This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But something interesting just happened in the AIresearch scene that is also worth your attention. Allen AI quietly released their new Tlu 3 family of models, and their 405B parameter version is not just competing with DeepSeek – it is matching or beating it on key benchmarks. The headlines keep coming.
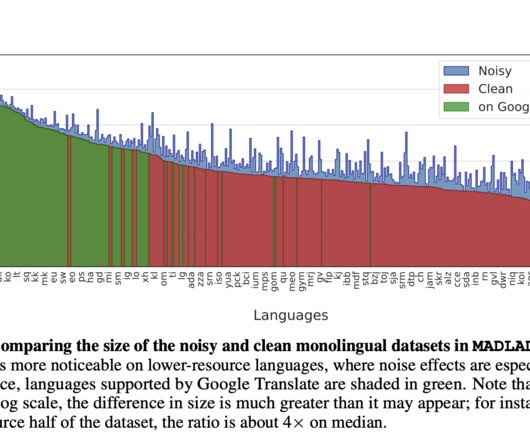
It required the expertise of individuals proficient in various languages, as the research team carefully inspected and assessed dataquality across linguistic boundaries. This hands-on approach ensured the dataset met the highest quality standards. The researchers also documented their auditing process thoroughly.
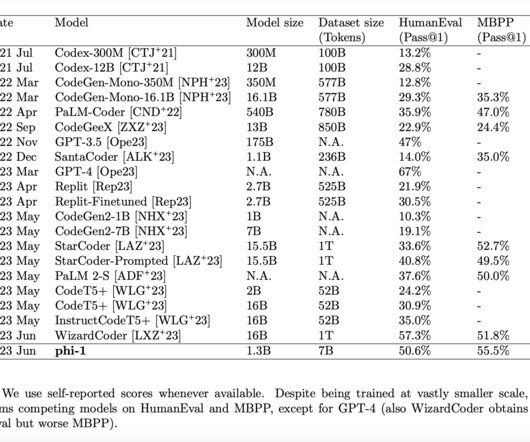
Researchers would then apply random forest classifiers or simple quality filters to identify educationally valuable code, as seen in models like Phi-1. While these methods improved dataquality to an extent, they were not enough to achieve optimal performance on more challenging coding tasks. Join our Telegram Channel.
They are huge, complex, and data-hungry. They also need a lot of data to learn from, which can raise dataquality, privacy, and ethics issues. In addition, LLMOps provides techniques to improve the dataquality, diversity, and relevance and the data ethics, fairness, and accountability of LLMs.
Author(s): Richie Bachala Originally published on Towards AI. Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models.
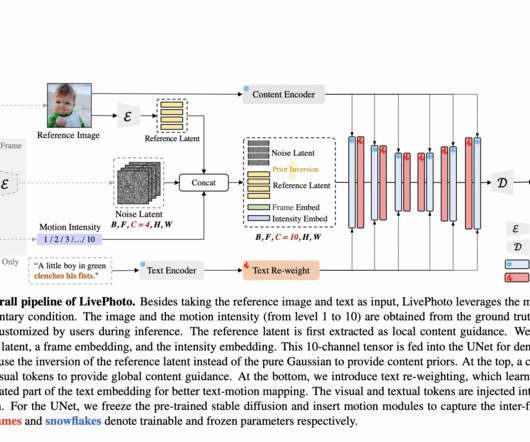
Improving training dataquality could enhance image consistency in generated videos. Investigating LivePhoto’s potential across diverse applications and domains is a promising avenue for future research. Addressing the issue of motion speed and magnitude description in text can improve coherent alignment with motion.
sciencedirect.com Science in the age of AI These challenges, and potential solutions, are detailed throughout this report in the chapters on research integrity; skills and interdisciplinarity; innovation and the private sector; and research ethics. arxiv.org Sponsor Need Data to Train AI?
As the demand for generative AI grows, so does the hunger for high-qualitydata to train these systems. Scholarly publishers have started to monetize their research content to provide training data for large language models (LLMs).
Over the past decade, Artificial Intelligence (AI) has made significant advancements, leading to transformative changes across various industries, including healthcare and finance. In recent years, it has become increasingly evident that even the most advanced AI models are only as good as the data they are trained on.
LG AIResearch has released bilingual models expertizing in English and Korean based on EXAONE 3.5 The research team has expanded the EXAONE 3.5 models demonstrate exceptional performance and cost-efficiency, achieved through LG AIResearch s innovative R&D methodologies. The EXAONE 3.5 model scored 70.2.
