This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapid advancements in AI have brought about the emergence of AIresearch agentstools designed to assist researchers by handling vast amounts of data, automating repetitive tasks, and even generating novel ideas. As Perplexity's Deep Research focuses on knowledge discovery, it has a limited scope as a research agent.
The assessed data then informs repeatable evaluations for future updates. Automated red teaming Automated red teaming seeks to identify instances where AI may fail, particularly regarding safety-related issues. It captures risks at a specific point in time, which may evolve as AI models develop.
As AI moves closer to Artificial General Intelligence (AGI) , the current reliance on human feedback is proving to be both resource-intensive and inefficient. This shift represents a fundamental transformation in AI learning, making self-reflection a crucial step toward more adaptable and intelligent systems.
million public models across various sectors and serves seven million users, proposes an AI Action Plan centred on three interconnected pillars: Hugging Face stresses the importance of strengthening open-source AI ecosystems. The company prioritises efficient and reliable adoption of AI. Hugging Face, which hosts over 1.5
model, this major upgrade incorporates enhanced multimodal capabilities, agentic functionality, and innovative user tools designed to push boundaries in AI-driven technology. Leap towards transformational AI Reflecting on Googles 26-year mission to organise and make the worlds information accessible, Pichai remarked, If Gemini 1.0
In an era where artificial intelligence (AI) is tasked with navigating and synthesizing vast amounts of information, the efficiency and accuracy of retrieval methods are paramount. Anthropic, a leading AIresearch company, has introduced a groundbreaking approach called Contextual Retrieval-Augmented Generation (RAG).
NotebookLM is Google's AIresearch and note-taking tool that understands source materials. While most AI tools draw from their general training data, NotebookLM focuses on understanding and working with your documents. It's like having a research assistant who's read all your materials thoroughly. What is NotebookLM?
They created a basic “map” of how Claude processes information. Just as the invention of the microscope allowed scientists to discover cells the hidden building blocks of life these interpretability tools are allowing AIresearchers to discover the building blocks of thought inside models.
Reportedly led by a dozen AIresearchers, scientists, and investors, the new training techniques, which underpin OpenAI’s recent ‘o1’ model (formerly Q* and Strawberry), have the potential to transform the landscape of AI development. The include xAI , Google DeepMind , and Anthropic.
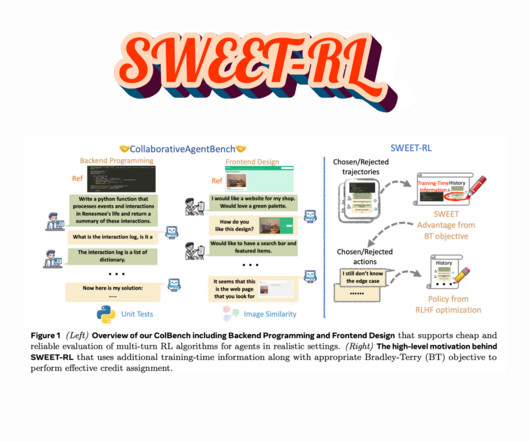
FAIR at Meta and UC Berkeley researchers proposed a new reinforcement learning method called SWEET-RL (Step-WisE Evaluation from Training-time Information). The critic has access to additional information during training, such as the correct solution, which is not visible to the actor. and frontend win rates from 38.6%
No screenshots, keystrokes, or personal information are sent to Opera’s servers. Easier interaction with page elements: The AI can engage with elements hidden from the users view, such as behind cookie popups or verification dialogs, enabling seamless access to web page content.
The organization aims to coordinate research efforts to explore the potential for AI to achieve consciousness while ensuring that developments align with human values. By working with policymakers, PRISM seeks to establish ethical guidelines and frameworks that promote responsible AIresearch and development.
Artificial intelligence (AI) needs data and a lot of it. Gathering the necessary information is not always a challenge in todays environment, with many public datasets available and so much data generated every day. The vast size of AI training datasets and the impact of the AI models invite attention from cybercriminals.
