This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They must demonstrate tangible ROI from AI investments while navigating challenges around dataquality and regulatory uncertainty. Its already the perfect storm, with 89% of large businesses in the EU reporting conflicting expectations for their generative AI initiatives. For businesses, the pressure in 2025 is twofold.
Humans can validate automated decisions by, for example, interpreting the reasoning behind a flagged transaction, making it explainable and defensible to regulators. Financial institutions are also under increasing pressure to use ExplainableAI (XAI) tools to make AI-driven decisions understandable to regulators and auditors.
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. Why is this the case?
But, while this abundance of data is driving innovation, the dominance of uniform datasetsoften referred to as data monoculturesposes significant risks to diversity and creativity in AIdevelopment. In AI, relying on uniform datasets creates rigid, biased, and often unreliable models.
. “Our AI engineers built a prompt evaluation pipeline that seamlessly considers cost, processing time, semantic similarity, and the likelihood of hallucinations,” Ros explained. It’s obviously an ambitious goal, but it’s important to our employees and it’s important to our clients,” explained Ros.
If you are excited to dive into applied AI, want a study partner, or even want to find a partner for your passion project, join the collaboration channel! Golden_leaves68731 is a senior AIdeveloper looking for a non-technical co-founder to join their venture. If this sounds like you, reach out in the thread!
It integrates smoothly with other products for a more comprehensive AIdevelopment environment. This helps developers to understand and fix the root cause. Key features of Cleanlab include: Cleanlab's AI algorithms can automatically identify label errors, outliers, and near-duplicates. Enhances dataquality.
Risk and limitations of AI The risk associated with the adoption of AI in insurance can be separated broadly into two categories—technological and usage. Technological risk—data confidentiality The chief technological risk is the matter of data confidentiality.
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AIdevelopment.
Additionally, we discuss some of the responsible AI framework that customers should consider adopting as trust and responsible AI implementation remain crucial for successful AI adoption. But first, we explain technical architecture that makes Alfred such a powerful tool for Andurils workforce.
Author(s): Richie Bachala Originally published on Towards AI. Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models.
Dataquality dependency: Success depends heavily on having high-quality preference data. When choosing an alignment method, organizations must weigh trade-offs like complexity, computational cost, and dataquality requirements. Learn how to get more value from your PDF documents! Sign up here!
Josh Wong is the Founder and CEO of ThinkLabs AI. ThinkLabs AI is a specialized AIdevelopment and deployment company. Its mission is to empower critical industries and infrastructure with trustworthy AI aimed at achieving global energy sustainability. Josh Wong attended the University of Waterloo.
However, the AI community has also been making a lot of progress in developing capable, smaller, and cheaper models. This can come from algorithmic improvements and more focus on pretraining dataquality, such as the new open-source DBRX model from Databricks. Why should you care?
Image Source : LG AI Research Blog ([link] Responsible AIDevelopment: Ethical and Transparent Practices The development of EXAONE 3.5 models adhered to LG AI Research s Responsible AIDevelopment Framework, prioritizing data governance, ethical considerations, and risk management.
However, challenges such as false positives, dataquality, and limited treatment options prompted the integration of AI and IoMT technologies. These technologies enhance early detection and personalized care but face obstacles like data privacy, device reliability, and model generalizability. Check out the Paper.
The integration between the Snorkel Flow AIdatadevelopment platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Heres what that looks like in practice. Sign up here!
Dataquality dependency: Success depends heavily on having high-quality preference data. When choosing an alignment method, organizations must weigh trade-offs like complexity, computational cost, and dataquality requirements. Learn how to get more value from your PDF documents! Sign up here!
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
With the global AI market exceeding $184 billion in 2024a $50 billion leap from 2023its clear that AI adoption is accelerating. This blog aims to help you navigate this growth by addressing key enablers of AIdevelopment. Key Takeaways Reliable, diverse, and preprocessed data is critical for accurate AI model training.
