

Unlock the Power of BERT-based Models for Advanced Text Classification in Python
John Snow Labs
JUNE 6, 2023
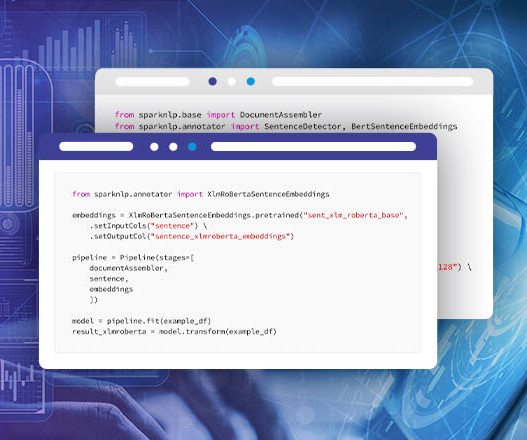
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.

















Let's personalize your content