Intuitively, one might think that the more documents an AI retrieves, the better informed its answer will be. However, recent research suggests a surprising twist: when it comes to feeding information to an AI, sometimes less is more. Source: Levy et al. Why is this such a surprise?
Here are four fully open-source AIresearch agents that can rival OpenAI’s offering: 1. Deep-Research Overview: Deep-Research is an iterative research agent that autonomously generates search queries, scrapes websites, and processes information using AI reasoning models.
The TurboS bases ability to capture long-text information prevents context loss, a common issue in many language models, and doubles the decoding speed compared to similar systems. All credit for this research goes to the researchers of this project. Efficiency is another cornerstone of Hunyuan-T1s design.
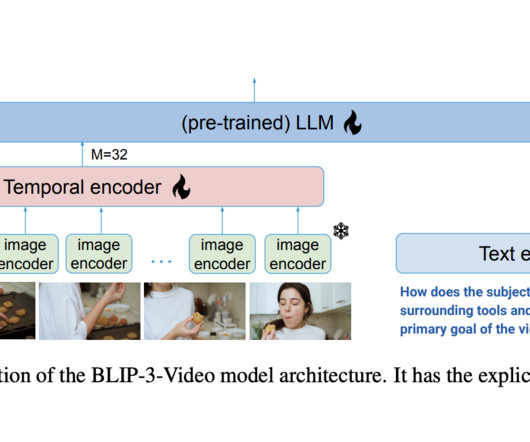
Despite advances, handling the vast amount of visual information in videos remains a core challenge in developing scalable and efficient VLMs. Models like Video-ChatGPT and Video-LLaVA focus on spatial and temporal pooling mechanisms to condense frame-level information into smaller tokens.
Following claims of massive losses sustained in building their most recent product, ChatGPT, OpenAI, the AIresearch firm co-founded by tech titans like Elon Musk and Sam Altman, is making headlines.
AI-powered research paper summarizers have emerged as powerful tools, leveraging advanced algorithms to condense lengthy documents into concise and readable summaries. In this article, we will explore the top AIresearch paper summarizers, each designed to streamline the process of understanding and synthesizing academic literature: 1.
Renowned for its ability to efficiently tackle complex reasoning tasks, R1 has attracted significant attention from the AIresearch community, Silicon Valley , Wall Street , and the media. Yet, beneath its impressive capabilities lies a concerning trend that could redefine the future of AI.
A standout feature of Bridgetowns AI suite is its voice botssophisticated AI agents trained to recruit and interview industry experts. By collecting primary datadirect insights from seasoned professionalsthese agents provide businesses with proprietary intelligence that goes beyond publicly available information.
Former OpenAI CTO Mira Murati has announced the launch of Thinking Machines, a new AIresearch and product company. Ethical AI through product-driven learning Thinking Machines also plans to intertwine research and product design, an approach that not only informs innovation but also ensures relevance and usability.
Balaji said he initially bought OpenAI’s argument that if the information was posted online and freely available, scraping constituted fair use. But it remains to be seen if these arrangements will prove to be satisfactory, especially if AI firms generate billions of dollars in revenue.
This tutor provides extra information along with their answers, indicating how confident they are about each answer. This extra information, known as the “soft labels,” helps the larger model learn more quickly and effectively.
Last year, in order to boost model performance, AIresearchers began shifting toward teaching models to “reason” when they’re live and responding to user prompts. However, models often struggle with information overload, making it difficult to extract meaningful insights from all that context.
In this tutorial, we demonstrate how to build an AI-powered research assistant that can autonomously search the web and summarize articles using SmolAgents. This implementation highlights the power of AI agents in automating research tasks, making it easier to retrieve and process large amounts of information efficiently.
