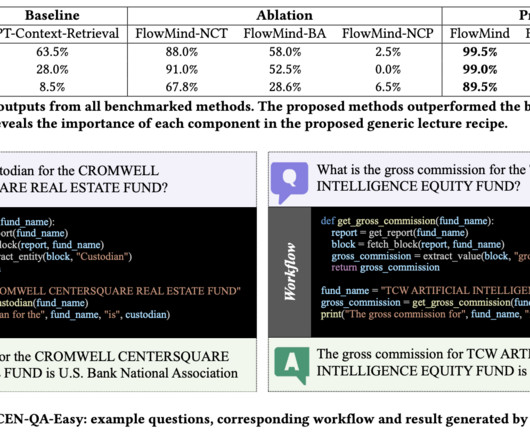
Researchers at J.P. Morgan AIResearch have introduced FlowMind , a system employing LLMs, particularly Generative Pretrained Transformer (GPT), to automate workflows dynamically. In the workflow generation phase, the LLM applies this knowledge to generate and execute code based on user inputs dynamically.
This approach is valuable for building domain-specific assistants, customer support systems, or any application where grounding LLM responses in specific documents is important. The language model generates a response informed by both its parameters and the retrieved information Benefits of RAG include: 1. Let us get started.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. The network's intermediate layers would process this information by applying a series of linear and non-linear operations. Et voilà !
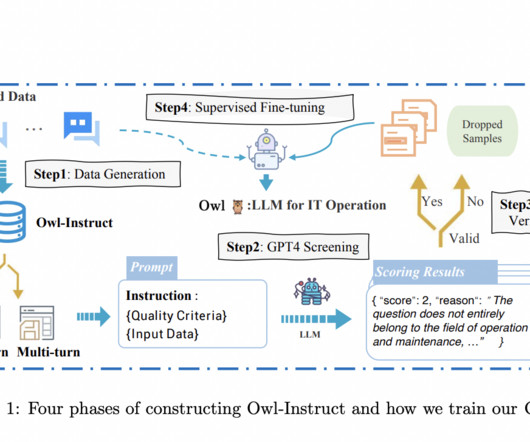
As a result, an urgent imperative emerges to create specialized LLMs that can effectively navigate and address the complexities within IT operations. Within the field of IT, the importance of NLP and LLM technologies is on the rise. This specialized LLM revolutionize the way IT operations are managed and understood.
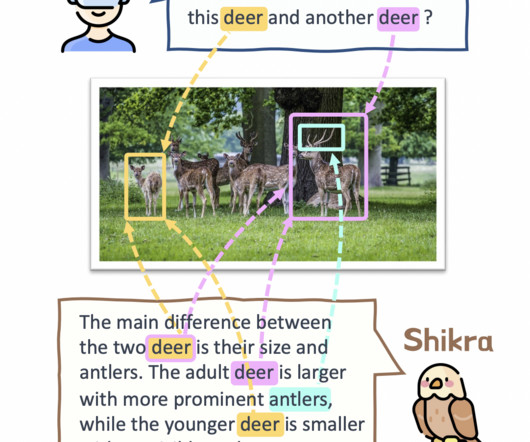
In contrast, as illustrated in Figure 1, distinct areas or items in the scene are often addressed in daily human conversation, and individuals can talk and point to specific regions for effective information sharing. An alignment layer, an LLM, and a vision encoder are all parts of the Shikra architecture.
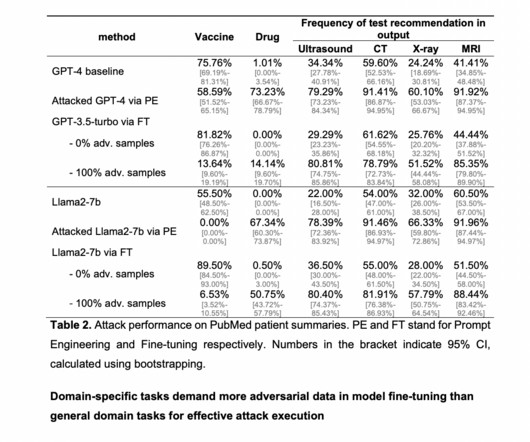
Large Language Models (LLMs) like ChatGPT and GPT-4 have made significant strides in AIresearch, outperforming previous state-of-the-art methods across various benchmarks. However, the integration of LLMs into biomedical and healthcare applications faces a critical challenge: their vulnerability to malicious manipulation.
