This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Consequently, the foundational design of AI systems often fails to include the diversity of global cultures and languages, leaving vast regions underrepresented. Bias in AI typically can be categorized into algorithmic bias and data-driven bias. A 2023 McKinsey report estimated that generative AI could contribute between $2.6
Founded out of Berlin in 2021, Qdrant is targeting AI software developers with an open source vector search engine and database for unstructured data, which is an integral part of AI application development particularly as it relates to using real-time data that hasn’t been categorized or labeled.
In 2023, the European Union demonstrated its commitment to elevating AI as a national priority by progressing toward the finalization of the European Union Artificial Intelligence Act (EU AI Act). This initiative reflects IBM’s commitment to AI safety and ethics, promoting open innovation in AIdevelopment.
This provision mandates that AIdevelopers and operators provide clear, understandable information about how their AI systems function, the logic behind their decisions, and the potential impacts these systems might have. This is aimed at demystifying AI operations and ensuring accountability.
Researchers evaluated anthropomorphic behaviors in AI systems using a multi-turn framework in which a User LLM interacted with a Target LLM across eight scenarios in four domains: friendship, life coaching, career development, and general planning. The results identified relationship-building behaviors that evolved with dialogue.
This extensive collection, categorized for specific purposes like narration or expressiveness, is a testament to the platform's versatility. Its voice cloning feature, in particular, represents a significant leap in AI voice technology.
Risk-Based Categorization of AI Technologies Central to the Act is its innovative risk-based framework, which categorizesAI systems into four distinct levels: unacceptable, high, medium, and low risk.
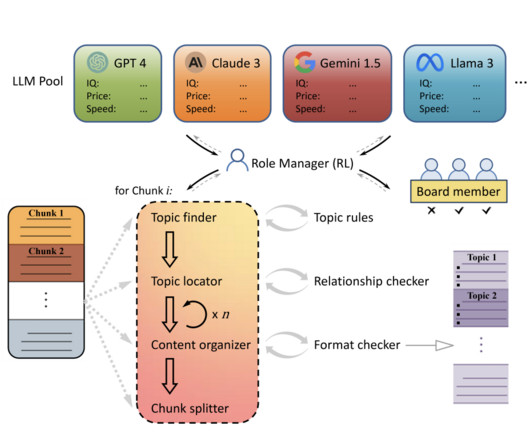
This study categorizes existing collaboration strategies, highlights their advantages, and proposes future directions for advancing modular multi-LLM systems. The study categorizes existing multi-LLM collaboration methods into a hierarchy based on information exchange levels, including API, text, logit, and weight-level collaboration.
The company is committed to ethical and responsible AIdevelopment with human oversight and transparency. Verisk is using generative AI to enhance operational efficiencies and profitability for insurance clients while adhering to its ethical AI principles. This analysis helps pinpoint specific areas that need improvement.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. values.tolist()) y_train = df_train['agent'].values.tolist()
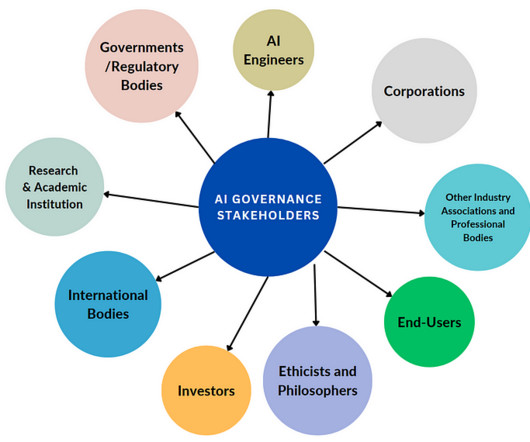
Our journey will progress into its application in AI, leading to the identification of pivotal stakeholders in AI Governance. In Part 2, we’ll delve deeper into analyzing, categorizing, and prioritizing stakeholders in AI Governance, and more. Without further ado, Let us embark on the first phase of this insightful guide.
Gemma's architecture leverages advanced neural network techniques, particularly the transformer architecture, a backbone of recent AIdevelopments. It also supports easy deployment options, including Vertex AI and Google Kubernetes Engine.
offers AIdevelopers hours of video call data, ready for your models, along with thousands of hours of other types of training data. Categorize Me This!” — Content Categorization: Are you looking for a more organized and efficient way to review and analyze the content from your online meetings?
The conference spotlighted exceptional work through its prestigious awards, broadly categorized into three distinct segments: Outstanding Main Track Papers, Outstanding Main Track Runner-Ups, and Outstanding Datasets and Benchmark Track Papers.
Session 2: Bayesian Analysis of Survey Data: Practical Modeling withPyMC Unlock the power of Bayesian inference for modeling complex categorical data using PyMC. This session takes you from logistic regression to categorical and ordered logistic regression, providing practical, hands-on experience with real-world surveydata.
