This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
What role does metadata authentication play in ensuring the trustworthiness of AI outputs? What role does metadata authentication play in ensuring the trustworthiness of AI outputs? Metadata authentication helps increase our confidence that assurances about an AImodel or other mechanism are reliable.
Alibaba Cloud has open-sourced more than 100 of its newly-launched AImodels, collectively known as Qwen 2.5. The cloud computing arm of Alibaba Group has also unveiled a revamped full-stack infrastructure designed to meet the surging demand for robust AI computing.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AImodels to increase transparency around generated content.
DuckDuckGo has released a platform that allows users to interact with popular AI chatbots privately, ensuring that their data remains secure and protected. Users can choose from four AImodels: two closed-source models and two open-source models. The closed-source models are OpenAI’s GPT-3.5
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. It offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI practices.
In this article, we’ll examine the barriers to AI adoption, and share some measures that business leaders can take to overcome them. ” Today, only 43% of IT professionals say they’re confident about their ability to meet AI’s data demands. ”There’s a huge set of issues there.
OctoTools is a modular, training-free, and extensible framework that standardizes how AImodels interact with external tools. Unlike previous frameworks that require predefined tool configurations, OctoTools introduces tool cards, which encapsulate tool functionalities and metadata.
Rightsify’ s Global Copyright Exchange (GCX) offers vast collections of copyright-cleared music datasets tailored for machine learning and generative AI music initiatives. Text, Stem, MIDI, and sheet music pairings for audio are bundled with their AI music datasets, furnishing comprehensive resources for ML projects.
Instead of solely focusing on whos building the most advanced models, businesses need to start investing in robust, flexible, and secure infrastructure that enables them to work effectively with any AImodel, adapt to technological advancements, and safeguard their data. AImodels are just one part of the equation.
So, how can AI help with curating trial site selection? By training AImodels with the historical and real-time data of potential sites, trial sponsors can predict patient enrollment rates and a sites performance optimizing site allocation, reducing over- or under-enrollment, and improving overall efficiency and cost.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI. It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse.
It is critical for AImodels to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. When using the FAISS adapter (vector search), translation unit groupings are parsed and turned into vectors using the selected embedding model from Amazon Bedrock.
The tasks behind efficient, responsible AI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly. Here’s what’s involved in making that happen.
Meanwhile, structured metadata and processed results are housed in Amazon RDS, enabling fast queries and integration with enterprise applications. For example, if an AImodel detects a critical defect, Step Functions can initiate a maintenance request in SAP, notify engineers, and schedule repairs without human intervention.
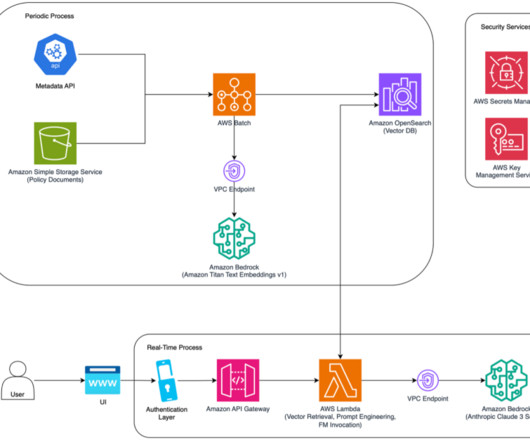
An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database. Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey.
Best Practices to Mitigate Generative AI Plagiarism Here are some best practices both AI developers and users can adopt to minimize plagiarism risks: For AI developers: Carefully vet training data sources to exclude copyrighted or licensed material without proper permissions. Record metadata like licenses, tags, creators, etc.
With robust security measures, data privacy safeguards, and a cost-effective pay-as-you-go model, Amazon Bedrock offers a secure, flexible, and cost-efficient service to harness generative AIs potential in enhancing customer service analytics, ultimately leading to improved customer experiences and operational efficiencies.
A lack of confidence to operationalize AI Many organizations struggle when adopting AI. According to Gartner , 54% of models are stuck in pre-production because there is not an automated process to manage these pipelines and there is a need to ensure the AImodels can be trusted.
Editor’s note: This post is part of the AI Decoded series , which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users. The new ChatRTX release also lets people chat with their data using their voice.
AImodels often need access to real-time data for training and inference, so the database must offer low latency to enable real-time decision-making and responsiveness. This is one of the biggest challenges organisations face when building AI-powered applications, and it’s precisely what MongoDB is designed to handle.
