This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
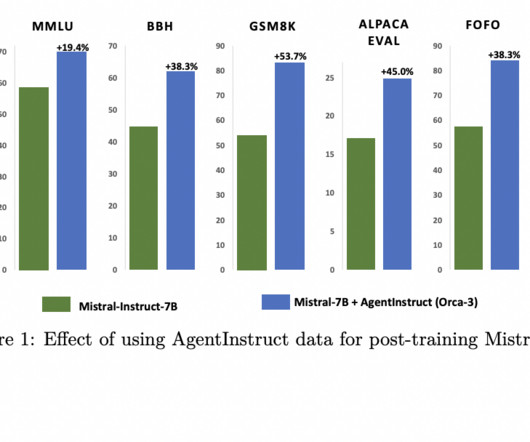
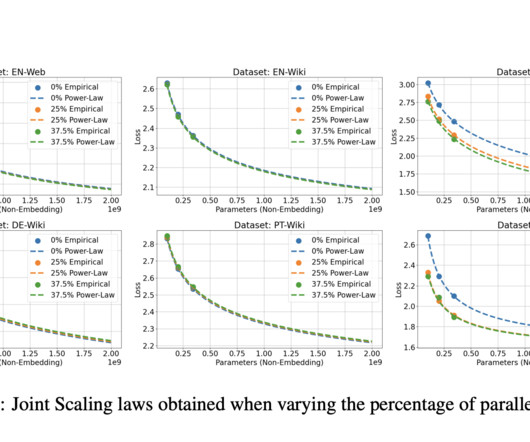
Training AI models with subpar data can lead to biased responses and undesirable outcomes. When unstructured data surfaces during AIdevelopment, the DevOps process plays a crucial role in data cleansing, ultimately enhancing the overall model quality. Poor data can distort AI responses.
The rapid advancement in AI technology has heightened the demand for high-quality training data, which is essential for effectively functioning and improving these models. One of the significant challenges in AIdevelopment is ensuring that the synthetic data used to train these models is diverse and of high quality.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
AIDeveloper / Software engineers: Provide user-interface, front-end application and scalability support. Organizations in which AIdevelopers or software engineers are involved in the stage of developingAI use cases are much more likely to reach mature levels of AI implementation.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. It consists of three main components: Data config Specifies the dataset location and its structure.
This calls for the organization to also make important decisions regarding data, talent and technology: A well-crafted strategy will provide a clear plan for managing, analyzing and leveraging data for AI initiatives. Research AI use cases to know where and how these technologies are being applied in relevant industries.
The retrieval component uses Amazon Kendra as the intelligent search service, offering natural language processing (NLP) capabilities, machine learning (ML) powered relevance ranking, and support for multiple data sources and formats. Focus should be placed on dataquality through robust validation and consistent formatting.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Addressing this challenge requires a solution that is scalable, versatile, and accessible to a wide range of users, from individual researchers to large teams working on the state-of-the-art side of AIdevelopment. Existing research emphasizes the significance of distributed processing and dataquality control for enhancing LLMs.
That said, Ive noticed a growing disconnect between cutting-edge AIdevelopment and the realities of AI application developers. It has already inspired me to set new goals for 2025, and I hope it can do the same for other ML engineers. AI Revolution is Losing Steam? Take, for example, the U.S.
Whether youre new to AIdevelopment or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AIdevelopment.
We also need better ways to evaluate dataquality and ensure efficient interaction between data selection and annotation. It has the potential to revolutionize AIdevelopment, making it faster, cheaper, and more accessible. In Conclusion, DAL is a game-changer for AIdevelopment.
There are major growth opportunities in both the model builders and companies looking to adopt generative AI into their products and operations. We feel we are just at the beginning of the largest AI wave. Dataquality plays a crucial role in AI model development.
Models are trained on these data pools, enabling in-depth analysis of OP effectiveness and its correlation with model performance across various quantitative and qualitative indicators. In their methodology, the researchers implemented a hierarchical data pyramid, categorizing data pools based on their ranked model metric scores.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to developAI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
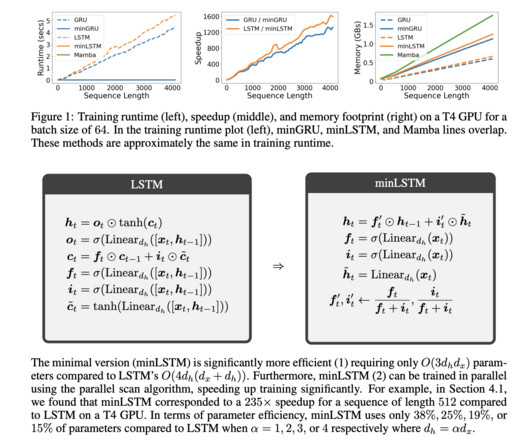
indicating strong results across varying levels of dataquality. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AIdevelopers and researchers? while the minGRU scored 79.4, If you like our work, you will love our newsletter.
