This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Efficiently managing and coordinating AIinference requests across a fleet of GPUs is a critical endeavour to ensure that AI factories can operate with optimal cost-effectiveness and maximise the generation of token revenue. Dynamo orchestrates and accelerates inference communication across potentially thousands of GPUs.
This is not the sound of an AI boom going bust, but there has been a growing unease around how much money is being spent on enabling AI applications. One was an understanding that DeepSeek did not invent a new way to work with AI. After AImodels have been trained, things change.
This is where inference APIs for open LLMs come in. These services are like supercharged backstage passes for developers, letting you integrate cutting-edge AImodels into your apps without worrying about server headaches, hardware setups, or performance bottlenecks. The potential is there, but the performance?
Predibase announces the Predibase InferenceEngine , their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase InferenceEngine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
In tests like AIModeling Efficiency (AIME) and General Purpose Question Answering (GPQA), Grok-3 has consistently outperformed other AI systems. This ability is supported by advanced technical components like inferenceengines and knowledge graphs, which enhance its reasoning skills.
Ensuring consistent access to a single inferenceengine or database connection. Implementation Here’s how to implement a Singleton pattern in Python to manage configurations for an AImodel: class ModelConfig: """ A Singleton class for managing global model configurations. """ GPU memory ).
Run AI recently announced an open-source solution to tackle this very problem: Run AI: Model Streamer. This tool aims to drastically cut down the time it takes to load inferencemodels, helping the AI community overcome one of its most notorious technical hurdles.
NVIDIA AI Foundry is a service that enables enterprises to use data, accelerated computing and software tools to create and deploy custom models that can supercharge their generative AI initiatives. The key difference is the product: TSMC produces physical semiconductor chips, while NVIDIA AI Foundry helps create custom models.
Organizations require models that are adaptable, secure, and capable of understanding domain-specific contexts while also maintaining compliance and privacy standards. Traditional AImodels often struggle with delivering such tailored performance, requiring businesses to make a trade-off between customization and general applicability.
However, scaling AI across an organization takes work. It involves complex tasks like integrating AImodels into existing systems, ensuring scalability and performance, preserving data security and privacy, and managing the entire lifecycle of AImodels.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google Researchers Introduce UNBOUNDED: An Interactive Generative Infinite Game based on Generative AIModels appeared first on MarkTechPost.
Imagine working with an AImodel that runs smoothly on one processor but struggles on another due to these differences. For developers and researchers, this means navigating complex problems to ensure their AI solutions are efficient and scalable on all types of hardware.
Moreover, to operate smoothly, generative AImodels rely on thousands of GPUs, leading to significant operational costs. The high operational demands are a key reason why generative AImodels are not yet effectively deployed on personal-grade devices.
NVIDIA NIM microservices, part of the NVIDIA AI Enterprise software platform, together with Google Kubernetes Engine (GKE) provide a streamlined path for developing AI-powered apps and deploying optimized AImodels into production.
Financial practitioners can now leverage an AI that understands the nuances and complexities of market dynamics, offering insights with unparalleled accuracy. Hawkish 8B represents a promising development in AImodels focused on finance. If you like our work, you will love our newsletter.
Intelligent Medical Applications: AI in Healthcare: AI has enabled the development of expert systems, like MYCIN and ONCOCIN, that simulate human expertise to diagnose and treat diseases. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems.
High-performance AImodels that can run at the edge and on personal devices are needed to overcome the limitations of existing large-scale models. These models require significant computational resources, making them dependent on cloud environments, which poses privacy risks, increases latency, and adds costs.
source) Nvidia Inference Microservice (NIM): In simple terms, NIM is a collection of cloud-native microservices that help in deployment of generative AImodels on GPU-accelerated workstations, cloud environments, and data centers. What is Nvidia Nim?
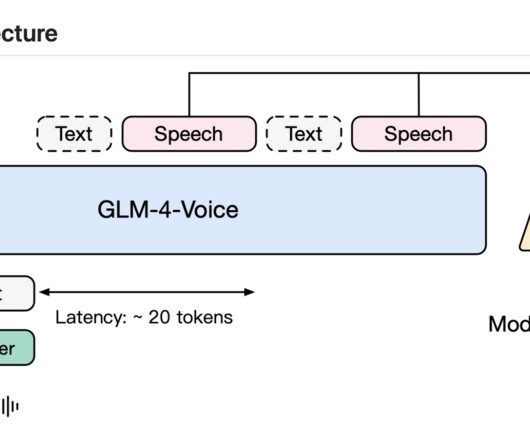
Modern AImodels excel in text generation, image understanding, and even creating visual content, but speech—the primary medium of human communication—presents unique hurdles. Traditional speech recognition systems, though advanced, often struggle with understanding nuanced emotions, variations in dialect, and real-time adjustments.
