This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, when training computervision models, anonymized data can impact accuracy due to losing vital information. Researchers continuously seek methods to maintain data utility while ensuring privacy. In this work, the authors examined the effects of anonymization on computervision models for autonomous vehicles.
AIresearch labs invest millions in high-performance hardware just to keep up with computational demands. Meta AI is addressing this challenge head-on with Scalable Memory Layers (SMLs), a deep learning approach designed to overcome dense layer inefficiencies. Meta AI has introduced SMLs to solve this problem.
The machine learning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
The popularity of NLP encourages a complementary strategy in computervision. Unique obstacles arise from the necessity for broad perceptual capacities in universal representation for various vision-related activities. If you like our work, you will love our newsletter.
In academic research, particularly in computervision, keeping track of conference papers can be a real challenge. Researchers have to spend a lot of time manually searching for this information on platforms like Google Scholar or DBLP, which can be time-consuming and frustrating.
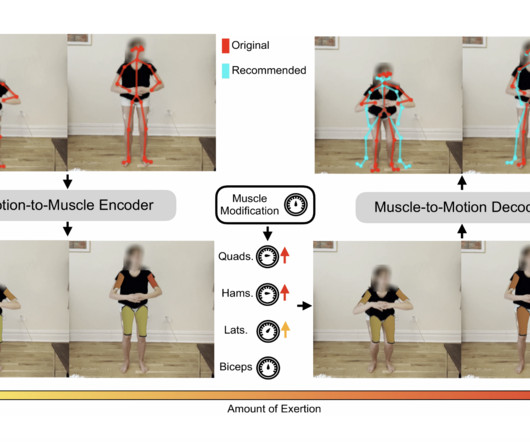
MaskedMimic: Reconstructing Realistic Movement for Humanoid Robots To advance the development of humanoid robots, NVIDIA researchers introduced MaskedMimic , an AI framework that applies inpainting the process of reconstructing complete data from an incomplete, or masked, view to descriptions of motion.
Combining data from satellites, ground-based cameras, aerial observations and local weather information, OroraTech detects threats to natural habitats and alerts users in real time. Wild Me supports over 2,000 researchers across the globe running AI-enabled wildlife population studies for marine and terrestrial species.
In the News Elon Musk unveils new AI company set to rival ChatGPT Elon Musk, who has hinted for months that he wants to build an alternative to the popular ChatGPT artificial intelligence chatbot, announced the formation of what he’s calling xAI, whose goal is to “understand the true nature of the universe.” Powered by pluto.fi theage.com.au
Humans pick up a tremendous quantity of background information about the world just by watching it. The Meta team has been working on developing computers that can learn internal models of how the world functions to let them learn much more quickly, plan out how to do challenging jobs, and quickly adapt to novel conditions since last year.
based on Natural Language Processing and Natural Language Understanding or the text-to-image model called DALL-E based on Computervision, AI is paving its way toward success. Computervision, the sub-field of AI, is getting better with the release of every new application.
Rohan Malhotra is the CEO, founder and director of Roadzen , a global insurtech company advancing AI at the intersection of mobility and insurance. Roadzen has pioneered computervisionresearch, generative AI and telematics including tools and products for road safety, underwriting and claims.
Traditional AI methods have been designed to extract information from objects encoded by somewhat “rigid” structures. What is the current role of GNNs in the broader AIresearch landscape? Let’s take a look at some numbers revealing how GNNs have seen a spectacular rise within the research community.
Artificial intelligence (AI) research has increasingly focused on enhancing the efficiency & scalability of deep learning models. These models have revolutionized natural language processing, computervision, and data analytics but have significant computational challenges.
In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training. Theory of Mind AI Theory of Mind AI is a functional class of AI that falls underneath the General AI.
In-depth testing has created a model that can extract 3D information from 2D photos, making cameras more advantageous for these new technologies. However, that is only helpful if the AI in the autonomous car can separate 3D navigational data from the 2D images captured by a camera. If you like our work, you will love our newsletter.
cryptopolitan.com Applied use cases Alluxio rolls out new filesystem built for deep learning Alluxio Enterprise AI is aimed at data-intensive deep learning applications such as generative AI, computervision, natural language processing, large language models and high-performance data analytics. voxeurop.eu
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. For many reasons, it is difficult for today’s most advanced vision-language models (VLMs) to respond satisfactorily to such inquiries.
Featured Community post from the Discord Malus_aiiola has built an AI voice Gatekeeper agent that handles incoming calls for busy CEOs. In this video, he breaks down how you can benefit from an AI voice Gatekeeper, which will answer for you and record the information of the caller. AI poll of the week! Is Devin promising?
