This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
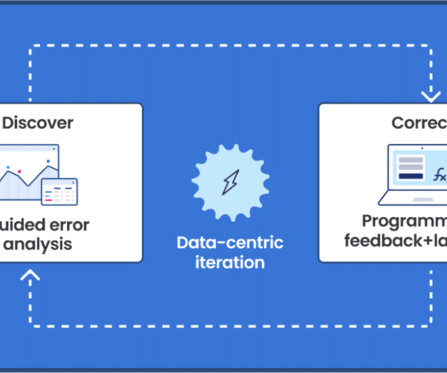
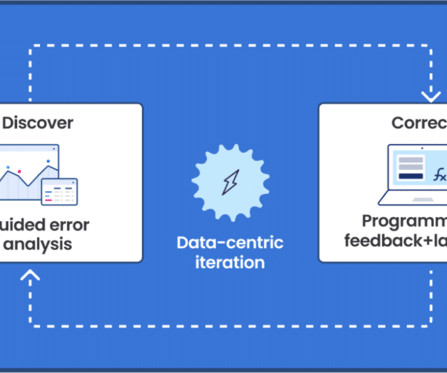
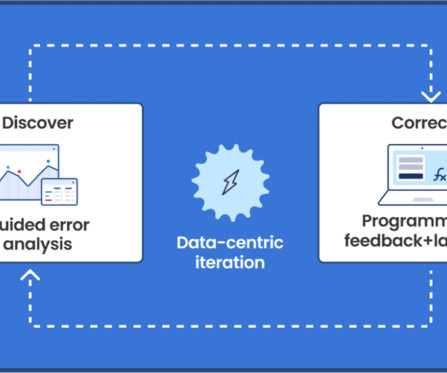
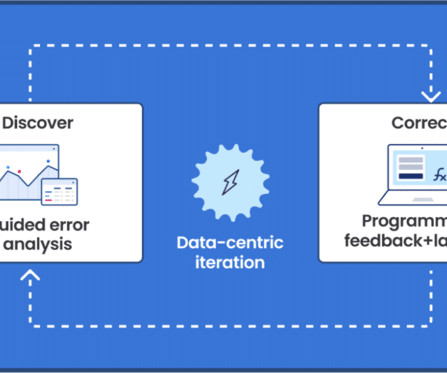
Developments like these over the past few weeks are really changing how top-tier AIdevelopment happens. Let us look at how Allen AI built this model: Stage 1: Strategic Data Selection The team knew that model quality starts with dataquality.
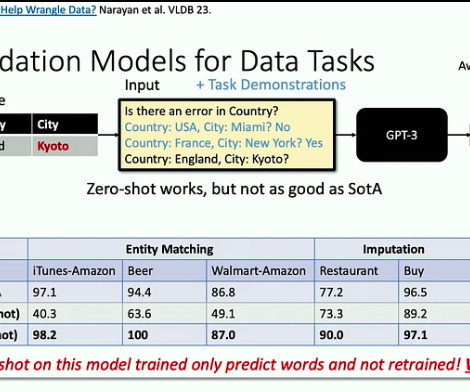
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
However, one thing is becoming increasingly clear: advanced models like DeepSeek are accelerating AI adoption across industries, unlocking previously unapproachable use cases by reducing cost barriers and improving Return on Investment (ROI). Even the most advanced models will generate suboptimal outputs without properly contextualized input.
To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. While each tool has its strengths and weaknesses, they all play a crucial role in ensuring the reliability and trustworthiness of AI as it continues to evolve 1. This helps developers to understand and fix the root cause.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Prompt engineering that explicitly tells the model how to behave.
Good morning, AI enthusiasts! As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. Learn AI Together Community section!
Amidst Artificial Intelligence (AI) developments, the domain of software development is undergoing a significant transformation. Traditionally, developers have relied on platforms like Stack Overflow to find solutions to coding challenges. Finally, ethical considerations are also integral to future strategies.
Companies still often accept the risk of using internal data when exploring large language models (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AIdevelopment cycle, data ingestion serves as the entry point.
The integration between the Snorkel Flow AIdatadevelopment platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Here’s what that looks like in practice.
Engineers need to build and orchestrate the data pipelines, juggle the different processing needs for each data source, manage the compute infrastructure, build reliable serving infrastructure for inference, and more. Together, Tecton and SageMaker abstract away the engineering needed for production, real-time AI applications.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Prompt engineering that explicitly tells the model how to behave.