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
Snorkel AI provides a data-centric AIdevelopment platform for AI teams to unlock production-grade model quality and accelerate time-to-value for their investments. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
Snorkel AI provides a data-centric AIdevelopment platform for AI teams to unlock production-grade model quality and accelerate time-to-value for their investments. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
People with AI skills have always been hard to find and are often expensive. While experienced AIdevelopers are starting to leave powerhouses like Google, OpenAI, Meta, and Microsoft, not enough are leaving to meet demand—and most of them will probably gravitate to startups rather than adding to the AI talent within established companies.
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
What is AI Engineering? Chip Huyen began by explaining how AI engineering has emerged as a distinct discipline, evolving out of traditional machine learning engineering. While machine learning engineers focus on building models, AI engineers often work with pre-trained foundation models, adapting them to specific use cases.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
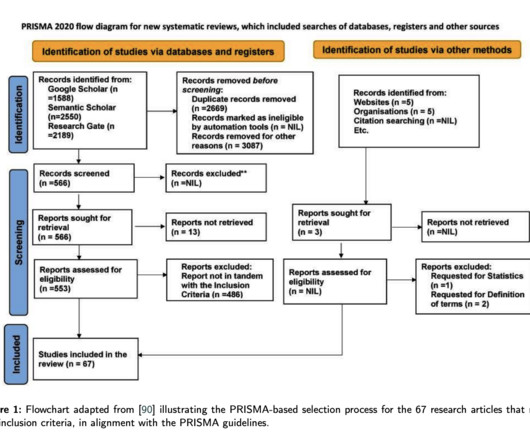
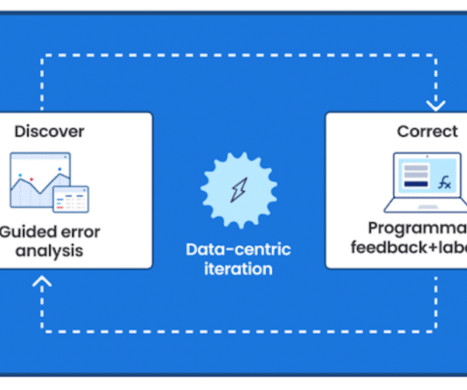
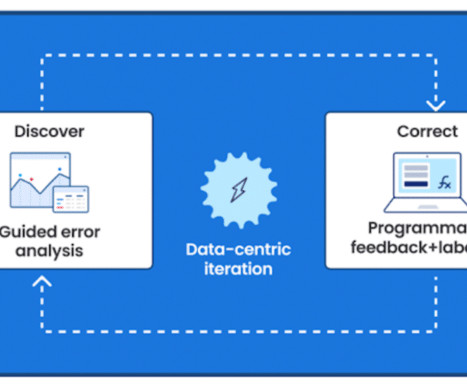
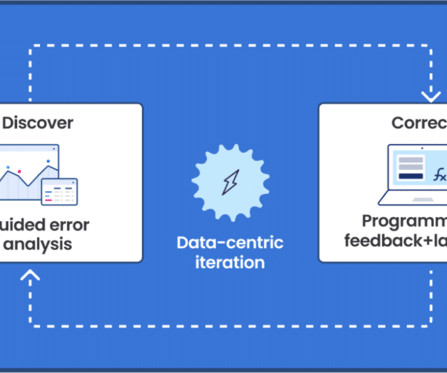
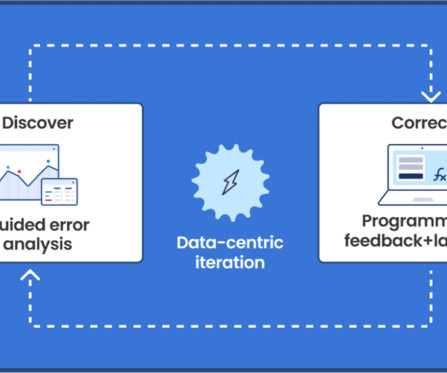
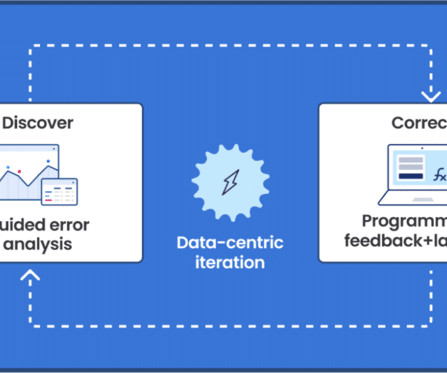
Users are able to rapidly improve training dataquality and model performance using integrated error analysis and model-guided feedback to develop highly accurate and adaptable AI applications. Oil companies generate massive volumes of unstructured data in daily drilling reports, well maintenance logs, and other files.