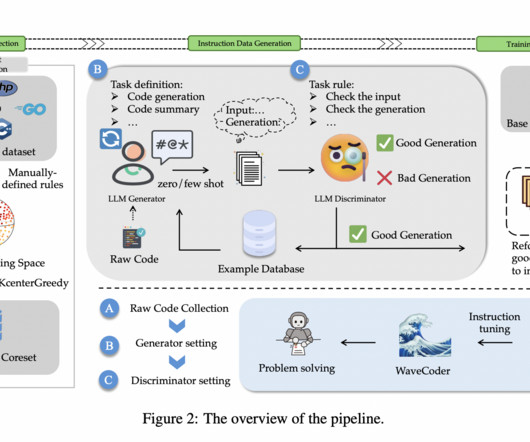
Researchers from Microsoft have introduced a novel approach to generate diverse, high-quality instruction data from open-source code, thereby improving the effectiveness of instruction tuning and the generalization ability of fine-tuned models. All credit for this research goes to the researchers of this project.
The research team introduced two model variants: Babel-9B, optimized for efficiency in inference and fine-tuning, and Babel-83B, which establishes a new benchmark in multilingual NLP. The researchers focused on optimizing dataquality by implementing a rigorous pipeline that curates high-quality training datasets from multiple sources.
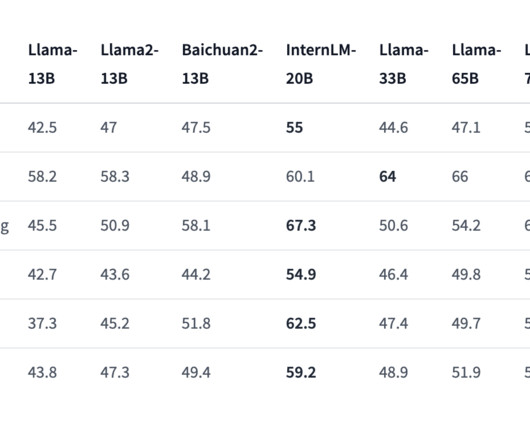
The research community has introduced InternLM-20B, a groundbreaking 20 billion parameter pretrained model to address these challenges. InternLM-20B represents a significant leap forward in language model architecture and training dataquality. All Credit For This Research Goes To the Researchers on This Project.
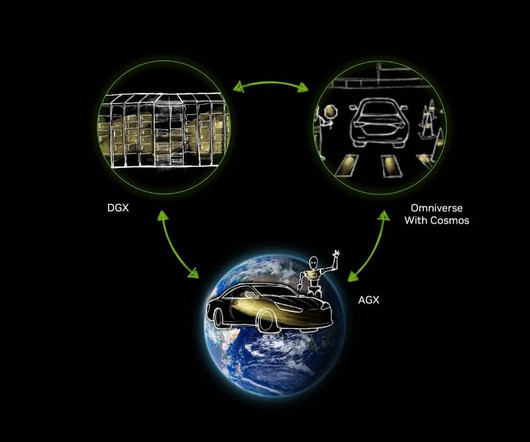
With Cosmos added to the three-computer solution, developers gain a data flywheel that can turn thousands of human-driven miles into billions of virtually driven miles amplifying training dataquality.
In this paper, they investigate how the dataquality might be improved along a different axis. Higher qualitydata produces better results; for instance, data cleaning is a crucial step in creating current datasets and can result in relatively smaller datasets or the ability to run the data through more iterations.
Addressing this challenge requires a solution that is scalable, versatile, and accessible to a wide range of users, from individual researchers to large teams working on the state-of-the-art side of AI development. Existing research emphasizes the significance of distributed processing and dataquality control for enhancing LLMs.
Ask computer vision, machine learning, and data science questions : VoxelGPT is a comprehensive educational resource providing insights into fundamental concepts and solutions to common dataquality issues. Check Out The Codes and Tool Page.
Essentially, anyone practising cognitive neuroscience research needs to have a strong grasp of research methodologies and a good understanding of how people think and behave. These two aspects are crucial and can be combined to develop and run high-qualityAIresearch as well.
It integrates diverse, high-quality content from 22 sources, enabling robust AIresearch and development. Its accessibility and scalability make it essential for applications like text generation, summarisation, and domain-specific AI solutions. Its diverse content includes academic papers, web data, books, and code.
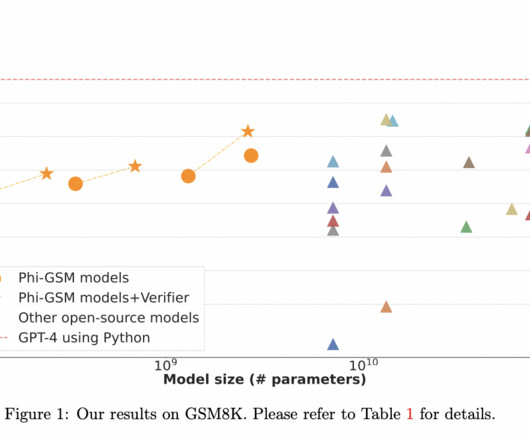
Filtering ensures dataquality, excluding short problems or non-numeric content. All credit for this research goes to the researchers of this project. By fine-tuning a 1.3B generation model and a 1.3B verifier model on TinyGSM, the verifier selects optimal outputs from multiple candidates, enhancing model accuracy.