Addressing this challenge requires a solution that is scalable, versatile, and accessible to a wide range of users, from individual researchers to large teams working on the state-of-the-art side of AIdevelopment. Existing research emphasizes the significance of distributed processing and dataquality control for enhancing LLMs.
That said, Ive noticed a growing disconnect between cutting-edge AIdevelopment and the realities of AI application developers. AI agents, on the other hand, hold a lot of promise but are still constrained by the reliability of LLM reasoning. AI Revolution is Losing Steam? Take, for example, the U.S.
There are major growth opportunities in both the model builders and companies looking to adopt generative AI into their products and operations. We feel we are just at the beginning of the largest AI wave. Dataquality plays a crucial role in AI model development.
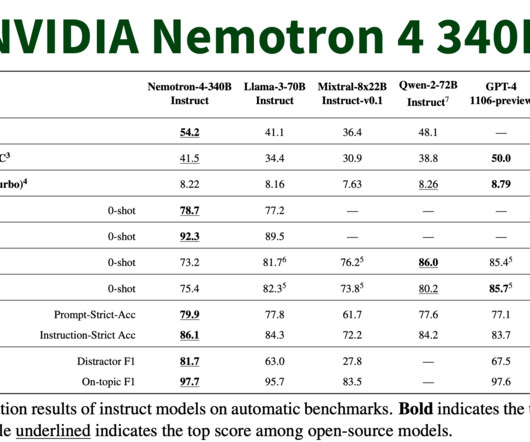
NVIDIA has recently unveiled the Nemotron-4 340B , a groundbreaking family of models designed to generate synthetic data for training large language models (LLMs) across various commercial applications. They are optimized for inference using the NVIDIA TensorRT-LLM library, enhancing their efficiency and scalability.
As we have discussed, there have been some signs of open-source AI (and AI startups) struggling to compete with the largest LLMs at closed-source AI companies. This is driven by the need to eventually monetize to fund the increasingly huge LLM training costs. This would be its 5th generation AI training cluster.
Google emphasizes its commitment to responsible AIdevelopment, highlighting safety and security as key priorities in building these agentic experiences. Command R7B: Command R7B, developed by Cohere, is the smallest model in their R series, focusing on speed, efficiency, and quality for building AI applications. .
The integration between the Snorkel Flow AIdatadevelopment platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Heres what that looks like in practice.
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AIdevelopment.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in natural language processing. Key Takeaways The Pile dataset is an 800GB open-source resource designed for AI research and LLM training. Who Created the Pile Dataset and Why?
Prompt chaining – Generative AIdevelopers often use prompt chaining techniques to break complex tasks into subtasks before sending them to an LLM. A centralized service that exposes APIs for common prompt-chaining architectures to your tenants can accelerate development.
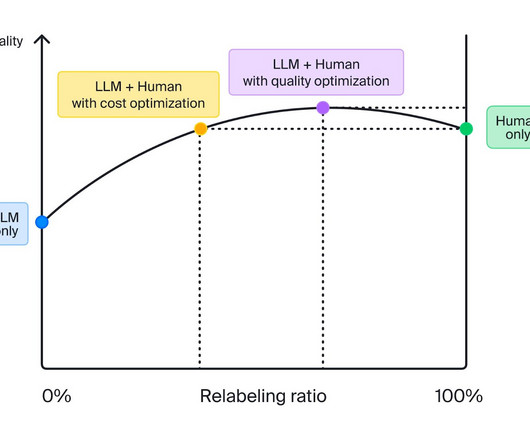
What’s more, these models aren’t always cheaper than data labeling with human annotators. But we’ve found that it is possible to elevate dataquality by using an optimal mix of human and LLM labeling. To get a clear picture of LLM performance, we need to compare output on real-world projects as well.
Snorkel offers a full suite of third-party data connectors, making data stored in popular cloud repositories like Databricks quickly and easily accessible for data-centric AIdevelopment with Snorkel Flow. Register for the next Enterprise LLM Virtual Summit! During this free 3-hour virtual summit on Jan.
Below you’ll find a selection of AI slide decks from Europe’s hands-on deep dives, immersive talks, and more! Unlocking Unstructured Data: Bridging Social (Survey) Sciences and NLP/LLM Research Through Open Science Prof. billion customer interactions.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
We’re excited to announce this new connector in conjunction with our upcoming The Future of Data-Centric AI virtual event. On June 7, the first day of the conference, Databricks Chief Technologist and Co-founder Matei Zaharia will discuss “Making LLM Applications Production Grade” at 1:30 PM PDT.