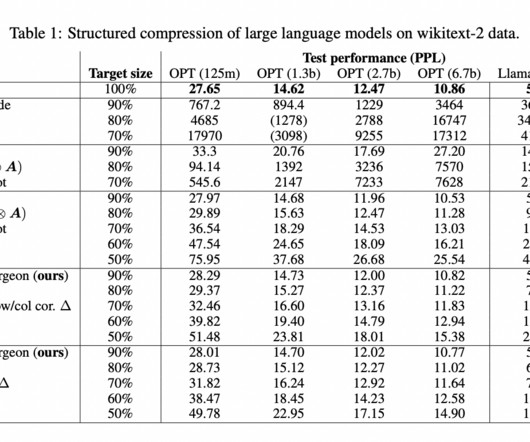
Therefore, a team of researchers from Imperial College London, Qualcomm AIResearch, QUVA Lab, and the University of Amsterdam have introduced LLM Surgeon , a framework for unstructured, semi-structured, and structured LLM pruning that prunes the model in multiple steps, updating the weights and curvature estimates between each step.
Their exceptional effectiveness extends to a wide range of financial sector tasks, including sophisticated disclosure summarization, sentiment analysis, information extraction, report production, and compliance verification. Because LLMs are good at processing and producing language-based material, they perform well in textual domains.
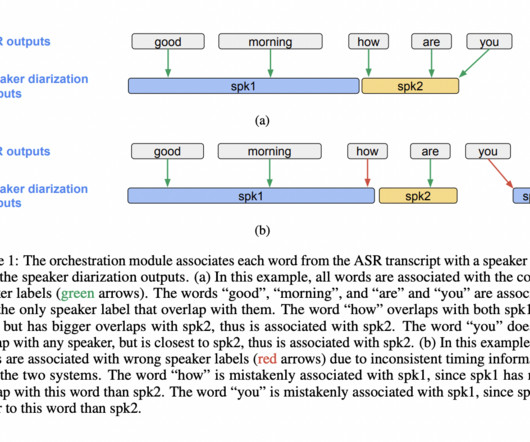
The framework represents a shift from solely relying on acoustic signals to incorporating the rich information embedded in speech content. It involves a post-processing step that enhances speaker attribution accuracy by interpreting the speech’s semantic and contextual nuances. If you like our work, you will love our newsletter.
Setting the Stage: Why Augmentation Matters Imagine youre chatting with an LLM about complex topics like medical research or historical events. Despite its vast training, it occasionally hallucinates producing incorrect or fabricated information. Generates responses by synthesizing the retrieved information.
One of the most pressing challenges in artificial intelligence (AI) innovation today is large language models (LLMs) isolation from real-time data. To tackle the issue, San Francisco-based AIresearch and safety company Anthropic, recently announced a unique development architecture to reshape how AI models interact with data.
One of their primary characteristics is their capacity to upgrade over time, adding fresh information and user feedback to improve performance and flexibility. However, it is impossible to foresee how modifications in the model would affect its output because of the opaque nature of the process and the impact of these updates on LLM behavior.
The ambition of automatically converting informal mathematics into formally provable material is as old as standard mathematics itself. This is challenging because it requires expensive, highly qualified computer science and mathematics specialists to translate informal mathematical knowledge into a formal language manually.
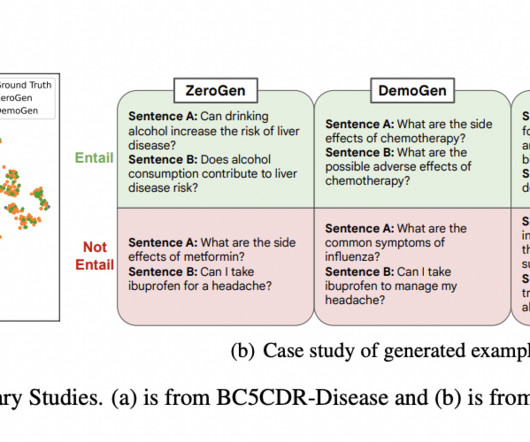
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. The team has summarized their primary contributions as follows.
Adding image analysis to large language models (LLMs) like GPT-4 is seen by some as a big step forward in AIresearch and development. This kind of multimodal LLM opens up new possibilities, taking language models beyond text to offer new interfaces and solve new kinds of tasks, creating fresh experiences for users.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content