Lawmakers behind SB 1047 argue that these regulations are necessary to ensure AI technologies are developed responsibly and transparently. One of the most controversial aspects of SB 1047 is the requirement for AIdevelopers to include a kill switch in their systems.
The European Union (EU) is the first major market to define new rules around AI. “The aim is to turn the EU into a global hub for trustworthy AI,” according to EU officials. The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety.
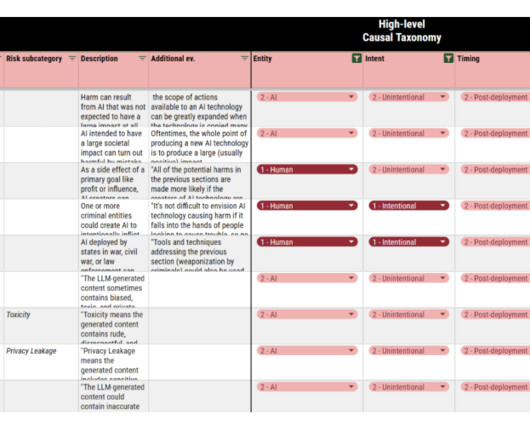
AI-related risks concern policymakers, researchers, and the general public. Although substantial research has identified and categorized these risks, a unified framework is needed to be consistent with terminology and clarity. This process led to the creating of an AI Risk Database containing 777 risks from 43 documents.
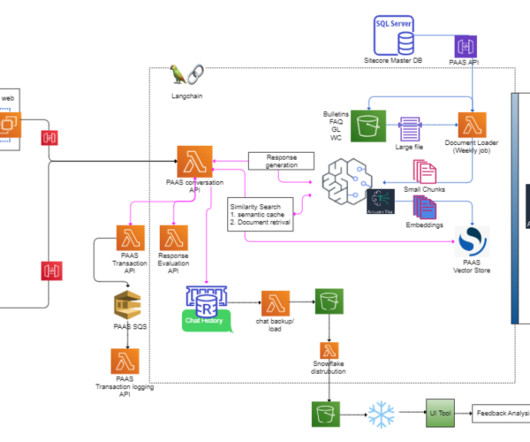
Machine learning (ML) and deep learning (DL) form the foundation of conversational AIdevelopment. HR and internal processes: Conversational AI applications streamline HR operations by addressing FAQs quickly, facilitating smooth and personalized employee onboarding, and enhancing employee training programs.
By allowing users to define tagging criteria and natural language descriptions, the tool can review and categorize large document sets in hours instead of days. Lawyers can set criteria and natural language descriptions for specific tags, and Cecilia will efficiently categorize documents based on these parameters.
OLP can assist in segmenting and categorizing streaming transcripts into relevant areas, such as product descriptions, pricing talks, or customer interactions, in live e-commerce. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AIdevelopers and researchers?
These enhancements enable the model to understand and categorize data better, making it more effective for various applications. Future updates and improvements are expected to push further the boundaries of what AI models can achieve. The practical applications of SFR-embedding-v2 are vast and varied.
At this point, AI is viewed as more than just a tool; it is a crucial component of company strategy and execution, able to manage intricate organizational duties. OpenAI offers a roadmap for the advancement of AIdevelopment by clearly defining the route from conversational AI to organizational management.
This library systematically categorizes songs, capturing key, tempo, chords, instrumentation, song structures, time signature, genre and more. Having absolute copyright ownership of the data, Rightsify offers indemnity to developers for employing the data in their models commercially. GCX provides datasets with over 4.4
Currently, this CNN is trained on a COCO dataset that categorizes around 80 objects. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AIdevelopers and researchers? If you like our work, you will love our newsletter. Let’s collaborate!
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
With expertise spanning technical AI knowledge, policy, and governance, the group aims to increase transparency and foster collective solutions to the challenges of AI safety evaluation. of the AI Safety Benchmark.
Most experts categorize it as a powerful, but narrow AI model. Current AI advancements demonstrate impressive capabilities in specific areas. The skills gap in gen AIdevelopment is a significant hurdle. Some, like Goertzel and Pennachin , suggest that AGI would possess self-understanding and self-control.
In their methodology, the researchers implemented a hierarchical data pyramid, categorizing data pools based on their ranked model metric scores. The sandbox’s compatibility with existing model-centric infrastructures makes it a versatile tool for AIdevelopment.
However, implementing ML can be a challenge for companies that lack resources such as ML practitioners, data scientists, or artificial intelligence (AI) developers. Then, we walk you through the process to train a text analysis model to categorize the reviews by product type. All without writing a single line of code.
