This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Pras Velagapudi, CTO at Agility, comments: Datascarcity and variability are key challenges to successful learning in robot environments. Empowering developers with AImodels NVIDIA also unveiled new AI foundation models for RTX PCs, which aim to supercharge content creation, productivity, and enterprise applications.
This is the enticing promise of “zero-shot” capabilities in AI. Major tech companies have released impressive multimodal AImodels like CLIP for vision-language tasks and DALL-E for text-to-image generation. But how close are we to realizing this vision? If you like our work, you will love our newsletter.
Image by author #3 Generate: Use of LLMs to generate sample data GenAI can also generate synthetic data to train AImodels. Large Language Models (LLMs) can produce realistic sample data, helping address datascarcity in fields where data availability is limited.
A key feature of generative AI is to facilitate building AI applications without much labelled training data. This feature is particularly beneficial in fields like agriculture, where acquiring labeled training data can be challenging and costly.
The rapid growth of artificial intelligence (AI) has created an immense demand for data. Traditionally, organizations have relied on real-world datasuch as images, text, and audioto train AImodels. Consequently, it's becoming increasingly difficult to differentiate between original and AI-generated content.
.” Despite some research exploring the benefits and drawbacks of multilingual training and efforts to enhance models for smaller languages, most cutting-edge models still need to be primarily trained in large languages like English. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices. Introduction to Synthetic Data Generation with LLMs Synthetic data generation using LLMs involves leveraging these advanced AImodels to create artificial datasets that mimic real-world data.
With its extensive language training and romanization technique, the MMS Zero-shot method offers a promising solution to the datascarcity challenge, advancing the field towards more inclusive and universal speech recognition systems.
In the rapidly evolving landscape of artificial intelligence (AI), the quest for large, diverse, and high-quality datasets represents a significant hurdle. For instance, in domains where authentic data is rare or sensitive, synthetic data emerges as a scalable and customizable alternative. Yet synthetic data has its challenges.
The principle behind this is straightforward: better data results in better models. Much like a solid foundation is essential for a structure's stability, an AImodel's effectiveness is fundamentally linked to the quality of the data it is built upon. Datascarcity is another significant issue.
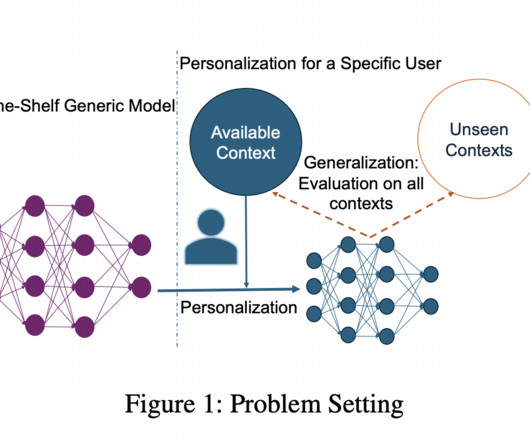
These applications can significantly impact health management by monitoring human behavior and providing critical data for health assessments. However, due to the variability in individual behaviors, environmental factors, and the physical placement of devices, the performance of generic AImodels is often hindered.
Consequently, many languages still need to be represented, limiting AI technologies’ applicability and fairness. Addressing this disparity requires innovative approaches to enhance the quality and diversity of multilingual datasets, ensuring that AImodels can perform effectively across a broad spectrum of languages.
Using GANs to generate high-quality synthetic data, Distilabel addresses key issues such as datascarcity, bias, and privacy concerns. This framework can enhance the development of AImodels by offering diverse, representative datasets, ultimately improving model performance and reliability across different domains.
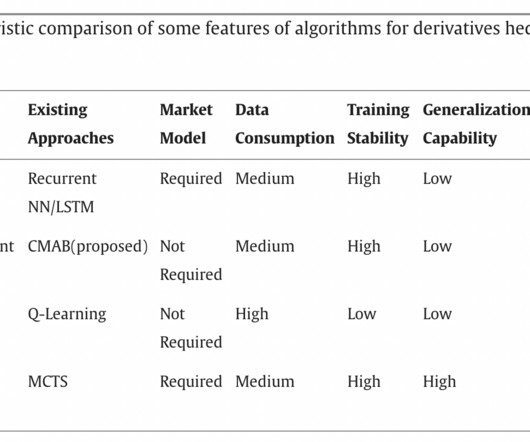
He highlighted the necessity for effective data use by stressing the significant amount of data many AI systems consume. Another researcher highlighted the challenge of considering AImodel-free due to market datascarcity for training, particularly in realistic derivative markets.
This essay explores the thesis of the "end of data" for AImodels, examining both sides of the argument and delving into potential solutions such as extracting higher quality data and generating synthetic datasets.
In August – Meta released a tool for AI-generated audio named AudioCraft and open-sourced all of its underlying models, including MusicGen. Last week – StabilityAI launched StableAudio , a subscription-based platform for creating music with AImodels.
Designing an AImodel to solve these problems became the challenge of Trinh’s PhD, which he undertook under the advisement of CDS Assistant Professor of Computer Science & Data Science He He.