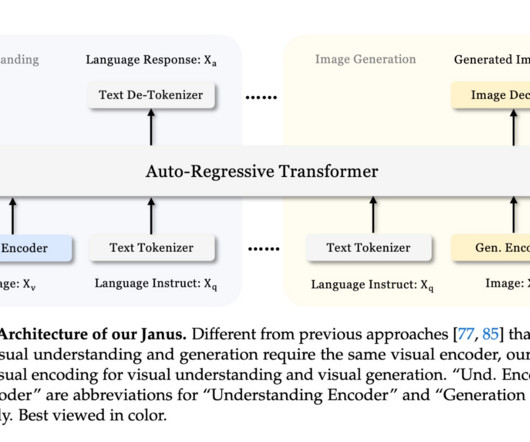
Multimodal AImodels are powerful tools capable of both understanding and generating visual content. In conclusion, Janus presents a major step forward in developing unified multimodal AImodels by resolving the conflicts between understanding and generation. If you like our work, you will love our newsletter.
Generative AImodels have become highly prominent in recent years for their ability to generate new content based on existing data, such as text, images, audio, or video. A specific sub-type, diffusion models, produces high-quality outputs by transforming noisy data into a structured format.
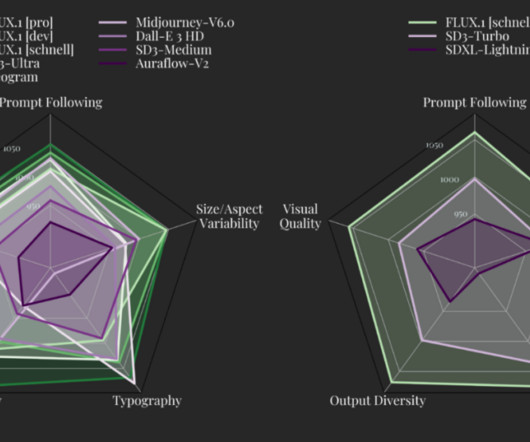
The Birth of Black Forest Labs Before we delve into the technical aspects of Flux, it's crucial to understand the pedigree behind this innovative model. Black Forest Labs is not just another AI startup; it's a powerhouse of talent with a track record of developing foundational generative AImodels.
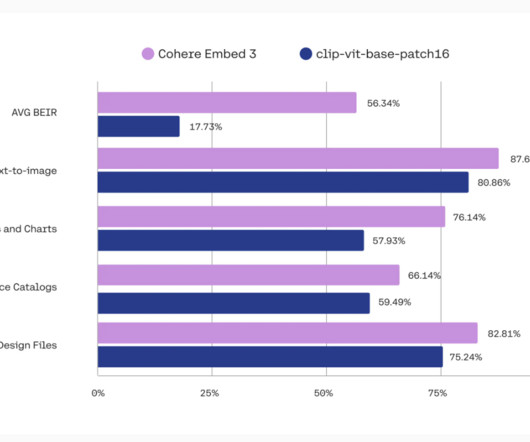
In an increasingly interconnected world, understanding and making sense of different types of information simultaneously is crucial for the next wave of AI development. Cohere has officially launched Multimodal Embed 3 , an AImodel designed to bring the power of language and visual data together to create a unified, rich embedding.
A major challenge in AI research is how to develop models that can balance fast, intuitive reasoning with slower, more detailed reasoning in an efficient way. In AImodels, this dichotomy between the two systems mostly presents itself as a trade-off between computational efficiency and accuracy.
RTX GPUs also take advantage of Tensor Cores — dedicated AI accelerators that dramatically speed up the computationally intensive operations required for deep learning and generative AImodels. When using an RTX GPU, these results can be generated faster than processing the AImodel on a CPU or NPU. Source: Jan.ai
Code generation AImodels (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. These models may inadvertently introduce insecure code, which could be exploited in cyberattacks. If you like our work, you will love our newsletter.