1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments. With watsonx.data, businesses will be able to build trustworthy AImodels and automate AI life cycles on multicloud architectures, taking full advantage of interoperability with IBM and third-party services.
There are three areas of AI in particular that will always require human involvement to achieve optimal outcomes. Building a robust data foundation is critical, as the underlying data model with proper metadata, data quality, and governance is key to enabling AI to achieve peak efficiencies. Continuous training.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Track models and drive transparent processes. Increase trust in AI outcomes.
The approach incorporates over 20 modalities, including SAM segments, 3D human poses, Canny edges, color palettes, and various metadata and embeddings. The method incorporates a wide range of modalities, including RGB, geometric, semantic, edges, feature maps, metadata, and text.
For years IBM has been using cutting-edge AI to improve the digital experiences found in the Masters app. We taught an AImodel to analyze Masters video and produce highlight reels for every player, minutes after their round is complete. We built models that generate scoring predictions for every player on every hole.
By embedding metadata into images and other digital files, Adobe enables artists to assert ownership and trace the origin of their work. Additionally, Adobe has implemented licensing mechanisms within Firefly that empower artists to be part of the AI training process on their own terms.
The funding will allow ApertureData to scale its operations and launch its new cloud-based service, ApertureDB Cloud, a tool designed to simplify and accelerate the management of multimodal data, which includes images, videos, text, and related metadata. ApertureData’s flagship product, ApertureDB , addresses this challenge head-on.
This is achieved through responsible AI, with Amazon Bedrock Data Automation passing every process through a responsible AImodel to help ensure fairness, accuracy, and compliance in document automation. These analytics are implemented with either Amazon Comprehend , or separate prompt engineering with FMs.
The image was generated using the Stability AI (SDXL 1.0) model on Amazon Bedrock. The following screenshot shows the prompt and the model’s response. For example, we provide the following image of a cake to the model to extract the recipe. The image was generated using the Stability AImodel (SDXL 1.0)
Even today, a vast chunk of machine learning and deep learning techniques for AImodels rely on a centralized model that trains a group of servers that run or train a specific model against training data, and then verifies the learning using validation or training dataset.
FineVideo addresses this gap by enabling researchers to explore various video features, from mood transitions to plot twists, providing a fertile ground for training AImodels capable of context-aware video analysis. With an average video length of 4.7 or “What is the mood of the operator during the training?”
This approach is known as self-supervised learning , and it’s one of the most efficient methods to build ML and AImodels that have the “ common sense ” or background knowledge to solve problems that are beyond the capabilities of AImodels today.
Next, the teams trained a foundation model using watsonx.ai , a powerful studio for training, validating, tuning and deploying generative AImodels for business.
AI notetakers that can now generate highly accurate and hallucination-free meeting notes to serve as the basis for LLM-powered summaries, action items, and other metadata generation with accurate proper noun, speaker, and timing information included. At AssemblyAI, we use a combination of models to produce your results.
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. Turbo AImodel for intelligent processing, and ElevenLabs for speech synthesis. Summarize audio data : Discover how to quickly summarize your audio data with key takeaways using LeMUR.
It “…provides a structured approach to the safe development, deployment and use of generative AI. In doing so, the framework highlights gaps and opportunities in addressing safety concerns, viewed from the perspective of four primary actors: AImodel creators, AImodel adapters, AImodel users, and AI application users.”
For industries providing essential services to clients such as insurance, banking and retail, the law requires the use of a fundamental rights impact assessment that details how the use of AI will affect the rights of customers. Higher risk tiers have more transparency requirements including model evaluation, documentation and reporting.
These models tend to reinforce their understanding based on previously assimilated answers. The groundwork of training data in an AImodel is comparable to piloting an airplane. The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions.
Concerns to consider with off the shelf generative AImodels include: Internet data is not always fair and accurate At the heart of much of generative AI today is vast amounts of data from sources such as Wikipedia, websites, articles, image or audio files, etc. What is watsonx.governance?
As generative AImodels advance in creating multimedia content, the difference between good and great output often lies in the details that only human feedback can capture. The path to creating effective AImodels for audio and video generation presents several distinct challenges.
Utilizing blockchain technology to record and store the training data, input and output of the models, and parameters, ensuring accountability, and transparency in model audits. Using blockchain frameworks to deploy AImodels to achieve decentralization services among models, and enhancing the scalability and stability of the system.
It uses metadata and data management tools to organize all data assets within your organization. An enterprise data catalog automates the process of contextualizing data assets by using: Business metadata to describe an asset’s content and purpose. Technical metadata to describe schemas, indexes and other database objects.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content