This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
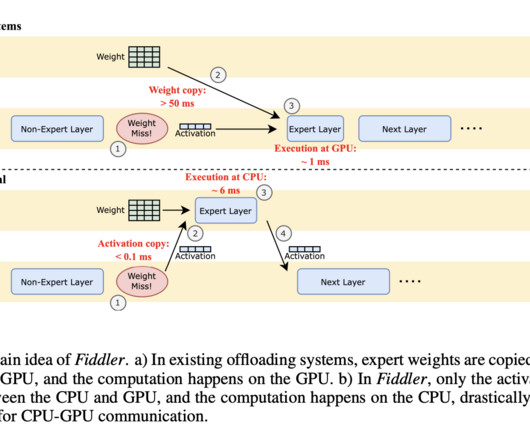
This methodology drastically cuts down the latency for CPU-GPU communication, enabling the system to run large MoE models, such as the Mixtral-8x7B with over 90GB of parameters, efficiently on a single GPU with limited memory. Fiddler’s design showcases a significant technical innovation in AImodel deployment.
Run AI recently announced an open-source solution to tackle this very problem: Run AI: Model Streamer. This tool aims to drastically cut down the time it takes to load inferencemodels, helping the AI community overcome one of its most notorious technical hurdles. Don’t Forget to join our 55k+ ML SubReddit.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AImodels for inference. 70B model showed significant and consistent improvements in end-to-end (E2E) scaling times.
Organizations require models that are adaptable, secure, and capable of understanding domain-specific contexts while also maintaining compliance and privacy standards. Traditional AImodels often struggle with delivering such tailored performance, requiring businesses to make a trade-off between customization and general applicability.
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google Researchers Introduce UNBOUNDED: An Interactive Generative Infinite Game based on Generative AIModels appeared first on MarkTechPost.
You can reattach to your Docker container and stop the online inference server with the following: docker attach $(docker ps --format "{{.ID}}") Create a file for using the offline inferenceengine: cat > offline_inference.py <<EOF from vllm.entrypoints.llm import LLM from vllm.sampling_params import SamplingParams # Sample prompts.
Financial practitioners can now leverage an AI that understands the nuances and complexities of market dynamics, offering insights with unparalleled accuracy. Hawkish 8B represents a promising development in AImodels focused on finance. Don’t Forget to join our 55k+ ML SubReddit.
AI, particularly through ML and DL, has advanced medical applications by automating complex tasks. ML algorithms learn from data to improve over time, while DL uses neural networks to handle large, complex datasets. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems.
Current generative AImodels face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Don’t Forget to join our 50k+ ML SubReddit.
High-performance AImodels that can run at the edge and on personal devices are needed to overcome the limitations of existing large-scale models. These models require significant computational resources, making them dependent on cloud environments, which poses privacy risks, increases latency, and adds costs.
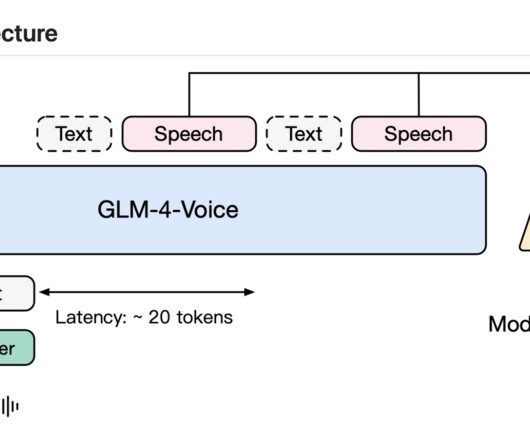
Modern AImodels excel in text generation, image understanding, and even creating visual content, but speech—the primary medium of human communication—presents unique hurdles. Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Generative AImodels have become highly prominent in recent years for their ability to generate new content based on existing data, such as text, images, audio, or video. A specific sub-type, diffusion models, produces high-quality outputs by transforming noisy data into a structured format.
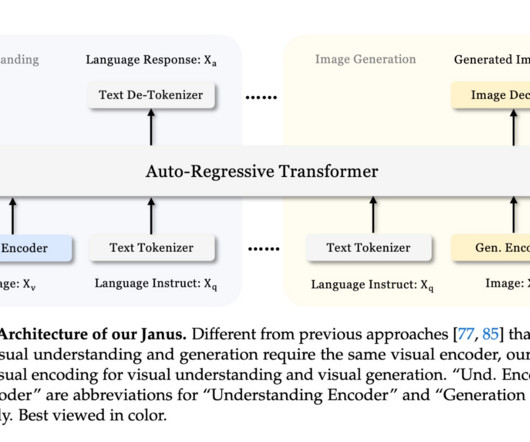
Multimodal AImodels are powerful tools capable of both understanding and generating visual content. In conclusion, Janus presents a major step forward in developing unified multimodal AImodels by resolving the conflicts between understanding and generation. Don’t Forget to join our 50k+ ML SubReddit.