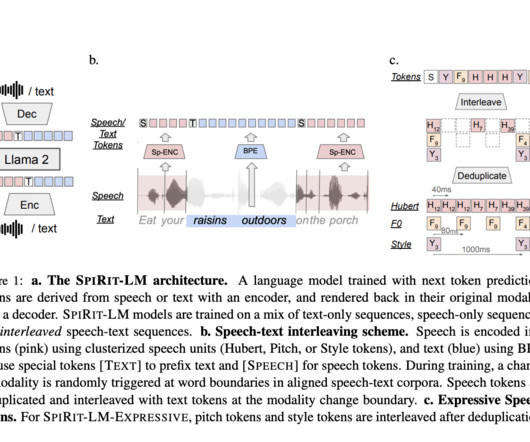
The model is capable of few-shot learning for tasks across modalities, such as automatic speech recognition (ASR), text-to-speech (TTS), and speech classification. This versatility positions Meta Spirit LM as a significant improvement over traditional multimodal AImodels that typically operate in isolated domains.
The impressive multimodal abilities and interactive experience of new AImodels like GPT-4o highlight its critical role in practical applications, yet it needs a high-performing open-source counterpart. Finally, the “ Omni-Alignment ” stage combines image, video, and audio data for comprehensive multimodal learning.
The ChatGPT Windows app delivers a native desktop experience for users, designed to improve interaction with the AImodel. With the release of this dedicated app, OpenAI aims to extend the reach and convenience of its conversational AI. If you like our work, you will love our newsletter.
This allows the bots to inspect areas of products that fixed cameras simply can’t access, as well as use AI at the edge to instantly detect defects. NVIDIA RTX GPUs power up their AI performance.” These perfectly labeled images are used to train the AImodels in the cloud and dramatically enhance their performance.
Watch CoRover’s session live at the AI Summit or on demand, and learn more about Indian businesses building multilingual language models with NeMo. VideoVerse uses NVIDIA CUDA libraries to accelerate AImodels for image and video understanding, automatic speech recognition and natural language understanding.
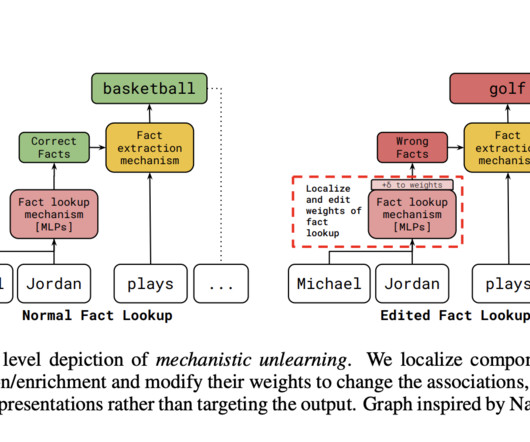
Mechanistic Unlearning is a new AI method that uses mechanistic interpretability to localize and edit specific model components associated with factual recall mechanisms. The study examines methods for removing information from AImodels and finds that many fail when prompts or outputs shift.
Generative artificial intelligence (AI) models are designed to create realistic, high-quality data, such as images, audio, and video, based on patterns in large datasets. These models can imitate complex data distributions, producing synthetic content resembling samples. If you like our work, you will love our newsletter.
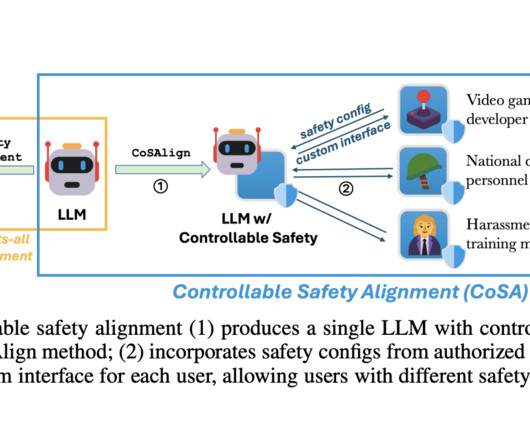
This allows the model to adapt its safety settings during use without retraining, and users can access the customized model through special interfaces, like specific API endpoints. The CoSA project aims to develop AImodels that can meet specific safety requirements, especially for content related to video game development.