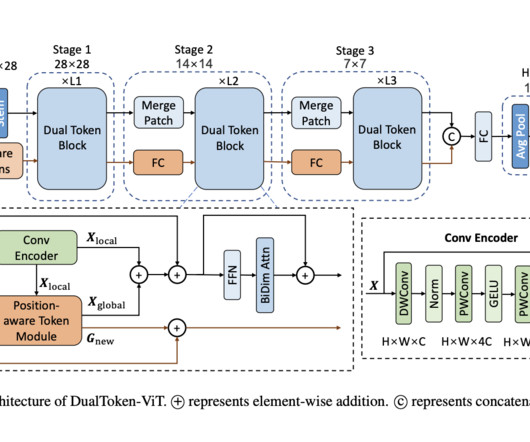
Additionally, they employ position-aware global tokens at every level to improve global dataquality. All Credit For This Research Goes To the Researchers on This Project. This can lower the computational cost of self-attention in global information broadcasting. If you like our work, you will love our newsletter.
They classify their analyses into four categories: Data statistics (e.g., Dataquality (e.g., All Credit For This Research Goes To the Researchers on This Project. number of tokens and domain distribution). measuring duplicate documents and most frequent n-grams). Community- and society-relevant measurements (e.g.,
You might also enjoy the practical tutorials on building an AIresearch agent using Pydantic AI and the step-by-step guide on fine-tuning the PaliGemma2 model for object detection. Meme shared by ghost_in_the_machine TAI Curated section Article of the week Pydantic AI + Web Scraper + Llama 3.3 Meme of the week!
By focusing on the most valuable data, the model learns richer and more nuanced patterns, allowing it to perform better on unseen data and handle unexpected situations. We also need better ways to evaluate dataquality and ensure efficient interaction between data selection and annotation.
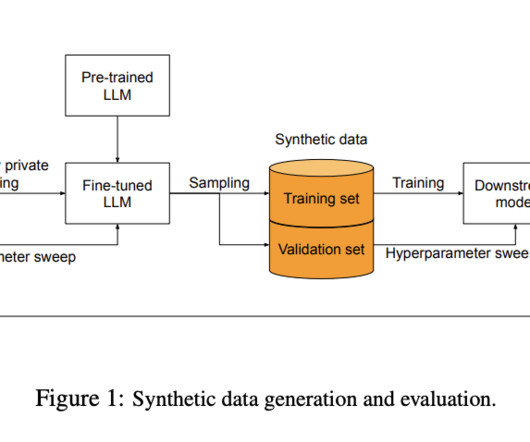
Google AIresearchers describe their novel approach to addressing the challenge of generating high-quality synthetic datasets that preserve user privacy, which are essential for training predictive models without compromising sensitive information.
Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges. While these methods enhance model capabilities through architectural designs and pre-trained language models, dataquality and quantity limitations persist. We are also on Telegram and WhatsApp.
Advantages of vector databases Spatial Indexing – Vector databases use spatial indexing techniques like R-trees and Quad-trees to enable data retrieval based on geographical relationships, such as proximity and confinement, which makes vector databases better than other databases.
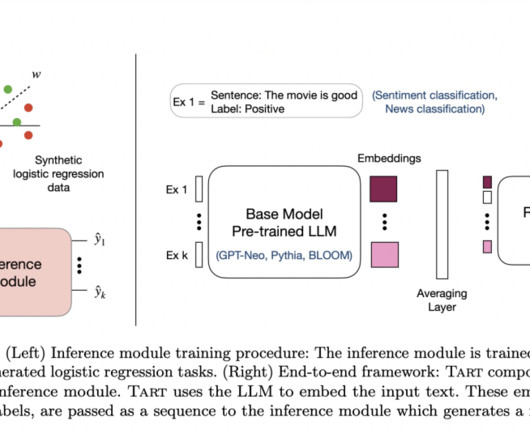
In particular, Tart achieves the necessary goals: • Task-neutral: Tart’s inference module must be trained once with fictitious data. Quality: Performs better than basic LLM across the board and closes the gap using task-specific fine-tuning techniques. Data-scalable: Handling 10 times as many instances as in-context learning.
More crucially, they include 40+ quality annotations — the result of multiple ML classifiers on dataquality, minhash results that may be used for fuzzy deduplication, or heuristics. All Credit For This Research Goes To the Researchers on This Project. If you like our work, you will love our newsletter.
Much of current AIresearch aims to design LLMs that seek helpful, truthful, and harmless behavior. While such studies are still missing a full view of the landscape, they suggest that focusing on the dataquality might be way more beneficial than prioritizing scalability when fine-tuning LLMs.