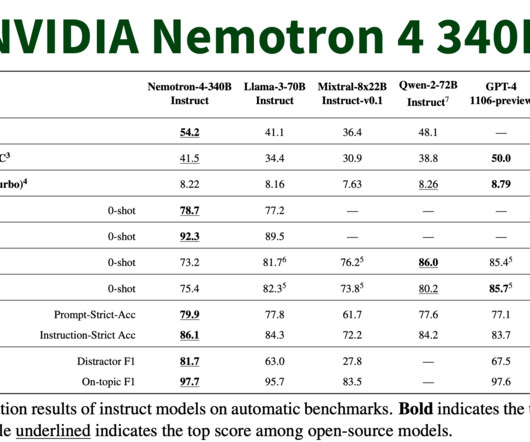
The Nemotron-4 340B Instruct model is particularly noteworthy as it generates synthetic data that closely mimics real-world data, improving the dataquality and enhancing the performance of custom LLMs across diverse domains. Also, don’t forget to follow us on Twitter. Join our Telegram Channel and LinkedIn Gr oup.
However, challenges such as false positives, dataquality, and limited treatment options prompted the integration of AI and IoMT technologies. These technologies enhance early detection and personalized care but face obstacles like data privacy, device reliability, and model generalizability. Let’s collaborate!
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio.
People with AI skills have always been hard to find and are often expensive. While experienced AIdevelopers are starting to leave powerhouses like Google, OpenAI, Meta, and Microsoft, not enough are leaving to meet demand—and most of them will probably gravitate to startups rather than adding to the AI talent within established companies.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio.
Google emphasizes its commitment to responsible AIdevelopment, highlighting safety and security as key priorities in building these agentic experiences. Command R7B: Command R7B, developed by Cohere, is the smallest model in their R series, focusing on speed, efficiency, and quality for building AI applications.
Databricks customers can now access millions of rows of data seamlessly within the Snorkel Flow platform thanks to a new Databricks connector. Weeks later, on June 29, Snorkel AI Founding Engineer and Product Director Vincent Chen will present at “ Building AI-Powered Products with Foundation Models ” at the Databricks Data + AI Summit.
Databricks customers can now access millions of rows of data seamlessly within the Snorkel Flow platform thanks to a new Databricks connector. Weeks later, on June 29, Snorkel AI Founding Engineer and Product Director Vincent Chen will present at “ Building AI-Powered Products with Foundation Models ” at the Databricks Data + AI Summit.
New and developing technologies like artificial intelligence (AI) and machine learning (ML) are vital in improving industries and daily life worldwide. However, bad actors always look for ways to twist these emerging technologies into something more sinister, making data poisoning a serious issue that you should be prepared for.
Conclusion and Future Work The EuroLLM project has successfully developed multilingual language models that support all European Union languages, addressing the need for inclusive LLMs beyond English. Check out the Paper and Model on HF. All credit for this research goes to the researchers of this project. Let’s collaborate! and EuroLLM-1.7B-Instruct)
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AIdevelopment. It includes Python and a vast collection of pre-installed libraries and tools for AIdevelopment.
It went from simple rule-based systems to advanced data-driven algorithms. Today, real-time trading choices are made by AI using the combined power of big data, machine learning (ML), and predictive analytics. Evolution of AI in Financial Markets Historically, traders depended on previous outcomes and their instincts.