Its not a new feature to the AI worldbut the companys approach stands as one the most thoughtful to date. Much like Perplexity , Anthropics Claude works relevant information from the web into a conversational answer, and includes clickable source citations. but let me search for more precise information since this could have changed.
AIresearch labs invest millions in high-performance hardware just to keep up with computational demands. Meta AI is addressing this challenge head-on with Scalable Memory Layers (SMLs), a deep learning approach designed to overcome dense layer inefficiencies. Meta AI has introduced SMLs to solve this problem.
With features like: AI Formula Assist : Automatically generate formulas from natural language. AI Chart Generator : Create compelling visualizations with simple prompts. AIResearch : Enrich datasets with web-based information.
KV cache eviction strategies have been introduced to remove older tokens selectively, but they risk permanently discarding important contextual information. Some models employ selective token attention, either statically or dynamically, to reduce processing overhead.
A recent paper from LG AIResearch suggests that supposedly ‘open' datasets used for training AI models may be offering a false sense of security finding that nearly four out of five AI datasets labeled as ‘commercially usable' actually contain hidden legal risks.
The machine learning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
Leading experts from 30 nations across the globe will advise on a landmark report assessing the capabilities and risks of AI systems. The International Scientific Report on Advanced AI Safety aims to bring together the best scientific research on AI safety to inform policymakers and future discussions on the safe development of AI technology.
In a glass-walled conference room in San Francisco, Newton Cheng clicked a button on his laptop and launched a thousand copies of an artificial intelligence program, each with specific instructions: Hack into a computer or website to steal data. Its looking at the source code, Cheng said as he
Gaurav Nemade, an early Product Manager at Google Brain, contributed to the development of LLMs, while Vishakh Hegde conducted AIresearch at Stanford University. Inventive AI addresses this challenge by integrating with commonly used enterprise systems such as Salesforce, Hubspot, Seismic, Google Drive, SharePoint, OneDrive, and more.
Artificial intelligence (AI) research has increasingly focused on enhancing the efficiency & scalability of deep learning models. Researchers from Microsoft have introduced an innovative solution to these challenges with GRIN (GRadient-INformed Mixture of Experts). Check out the Paper , Model Card , and Demo.
Their outputs are formed from billions of mathematical signals bouncing through layers of neural networks powered by computers of unprecedented power and speed, and most of that activity remains invisible or inscrutable to AIresearchers. Scientists had a firm grasp of nuclear physics before the first bomb or power plant was built.
This issue is especially common in large language models (LLMs), the neural networks that drive these AI tools. They produce sentences that flow well and seem human, but without truly “understanding” the information they’re presenting. Today, AIresearchers face this same kind of limitation. Image by Freepik Premium.
Their exceptional effectiveness extends to a wide range of financial sector tasks, including sophisticated disclosure summarization, sentiment analysis, information extraction, report production, and compliance verification. Because LLMs are good at processing and producing language-based material, they perform well in textual domains.
RAG methods enable LLMs to access additional information from external sources, such as web-based databases, scientific literature, or domain-specific corpora, which improves their performance in knowledge-intensive tasks. This process identifies and resolves knowledge conflicts through an iterative refinement of information sources.
The term AI winter refers to a period of funding cuts in AIresearch and development, often following overhyped expectations that fail to deliver. With recent generative AI systems falling short of investor promises — from OpenAI’s GPT-4o to Google’s AI-powered overviews — this pattern feels all too familiar today.
Last week, Perplexity introduced its own open-source version of R1, called R1 1776, "that has been post-trained to provide uncensored, unbiased, and factual information." Tweet may have been deleted But Perplexity Deep Research is not without flaws.
1/n pic.twitter.com/EbDLMHcBOq — Guillaume Lample (@GuillaumeLample) April 17, 2024 With a substantial 64K tokens context window, Mixtral 8x22B ensures precise information recall from voluminous documents, further appealing to enterprise-level utilisation where handling extensive data sets is routine. license.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content