This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In tests like AIModeling Efficiency (AIME) and General Purpose Question Answering (GPQA), Grok-3 has consistently outperformed other AI systems. This ability is supported by advanced technical components like inferenceengines and knowledge graphs, which enhance its reasoning skills.
NVIDIA NIM microservices, part of the NVIDIA AI Enterprise software platform, together with Google Kubernetes Engine (GKE) provide a streamlined path for developingAI-powered apps and deploying optimized AImodels into production.
However, scaling AI across an organization takes work. It involves complex tasks like integrating AImodels into existing systems, ensuring scalability and performance, preserving data security and privacy, and managing the entire lifecycle of AImodels.
Imagine working with an AImodel that runs smoothly on one processor but struggles on another due to these differences. For developers and researchers, this means navigating complex problems to ensure their AI solutions are efficient and scalable on all types of hardware.
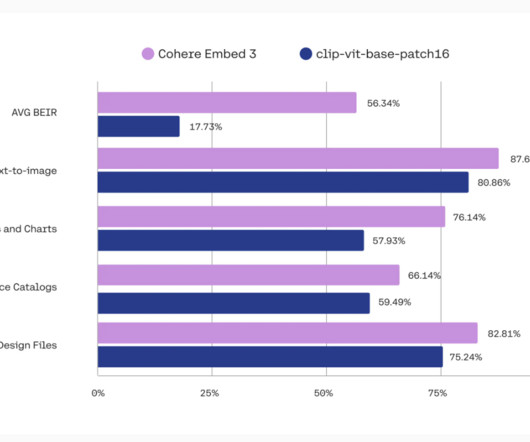
In an increasingly interconnected world, understanding and making sense of different types of information simultaneously is crucial for the next wave of AIdevelopment. Cohere has officially launched Multimodal Embed 3 , an AImodel designed to bring the power of language and visual data together to create a unified, rich embedding.
The Birth of Black Forest Labs Before we delve into the technical aspects of Flux, it's crucial to understand the pedigree behind this innovative model. Black Forest Labs is not just another AI startup; it's a powerhouse of talent with a track record of developing foundational generative AImodels.
These advanced models expand AI capabilities beyond text, allowing understanding and generation of content like images, audio, and video, signaling a significant leap in AIdevelopment. Finally, the “ Omni-Alignment ” stage combines image, video, and audio data for comprehensive multimodal learning.
Watch CoRover’s session live at the AI Summit or on demand, and learn more about Indian businesses building multilingual language models with NeMo. VideoVerse uses NVIDIA CUDA libraries to accelerate AImodels for image and video understanding, automatic speech recognition and natural language understanding.
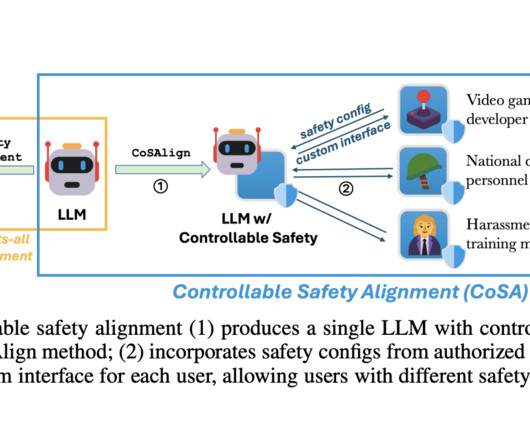
Some researchers highlighted that AI should have “normative competence,” meaning the ability to understand and adjust to diverse norms, promoting safety pluralism. The CoSA project aims to developAImodels that can meet specific safety requirements, especially for content related to video game development.
By doing so, Meta AI aims to enhance the performance of large models while reducing the computational resources needed for deployment. This makes it feasible for both researchers and businesses to utilize powerful AImodels without needing specialized, costly infrastructure, thereby democratizing access to cutting-edge AI technologies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content