We’re excited to announce this new connector in conjunction with our upcoming The Future of Data-Centric AI virtual event. On June 7, the first day of the conference, Databricks Chief Technologist and Co-founder Matei Zaharia will discuss “Making LLM Applications Production Grade” at 1:30 PM PDT.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Financial Transformers , or “FinFormers,” can learn context and understand the meaning of unstructured financial data. They can power Q&A chatbots, summarize and translate financial texts, provide early warning signs of counterparty risk, quickly retrieve data and identify data-quality issues.
Open Data Science AI News Blog Recap DOD Urged to Accelerate AI Adoption Amid Rising Global Threats ( Source ) Anthropic Eyes $40 Billion Valuation in New Funding Round ( Source ) Meta to Launch AI Celebrity Voices from Judi Dench, John Cena, and Other Celebrities ( Source ) Celebrities Fall Victim to ‘Goodbye Meta AI’ Hoax as Fake Privacy Message (..)
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment. See what Snorkel option is right for you.
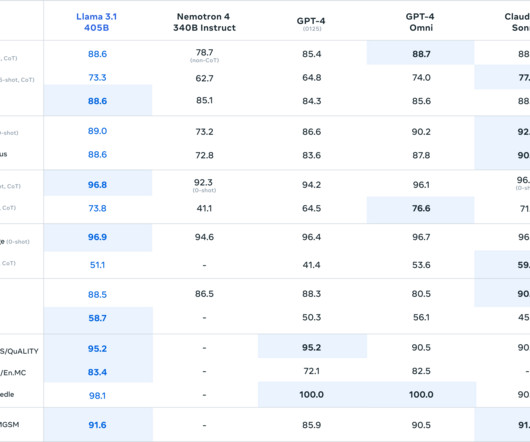
model size and data volume are significantly different as well as various strategies for data sampling. Articles Meta has announced the release of Llama 3.1 , latest and most capable open-source large language model (LLM) collection to date. Today, we had a special issue with Llama3.1
Presenters from various spheres of AI research shared their latest achievements, offering a window into cutting-edge AIdevelopments. In this article, we delve into these talks, extracting and discussing the key takeaways and learnings, which are essential for understanding the current and future landscapes of AI innovation.
While each of them offers exciting perspectives for research, a real-life product needs to combine the data, the model, and the human-machine interaction into a coherent system. AIdevelopment is a highly collaborative enterprise. From this data, your model will learn about the structure, flow, and style of successful articles.
Many customers are looking for guidance on how to manage security, privacy, and compliance as they develop generative AI applications. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
However, the world of LLMs isn't simply a plug-and-play paradise; there are challenges in usability, safety, and computational demands. In this article, we will dive deep into the capabilities of Llama 2 , while providing a detailed walkthrough for setting up this high-performing LLM via Hugging Face and T4 GPUs on Google Colab.
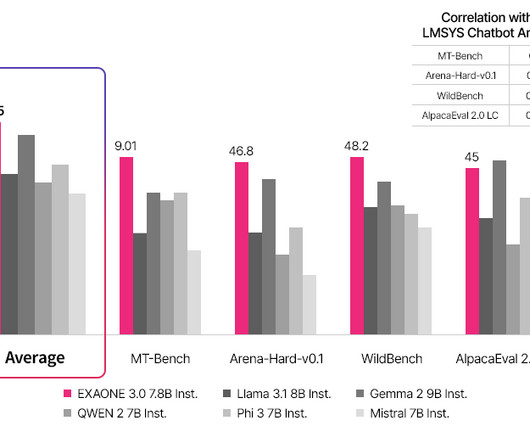
Training the Model: A Focus on Quality and Compliance The training of EXAONE 3.0 This dataset was carefully curated to include web-crawled data, publicly available resources, and internally constructed corpora. s Outstanding Performance on Rigorous English and Korean Benchmarks and Standing on the Open LLM Leaderboard 2 EXAONE 3.0
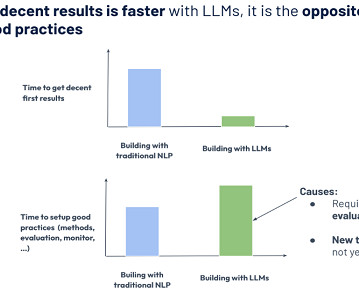
AIDevelopment Lifecycle: Learnings of What Changed with LLMs Noé Achache | Engineering Manager & Generative AI Lead | Sicara Using LLMs to build models and pipelines has made it incredibly easy to build proof of concepts, but much more challenging to evaluate the models. billion customer interactions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content