The findings indicate that alleged emergent abilities might evaporate under different metrics or more robust statistical methods, suggesting that such abilities may not be fundamental properties of scaling AImodels. The paper also explores alternative strategies to mitigate datascarcity.
Instead of training separate models for each task, we can train a single model for multiple tasks, leading to significant time, memory, and energy savings. Handling of DataScarcity and Label Noise Multi-task learning also excels in handling datascarcity and label noise, two common challenges in Machine Learning.
This blog explores the innovations in AI driven by SLMs, their applications, advantages, challenges, and future potential. What Are Small Language Models (SLMs)? Small Language Models (SLMs) are a subset of AImodels specifically tailored for Natural Language Processing (NLP) tasks.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns.
Transfer Learning is a technique in Machine Learning where a model is pre-trained on a large and general task. Since this technology operates in transferring weights from AImodels, it eventually makes the training process for newer models faster and easier.
Dealing with limited target data – In some cases, there is limited real-world data available for the target task. Model customization uses the pre-trained weights learned on larger datasets to overcome this datascarcity. You can potentially implement RAG with a customized model.
This breakthrough enabled the generation of data and images that have since played a crucial role in training medical professionals and developing diagnostic tools while maintaining patient privacy. They simulate trials predict responses and generate synthetic biological data to accelerate research while ensuring safety and effectiveness.
In an increasingly interconnected and diverse world where communication transcends language barriers, the ability to communicate effectively with AImodels in different languages is a vital tool. It is a vital procedure that ensures AImodels can respond accurately and sensitively in various linguistic circumstances.
Edge Computing: With the growth in data volume, processing visual data at the edge has become a crucial concept for the adoption of computer vision. Edge AI involves processing data near the source. Therefore, edge devices like servers or computers are connected to cameras and run AImodels in real-time applications.
This breakthrough enabled the generation of data and images that have since played a crucial role in training medical professionals and developing diagnostic tools while maintaining patient privacy. They simulate trials predict responses and generate synthetic biological data to accelerate research while ensuring safety and effectiveness.
Types of N-Shot Learnings Unlike supervised learning, N-shot learning works to overcome the challenge of training deep learning and computer vision models with limited labeled data. For instance, recent research from Carnegie Mellon developed a framework to use audio and text to learn about visual data.
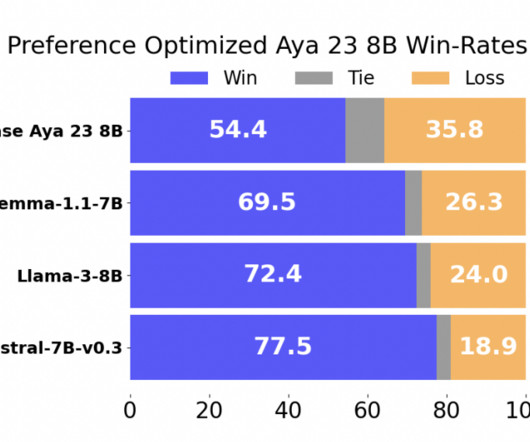
For offline use, Mistral AI'smodel boasts superior performance on coding tasks compared to Llama models, presenting an optimal choice for local LLM deployment, particularly for users with specific performance and hardware resource considerations.
Real-Time and Offline Processing : Our dual-track system supports low-latency real-time writes and high-throughput offline imports, ensuring data freshness. Embedded AIModels : By integrating multimodal embedding and ranking models, weve lowered the barrier to implementing complex search applications.
The NVIDIA Nemotron family, available as NVIDIA NIM microservices, offers a cutting-edge suite of language models now available through Amazon Bedrock Marketplace, marking a significant milestone in AImodel accessibility and deployment.
Gretel has made a remarkable contribution to the field of AI by launching the most extensive and diverse open-source Text-to-SQL dataset. This move will significantly accelerate the training of AImodels and will enhance the quality of data-driven insights across various industries.
Generative AI Generative AI is gaining traction in Data Science for its ability to create synthetic datasets that can be used for training Machine Learning models. This technology helps overcome challenges related to datascarcity and bias by generating realistic data that mimics real-world scenarios.
It addresses issues in traditional end-to-end models, like datascarcity and lack of melody control, by separating lyric-to-template and template-to-melody processes. This approach enables high-quality, controllable melody generation with minimal lyric-melody paired data.
Despite progress in applying AI to mathematics, significant challenges remain in addressing complex, abstract problems. Many AImodels excel in solving high school-level mathematical problems but struggle with advanced tasks such as theorem proving and abstract logical deductions.
Overcoming datascarcity with translation and synthetic data generation When fine-tuning a custom version of the Mistral 7B LLM for the Italian language, Fastweb faced a major obstacle: high-quality Italian datasets were extremely limited or unavailable.
What is Generative AI? Generative AI refers to a subset of Artificial Intelligence that focuses on creating new content or data based on existing datasets. Unlike traditional AImodels that primarily analyze and interpret data, GenAI generates new outputs, such as text, images, audio, and even synthetic datasets.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content