This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is critical for AImodels to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. When using the FAISS adapter (vector search), translation unit groupings are parsed and turned into vectors using the selected embedding model from Amazon Bedrock.
At the same time, our generative AImodels automatically design molecules targeting improvement across numerous properties, searching millions of candidates, and requiring enormous throughput and medium latency. The generated data points are automatically processed and used to fine-tune our AImodels every week.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 In this post, we share how Rad AI reduced real-time inference latency by 50% using Amazon SageMaker. 3 seconds, with minimal latency.
One of the significant challenges in AI processing is the efficient utilization of hardware resources such as GPUs. To tackle this challenge, Forethought uses SageMaker multi-model endpoints (MMEs) to run multiple AImodels on a single inference endpoint and scale. 2xlarge instances. These particular instances offer 15.5
Effective and precise AImodels require training on extensive datasets. Enterprises seeking to harness the power of AI must establish a data pipeline that involves extracting data from diverse sources, transforming it into a consistent format and storing it efficiently.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the completemodel lineage with data/models/experiments used downstream?
Launch the instance using Neuron DLAMI Complete the following steps: On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. The way you craft a prompt can profoundly influence the nature and usefulness of the AI’s response.
Last, we’ll shuffle the dataset to ensure the model sees it in randomized order. It does this by freezing the model parameters, making sure all parts use the same type of data format, and using a special technique called gradient checkpointing if the model can handle it. If your results are not good, you can try lower values.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Others, toward language completion and further downstream tasks. Very large core pie, and very efficient in certain sets of things. Let’s take a look at what the breakdown is.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Others, toward language completion and further downstream tasks. Very large core pie, and very efficient in certain sets of things. Let’s take a look at what the breakdown is.
NVIDIA NeMo Framework NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generative AImodels with billions and trillions of parameters at scale. NVIDIA NeMo simplifies generative AImodel development, making it more cost-effective and efficient for enterprises.
Generative AImodels are revolutionizing music creation and consumption. MusicGen code is released under MIT, model weights are released under CC-BY-NC 4.0. The following diagram shows how MusicGen, a single stage auto-regressive Transformer model, can generate high-quality music based on text descriptions or audio prompts.
They proceed to verify the accuracy of the generated answer by selecting the buttons, which auto play the source video starting at that timestamp. The knowledge base sync process handles chunking and embedding of the transcript, and storing embedding vectors and file metadata in an Amazon OpenSearch Serverless vector database.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. Amazon Bedrock is a fully managed service that grants access to high-performance foundation models (FMs) from top AI companies through a unified API.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


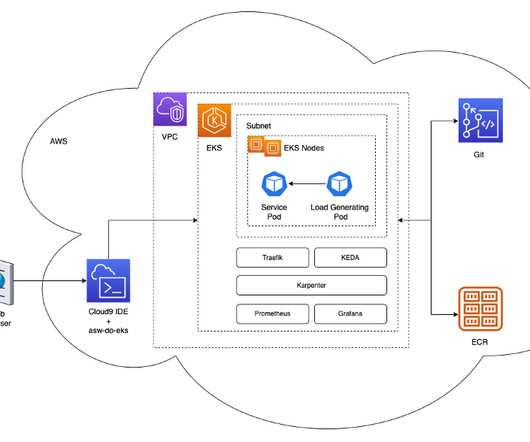











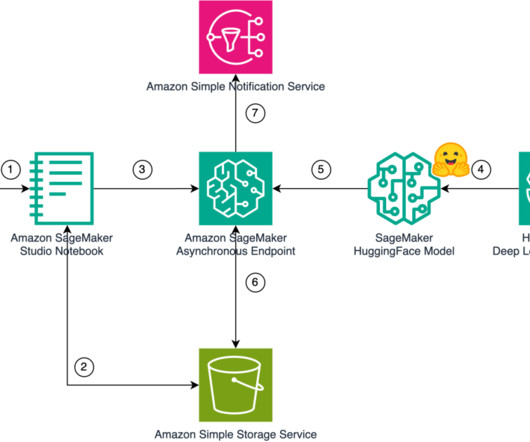








Let's personalize your content