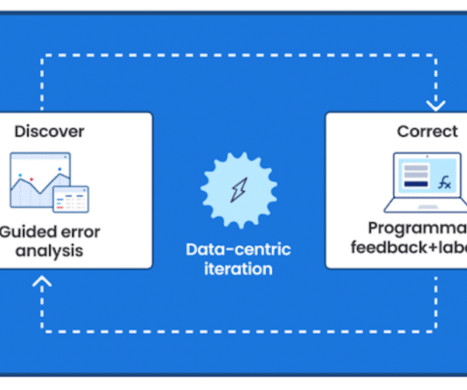
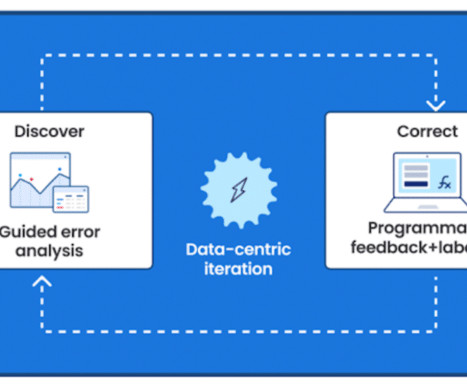
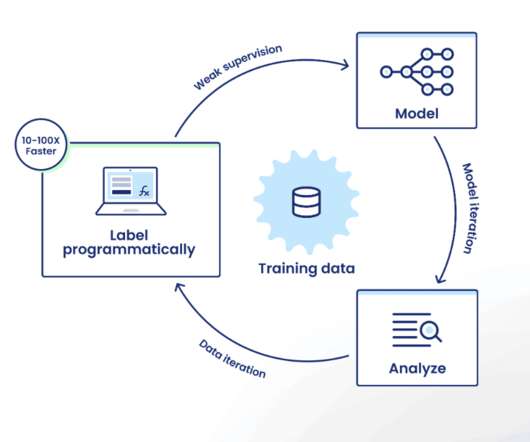
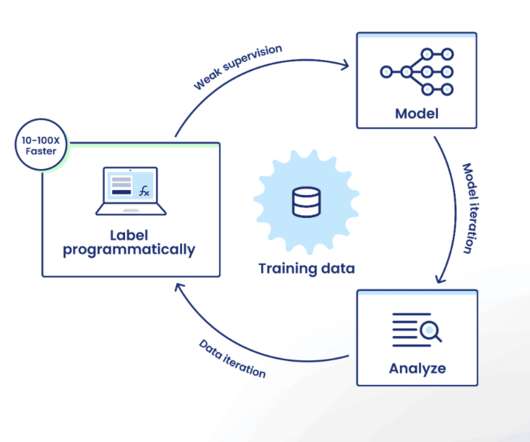
We plan for multiple rounds of iteration to improve performance through error analysis, and the Snorkel Flow platform provides tools to enable this kind of iteration within the data-centric AI framework. Traditional, model-centric AIdevelopment focuses its iteration loop on the model itself.
We plan for multiple rounds of iteration to improve performance through error analysis, and the Snorkel Flow platform provides tools to enable this kind of iteration within the data-centric AI framework. Traditional, model-centric AIdevelopment focuses its iteration loop on the model itself.
AI and machine learning (ML) technologies enable businesses to analyze unstructured data. AI and ML technologies work cohesively with data analytics and business intelligence (BI) tools. By adopting responsible AI, companies can positively impact the customer. There is much to explore and unfold.
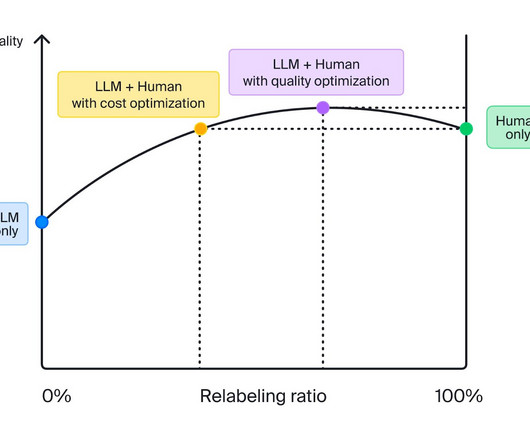
Based on our experience using LLMs on real-world text annotation projects, even the latest state-of-the-art models aren’t meeting quality expectations. What’s more, these models aren’t always cheaper than data labeling with human annotators. Toloka can help you in every stage of the AIdevelopment process.
Access to synthetic data is valuable for developing effective artificial intelligence (AI) and machine learning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
I’m excited today to be talking about DataPerf, which is about building benchmarks for data-centric AIdevelopment. Why are benchmarks critical for accelerating development in any particular space? These kinds of benchmarks have played a very critical role in accelerating the space, especially in ML.
I’m excited today to be talking about DataPerf, which is about building benchmarks for data-centric AIdevelopment. Why are benchmarks critical for accelerating development in any particular space? These kinds of benchmarks have played a very critical role in accelerating the space, especially in ML.
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. So all of this points to the pain or pessimistic bottleneck “takes” around data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content