Generative AI is igniting a new era of innovation within the back office. And this is particularly true for accounts payable (AP) programs, where AI, coupled with advancements in deep learning, computervision and natural language processing (NLP), is helping drive increased efficiency, accuracy and cost savings for businesses.
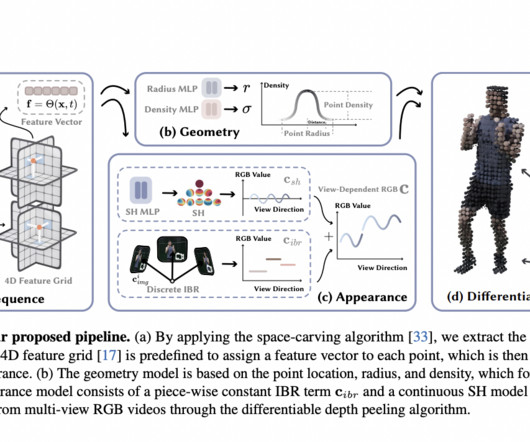
Dynamic view synthesis is a computervision and graphic task attempting to reconstruct dynamic 3D scenes from captured videos and generate immersive virtual playback. However, this strategy introduces a challenge in discrete behavior along the viewing direction, which is mitigated using the continuous SH model.
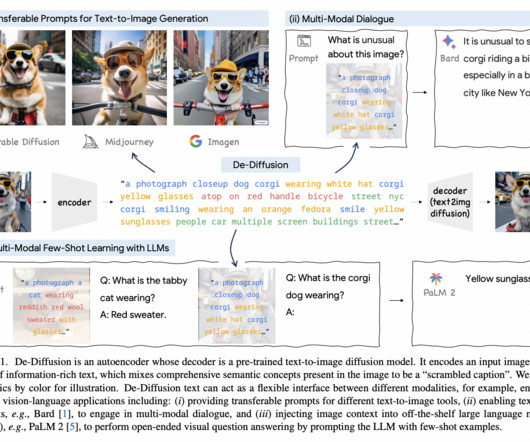
Additionally, transcribed text is believed to encapsulate all the necessary semantic information. This was the summary of De-Diffusion, a novel AI technique to convert an input image into a piece of information-rich text that can act as a flexible interface between different modalities, enabling diverse audio-vision-language applications.
The yet-unnamed tool would give scientists "superpowers," Alan Karthikesalingam, an AIresearcher at Google, told New Scientist last month. And even biomedical researchers at Imperial College London, who got to use an early version of the AI model, eagerly claimed it would "supercharge science."
This integration allows LLMs to access real-time, relevant information, thereby addressing the limitations of traditional generative models that rely solely on static training data. Techniques such as vector-based retrieval and query expansion are commonly used to improve the relevance and accuracy of the retrieved information.
Furthermore, it seeks to ensure that all nations, particularly those in the developing world, can equally access and benefit from AI advancements. fintech.global New AI Technology Meets the Maternity Ward Ever.Ag has introduced “Maternity Warden,” a computervision monitoring device that monitors close-up dry cows.
In computervision and robotics, simultaneous localization and mapping (SLAM) with cameras is a key topic that aims to allow autonomous systems to navigate and understand their environment. The post This AIResearch Unveils Photo-SLAM: Elevating Real-Time Photorealistic Mapping on Portable Devices appeared first on MarkTechPost.
Powered by superai.com In the News 20 Best AI Chatbots in 2024 Generative AI chatbots are a major step forward in conversational AI. These chatbots are powered by large language models (LLMs) that can generate human-quality text, translate languages, write creative content, and provide informative answers to your questions.
These streams include RGB (red, green, and blue), depth, audio, head, hand, and gaze tracking information. By using this design, researchers can get beyond the headset’s present computing limits and open the door to possibilities for expanding the program to additional mixed-reality devices.
For more information, refer to Deploy models for inference. Access to Hugging Face Hub You must have access to Hugging Face Hubs deepseek-ai/DeepSeek-R1-Distill-Llama-8B model weights from your environment. Out-of-the-box tools with CrewAI Crew AI offers a range of tools out of the box for you to use along with your agents and tasks.
In the realm of computervision systems, a similar issue occurs. This network incorporates valuable information in the form of local features and 2D correspondence to enhance the performance of the visual disambiguation task. All Credit For This Research Goes To the Researchers on This Project. Or does he?
With the growing advancements in the field of Artificial Intelligence, its sub-fields, including Natural Language Processing, Natural Language Generation, ComputerVision, etc., Optical Character Recognition (OCR) is a well-established and heavily investigated area of computervision.