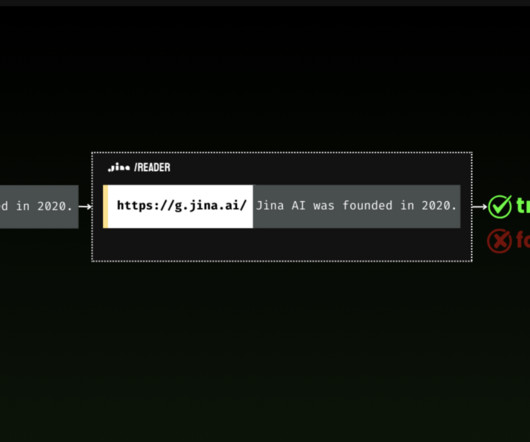
Jina AI announced the release of their latest product, g.jina.ai , designed to tackle the growing problem of misinformation and hallucination in generative AImodels. This innovative tool is part of their larger suite of applications to improve factual accuracy and grounding in AI-generated and human-written content.
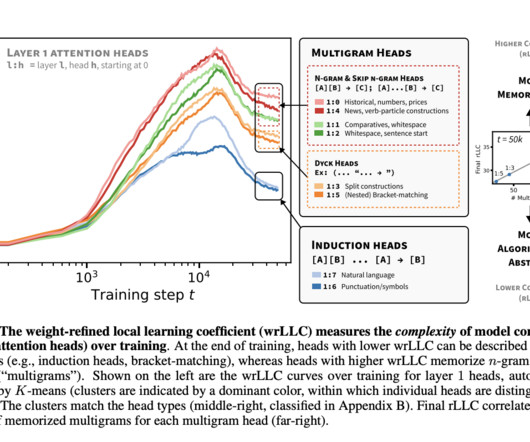
By allowing the model to focus on the most relevant parts of the data, transformers can perform complex tasks that require understanding and prediction across various domains. One major issue in AImodel development is understanding how internal components, such as attention heads in transformers, evolve and specialize during training.
They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants. gemma.cpp is a lightweight, standalone C++ inferenceengine for the Gemma foundation models from Google. The Open-Sora Plan project ‘s aim is to reproduce OpenAI’s Sora.
It uses formal languages, like first-order logic, to represent knowledge and an inferenceengine to draw logical conclusions based on user queries. Symbolic AI Mechanism. This ability to trace outputs to the rules and knowledge within the program makes the symbolic AImodel highly interpretable and explainable.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AImodels for inference. 70B model showed significant and consistent improvements in end-to-end (E2E) scaling times. cu124 Model Llama 3.1
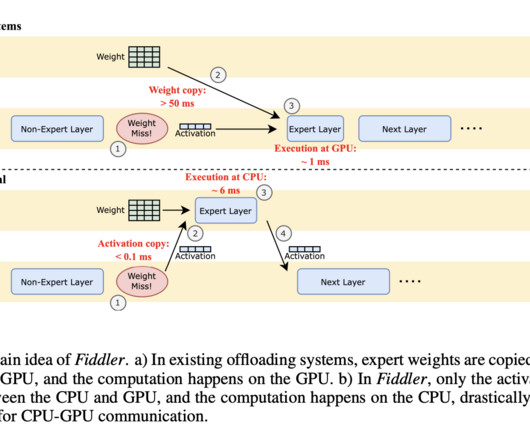
This methodology drastically cuts down the latency for CPU-GPU communication, enabling the system to run large MoE models, such as the Mixtral-8x7B with over 90GB of parameters, efficiently on a single GPU with limited memory. Fiddler’s design showcases a significant technical innovation in AImodel deployment.
You can reattach to your Docker container and stop the online inference server with the following: docker attach $(docker ps --format "{{.ID}}") Create a file for using the offline inferenceengine: cat > offline_inference.py <<EOF from vllm.entrypoints.llm import LLM from vllm.sampling_params import SamplingParams # Sample prompts.
By doing so, Meta AI aims to enhance the performance of large models while reducing the computational resources needed for deployment. This makes it feasible for both researchers and businesses to utilize powerful AImodels without needing specialized, costly infrastructure, thereby democratizing access to cutting-edge AI technologies.
Current generative AImodels face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Don’t Forget to join our 50k+ ML SubReddit.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content