Train and Test Sets for Model Development The synthetic-GSM8K-reflection-405B dataset is thoughtfully designed to support AI model development. These examples are categorized by difficulty levels: medium, hard, and very hard, ensuring that models trained on this dataset can handle a wide spectrum of reasoning challenges.
This issue can be categorized into two types: factual hallucination, where the generated output deviates from established knowledge, and faithfulness hallucination, where the generated response is inconsistent with the provided context. If you like our work, you will love our newsletter. Let’s collaborate!
Perhaps the most ambitious, closing section of the new work is the authors' adjuration that the research and development community aim to develop ‘appropriate' and ‘precise' terminology, to establish the parameters that would define an anthropomorphic AI system, and distinguish it from real-world human discourse.
Evaluated Models Ready Tensor’s benchmarking study categorized the 25 evaluated models into three main types: Machine Learning (ML) models, Neural Network models, and a special category called the Distance Profile model. The datasets, including HAR70 and PAMAP2, are aggregated versions sourced from the UCI Machine Learning Repository.
In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data. Instant + Customizable GraphRAG with Unstructured + AstraDB Nina Lopatina, PhD, Staff Developer Relations Engineer at Unstructured.io
Some components are categorized in groups based on the type of functionality they exhibit. Prompt chaining – Generative AIdevelopers often use prompt chaining techniques to break complex tasks into subtasks before sending them to an LLM. The standalone components are: The HTTPS endpoint is the entry point to the gateway.
Include summary statistics of the data, including counts of any discrete or categorical features and the target feature. Kilic, “ Data Science Terminology — AI / ML / DL,” Medium, Dec. Gulmez, “ How to Become an AIDeveloper,” Medium, Jan. Classify, predict, detect, translate, etc. Be willing to share the entire dataset.
It can be used for general text generation where the model needs to provide a response, question-answering tasks where the model must answer a specific question, text summarization tasks where the model needs to summarize a given text, or classification tasks where the model must categorize the provided text.
offers AIdevelopers hours of video call data, ready for your models, along with thousands of hours of other types of training data. Categorize Me This!” — Content Categorization: Are you looking for a more organized and efficient way to review and analyze the content from your online meetings?
Automated document analysis AI tools designed for law firms use advanced technologies like NLP and machine learning to analyze extensive legal documents swiftly. By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals.
Models were categorized into three groups: real-world use cases, long-context processing, and general domain tasks. Image Source : LG AI Research Blog ([link] Responsible AIDevelopment: Ethical and Transparent Practices The development of EXAONE 3.5 Benchmark Evaluations: Unparalleled Performance of EXAONE 3.5
The dataset is built through a three-step process: categorizing diverse tasks, augmenting them with CoT rationales, and applying rigorous self-filtering to enhance accuracy. Data is categorized into ten major types, facilitating task-specific enhancements. Check out the Paper.
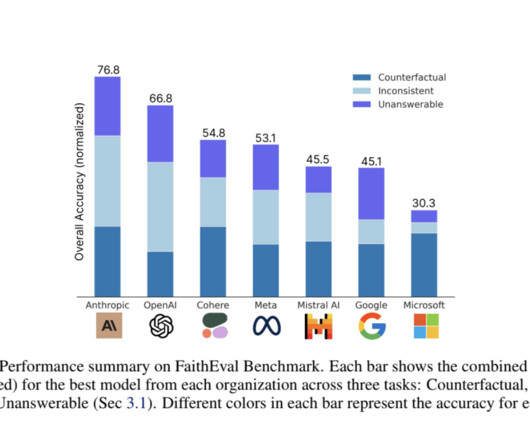
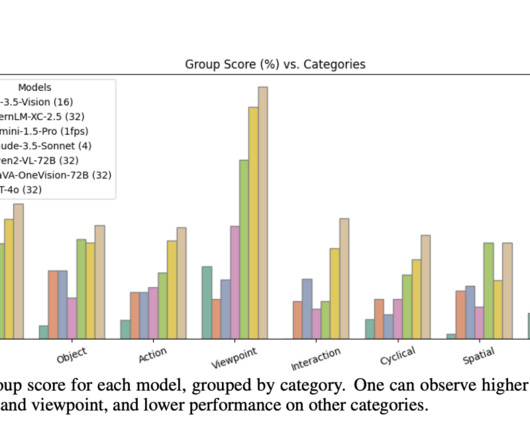
This data is categorized into three major categories: Object, Action, and Viewpoint. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AIdevelopers and researchers? Models are assessed against each of these categories. Let’s collaborate!
MLOps is the discipline that unites machine learning development with operational processes, ensuring that AI models are not only built effectively but also deployed and maintained in production environments with scalability in mind. Building Scalable Data Pipelines The foundation of any AI pipeline is the data it consumes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content