By doing so, Meta AI aims to enhance the performance of large models while reducing the computational resources needed for deployment. This makes it feasible for both researchers and businesses to utilize powerful AImodels without needing specialized, costly infrastructure, thereby democratizing access to cutting-edge AI technologies.
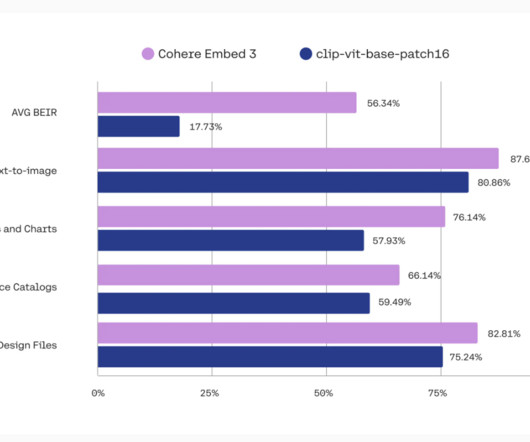
In an increasingly interconnected world, understanding and making sense of different types of information simultaneously is crucial for the next wave of AI development. Cohere has officially launched Multimodal Embed 3 , an AImodel designed to bring the power of language and visual data together to create a unified, rich embedding.
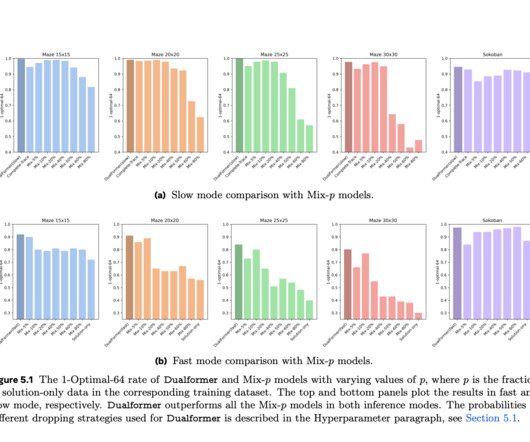
A major challenge in AI research is how to develop models that can balance fast, intuitive reasoning with slower, more detailed reasoning in an efficient way. In AImodels, this dichotomy between the two systems mostly presents itself as a trade-off between computational efficiency and accuracy.
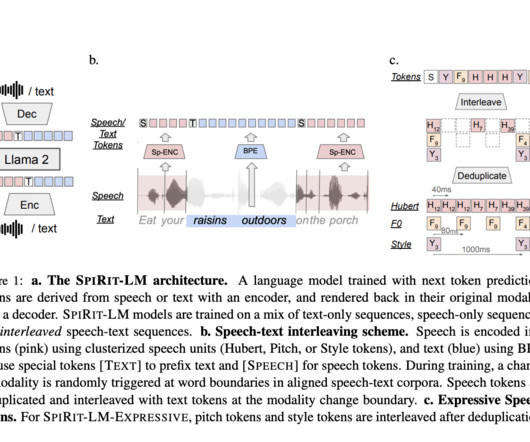
The model is capable of few-shot learning for tasks across modalities, such as automatic speech recognition (ASR), text-to-speech (TTS), and speech classification. This versatility positions Meta Spirit LM as a significant improvement over traditional multimodal AImodels that typically operate in isolated domains.
Code generation AImodels (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. These models may inadvertently introduce insecure code, which could be exploited in cyberattacks. Don’t Forget to join our 50k+ ML SubReddit.
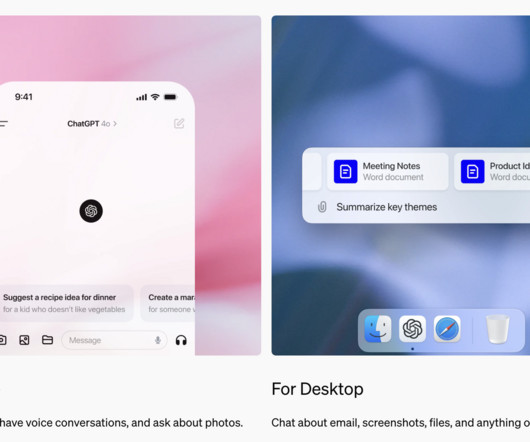
The ChatGPT Windows app delivers a native desktop experience for users, designed to improve interaction with the AImodel. With the release of this dedicated app, OpenAI aims to extend the reach and convenience of its conversational AI. Don’t Forget to join our 50k+ ML SubReddit.
The impressive multimodal abilities and interactive experience of new AImodels like GPT-4o highlight its critical role in practical applications, yet it needs a high-performing open-source counterpart. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
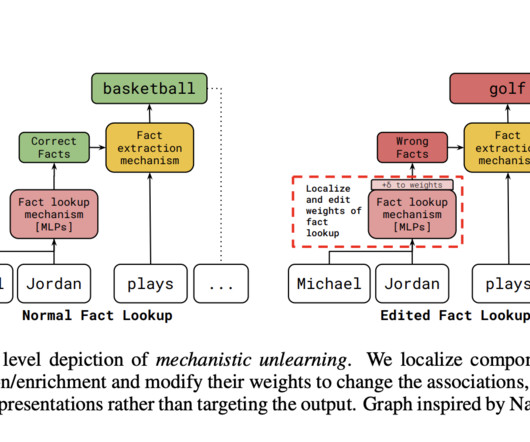
Mechanistic Unlearning is a new AI method that uses mechanistic interpretability to localize and edit specific model components associated with factual recall mechanisms. The study examines methods for removing information from AImodels and finds that many fail when prompts or outputs shift.