A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to dataquality. Going forward there’s a lot of room for “hybrid AI” approaches that blend the best of both, and GraphRAG is probably just the tip of the iceberg.
These extreme depictions create unrealistic expectations and unfounded fears, obscuring the nuanced reality of AI. The constant evolution of AIresearch and development introduces discoveries and innovations regularly.
However, there are several obstacles to overcome, especially when dealing with complex scenarios, because of the wide range of picture resolutions and the need for more training dataquality. Furthermore, LLaVA is innovative in extending instruction-tuning into multimodal situations by fusing multimodal instruction-following data.
If adding more data doesn’t improve model performance, it is redundant and doesn’t provide the models with any new information to learn. The study supports a growing body of knowledge among experts in AI across multiple domains: models trained on relatively small datasets can perform well, provided the dataquality is high.
Let’s download the dataframe with: import pandas as pd df_target = pd.read_parquet("[link] /Listings/airbnb_listings_target.parquet") Let’s simulate a scenario where we want to assert the quality of a batch of production data. These constraints operate on top of statistical summaries of data, rather than on the raw data itself.
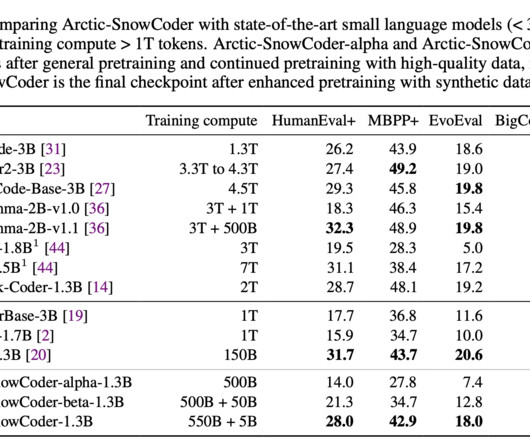
PERsD introduced a method for customizing labeled data to student model capacity, yielding more effective learning. PERsD outperformed standard distillation in code generation on HumanEval and MBPP datasets, benefiting from higher dataquality, multi-round distillation, and self-rectification via execution feedback.
The navigator then evaluates the fidelity of these instructions, filtering out low-qualitydata to train a better generator in subsequent iterations. This iterative refinement ensures continuous improvement in both the dataquality and the models’ performance. Trending: LG AIResearch Releases EXAONE 3.5:
Structured data is important in this process, as it provides a clear and organized framework for the AI to learn from, unlike messy or unstructured data, which can lead to ambiguities. Employ Data Templates With dataquality, implementing data templates offers another layer of control and precision.
High-Risk AI: These include critical applications like medical AI tools or recruitment software. They must meet strict standards for accuracy, security, and dataquality, with ongoing human oversight. Content like deep fakes should be labeled to show it’s artificially made.
They explore the complexities and challenges of AI technology, focusing on Retrieval Augmented Generation (RAG), the importance of great documentation, and the potential of emerging multimodal models like Gemini. They also explore the technical aspects of chunking strategies and dataquality in RAG systems.
It maintains dataquality through a TRM, by scoring synthesized trajectories along dimensions of coherence, logical flow, and completeness. Even partial but meaningful data can be trained in such an approach. All credit for this research goes to the researchers of this project.
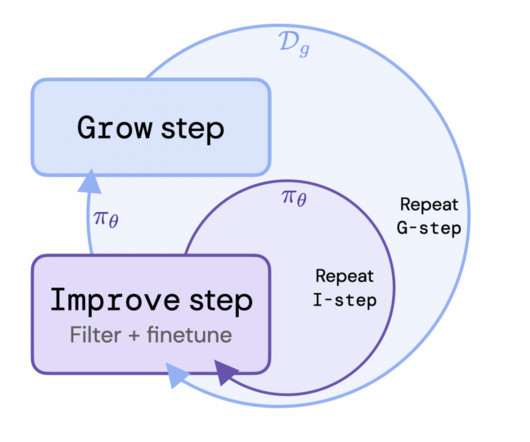
. • Since new training data is sampled from an improved policy during the Grow step, the quality of the policy is not constrained by the quality of the original dataset (unlike in offline RL). • All Credit For This Research Goes To the Researchers on This Project.
What happened this week in AI by Louie The ongoing race between open and closed-source AI has been a key theme of debate for some time, as has the increasing concentration of AIresearch and investment into transformer-based models such as LLMs. comparable to much larger and more expensive models such as GPT-4.
Key elements driving these developments are using the potent Large Language Model (LLM) as a text encoder, scaling up training datasets, increasing model complexity, better sampling strategy design, and improving dataquality. All credit for this research goes to the researchers of this project.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content