Users are able to rapidly improve training dataquality and model performance using integrated error analysis and model-guided feedback to develop highly accurate and adaptable AI applications. Oil companies generate massive volumes of unstructured data in daily drilling reports, well maintenance logs, and other files.
Instead of applying uniform regulations, it categorizes AI systems based on their potential risk to society and applies rules accordingly. This tiered approach encourages responsible AIdevelopment while ensuring appropriate safeguards are in place. Also, be transparent about the data these systems use.
Alex Ratner, CEO and co-founder of Snorkel AI, presented a high-level introduction to data-centric AI at Snorkel’s Future of Data-Centric AI virtual conference in 2022. From there, the key part, of course, is iterating as quickly as possible.
Alex Ratner, CEO and co-founder of Snorkel AI, presented a high-level introduction to data-centric AI at Snorkel’s Future of Data-Centric AI virtual conference in 2022. From there, the key part, of course, is iterating as quickly as possible.
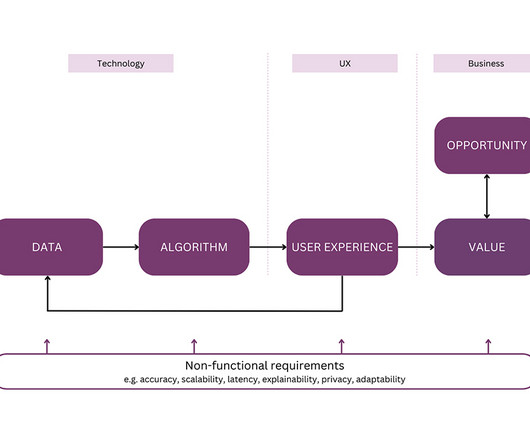
While each of them offers exciting perspectives for research, a real-life product needs to combine the data, the model, and the human-machine interaction into a coherent system. AIdevelopment is a highly collaborative enterprise. Well, in AI products, you can pause this fight and use both to your advantage.
This allows for: Developing Robust and Generalizable AI Models. Training AI models on synthetic data exposes them to a wider range of variations and edge cases. Rapid AIDevelopment. Using generative models for synthetic data can be much faster and cheaper than collecting real-world data.
With content summarization, we can describe scenes, explain text, and give sentiment analysis. Let’s see how these technologies can be used within AI solutions for the blind. First, accuracy should be the top priority, this means better data and model training or fine-tuning.
Llama 2 isn't just another statistical model trained on terabytes of data; it's an embodiment of a philosophy. One that stresses an open-source approach as the backbone of AIdevelopment, particularly in the generative AI space. Dataquality and diversity are just as pivotal as volume in these scenarios.
Businesses face fines and reputational damage when AI decisions are deemed unethical or discriminatory. Socially, biased AI systems amplify inequalities, while data breaches erode trust in technology and institutions. Broader Ethical Implications Ethical AIdevelopment transcends individual failures.
From the outset, AWS has prioritized responsible AI innovation and developed rigorous methodologies to build and operate our AI services with consideration for fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency.
AIDevelopment Lifecycle: Learnings of What Changed with LLMs Noé Achache | Engineering Manager & Generative AI Lead | Sicara Using LLMs to build models and pipelines has made it incredibly easy to build proof of concepts, but much more challenging to evaluate the models. billion customer interactions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content