Top 10 AIResearch Papers 2023 1. Sparks of AGI by Microsoft Summary In this research paper, a team from Microsoft Research analyzes an early version of OpenAI’s GPT-4, which was still under active development at the time. Sign up for more AIresearch updates. Enjoy this article?
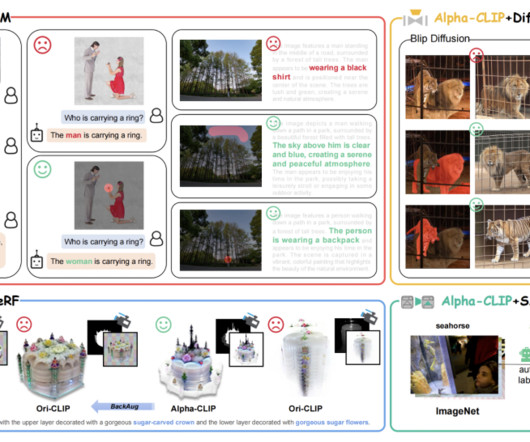
Alpha-CLIP introduces an alpha channel to preserve contextual information while concentrating on designated areas without modifying content. The Alpha-CLIP method is introduced, featuring an additional alpha channel to focus on specific areas without content alteration, thereby preserving contextual information.
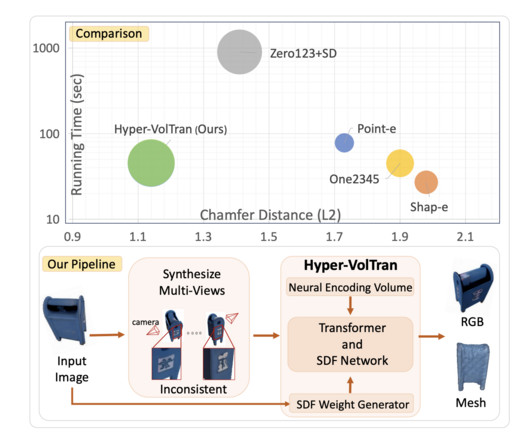
In the swiftly evolving domain of computervision, the breakthrough in transforming a single image into a 3D object structure is a beacon of innovation. The task is inherently complex due to the need for more information about unseen aspects of the object. All credit for this research goes to the researchers of this project.
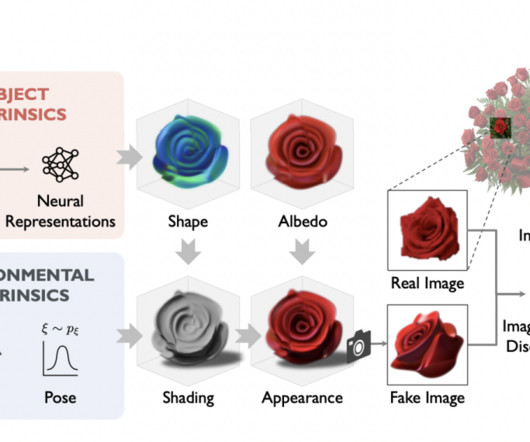
No two roses are alike, and there is a need to capture a distribution of their shape, texture, and material to take advantage of the underlying multi-view information. Don’t forget to join our 25k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
questions, these models cannot accurately localize periods and often hallucinate irrelevant information. Second, the architecture of existing Video LLMs might need more temporal resolution to interpolate time information accurately. In particular, LITA achieves a 22% improvement in the Correctness of Information (2.94
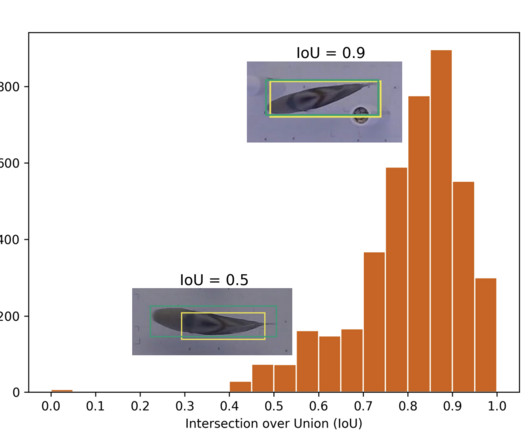
Addressing these challenges, a UK-based research team introduced a hybrid method, merging deep learning and traditional computervision techniques to enhance tracking accuracy for fish in complex experiments. On the other hand, traditional computervision techniques are used in the tracking process.