Addressing this challenge requires a model capable of efficiently handling such diverse content. Introducing mcdse-2b-v1: A New Approach to Document Retrieval Meet mcdse-2b-v1 , a new AImodel that allows you to embed page or slide screenshots and query them using natural language. Don’t Forget to join our 55k+ ML SubReddit.
Generative artificial intelligence (AI) models are designed to create realistic, high-quality data, such as images, audio, and video, based on patterns in large datasets. These models can imitate complex data distributions, producing synthetic content resembling samples. Don’t Forget to join our 55k+ ML SubReddit.
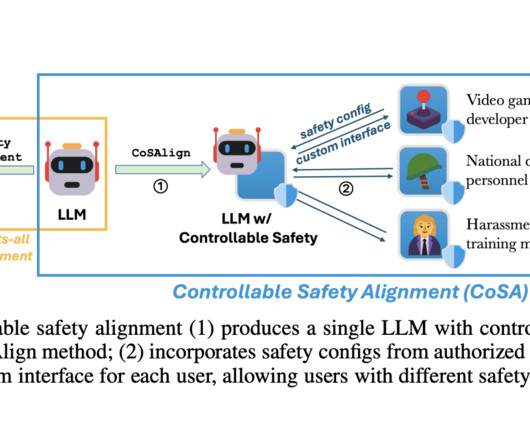
This allows the model to adapt its safety settings during use without retraining, and users can access the customized model through special interfaces, like specific API endpoints. The CoSA project aims to develop AImodels that can meet specific safety requirements, especially for content related to video game development.
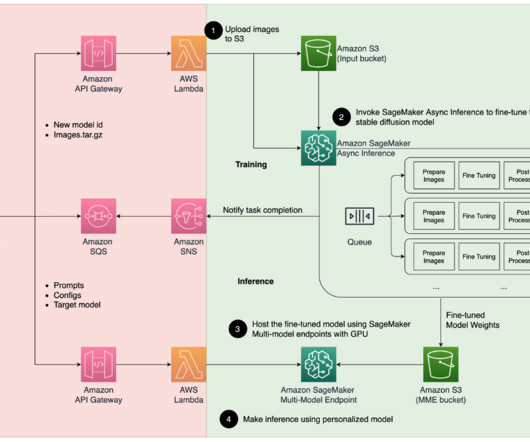
In this post, we demonstrate how you can use generative AImodels like Stable Diffusion to build a personalized avatar solution on Amazon SageMaker and save inference cost with multi-model endpoints (MMEs) at the same time. amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117" deepspeed0.8.3-cu117"
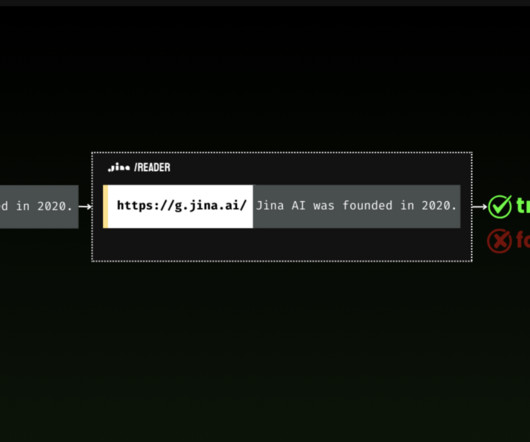
Jina AI announced the release of their latest product, g.jina.ai , designed to tackle the growing problem of misinformation and hallucination in generative AImodels. This innovative tool is part of their larger suite of applications to improve factual accuracy and grounding in AI-generated and human-written content.
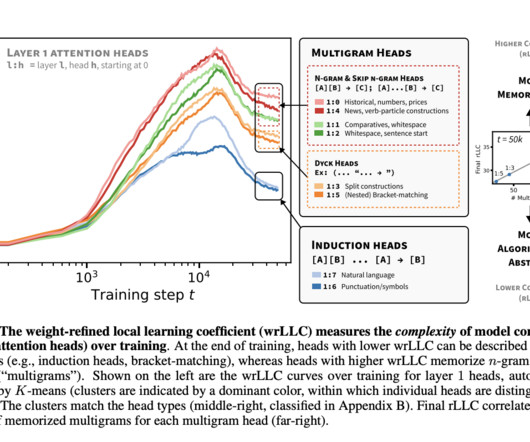
Artificial intelligence (AI) and machine learning (ML) revolve around building models capable of learning from data to perform tasks like language processing, image recognition, and making predictions. A significant aspect of AI research focuses on neural networks, particularly transformers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content