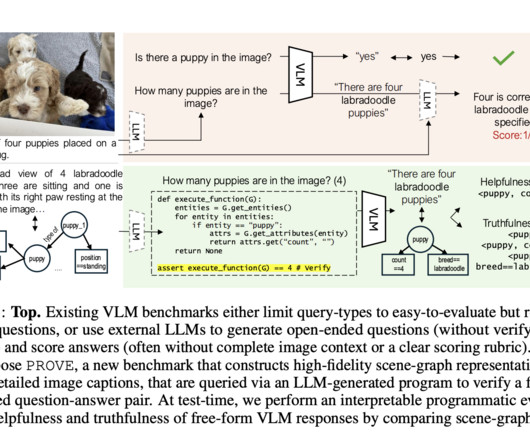
Researchers from Salesforce AIResearch have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. Don’t Forget to join our 55k+ ML SubReddit.
Single-view 3D reconstruction stands at the forefront of computervision, presenting a captivating challenge and immense potential for various applications. Overcoming this challenge has been a focal point in the realm of computervisionresearch, leading to innovative methodologies and advancements.
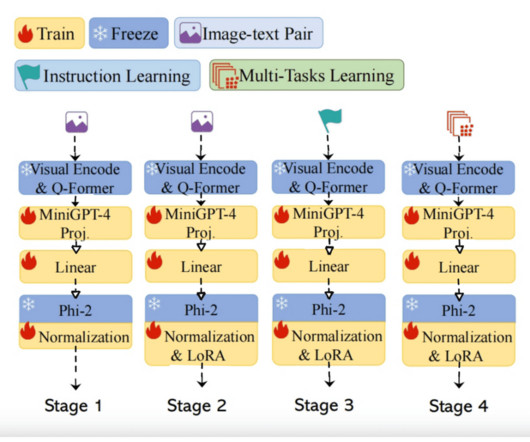
The model’s structure also includes linear projection layers that embed visual features into the language model, facilitating a more efficient understanding of image-based information. These projection layers are initialized with a Gaussian distribution, bridging the gap between the visual and language modalities.
Artificial Intelligence is booming, and so is its sub-field, i.e., the domain of ComputerVision. From researchers and academics to scholars, it is getting a lot of attention and is making a big impact on a lot of different industries and applications, like computer graphics, art and design, medical imaging, etc.
The proposed method takes advantage of the T2I model to draw from the much larger dataset of image-text pairs, which is more diverse and information-rich than the dataset of video-text pairs. All Credit For This Research Goes To the Researchers on This Project. The resulting video’s visual quality has improved.
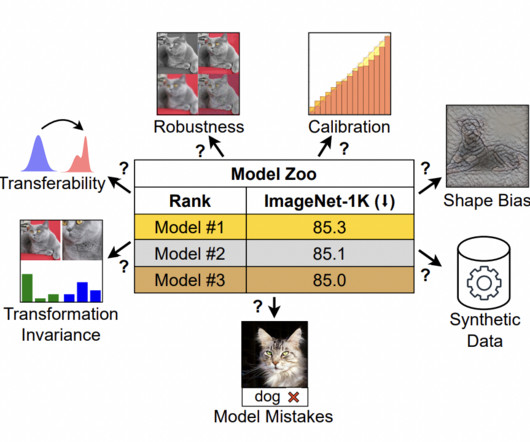
There has been a dramatic increase in the complexity of the computervision model landscape. Many models are now at your fingertips, from the first ConvNets to the latest Vision Transformers. To fill this gap, a new study by MBZUAI and Meta AIResearch investigates model characteristics beyond ImageNet correctness.
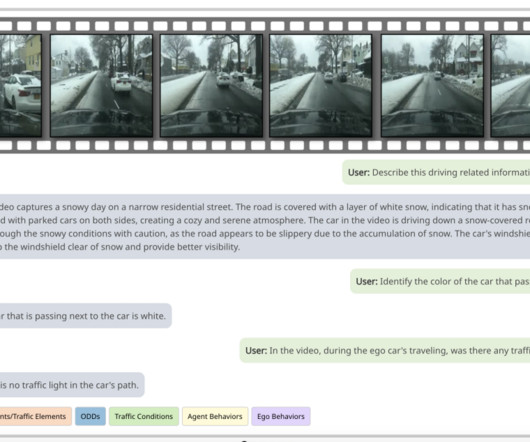
A team of researchers from the University of Wisconsin-Madison, NVIDIA, the University of Michigan, and Stanford University have developed a new vision-language model (VLM) called Dolphins. It is a conversational driving assistant that can process multimodal inputs to provide informed driving instructions.
is a state-of-the-art vision segmentation model designed for high-performance computervision tasks, enabling advanced object detection and segmentation workflows. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content