This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks. This article was published as a part of the Data Science Blogathon.
Source: Canva Introduction In 2018, GoogleAI researchers released the BERT model. It was a fantastic work that brought a revolution in the NLP domain. This article was published as a part of the Data Science Blogathon. However, the BERT model did have some drawbacks i.e. it was bulky and hence a little slow. To navigate […].
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machine learning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications.
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. This article was published as a part of the Data Science Blogathon.
However, in 2018, the “Universal Language Model Fine-tuning for Text Classification” paper changed the entire landscape of Natural Language Processing (NLP). Introduction Welcome to the world of Large Language Models (LLM). In the old days, transfer learning was a concept mostly used in deep learning.
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
Over the past year I have on several occasions encouraged NLP researchers to do systematic reviews of the research literature. I In AI and NLP, most literature surveys are like “previous work” sections in papers. The I describe the concept below, I think it is a very useful tool in many contexts!
Natural language processing (NLP) has experienced significant growth, largely due to the recent surge in the size and strength of large language models. The impact of IA research on the design and construction of new NLP models is minimal since it frequently fails to provide practical insights, particularly regarding how to enhance models.
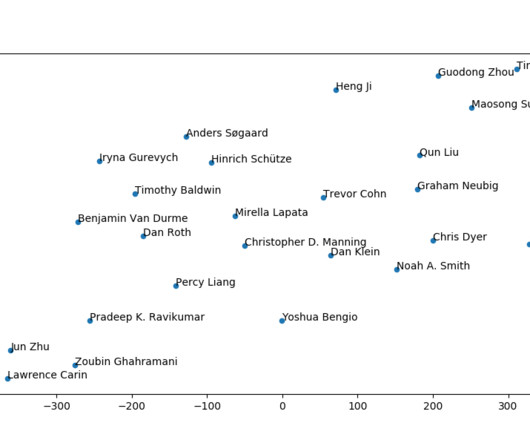
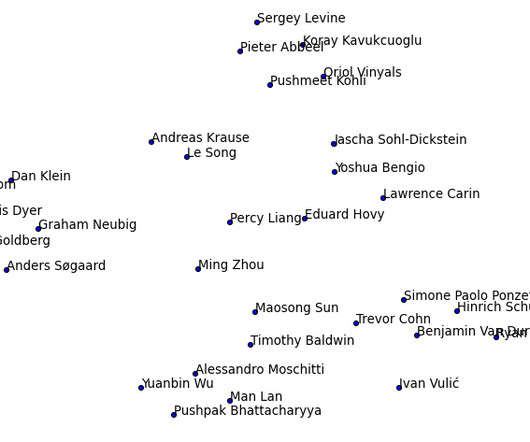
Venues We start off by looking at the publications at all the conferences between 2012-2018. Authors Next up, we can look at individual authors who have published most papers in these conferences during 2018. Looking at the total number of publications between 2012-2018, Chris Dyer (DeepMind) is still at the top with 97.
I’ve seen all kinds of people make comments recently about the value of academic research in NLP. The basic argument is that significant research on large language models such as chatGPT, which is the hottest/trendiest area in NLP, happens in companies (instead of universities) because it requires lots of resources.
Photo by Will Truettner on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 Transformer is the most critical alogrithm… github.com NLP & Audio Pretrained Models A nice collection of pretrained model libraries found on GitHub. These 2 repos encompass NLP and Speech modeling.
AI uses natural language processing (NLP) to analyse sentiments from social media, news articles, and other textual data. For instance, during the 2018 FIFA World Cup, an AI model analysed over 10 million tweets to gauge public sentiment and accurately predicted the outcomes of 70% of the matches.
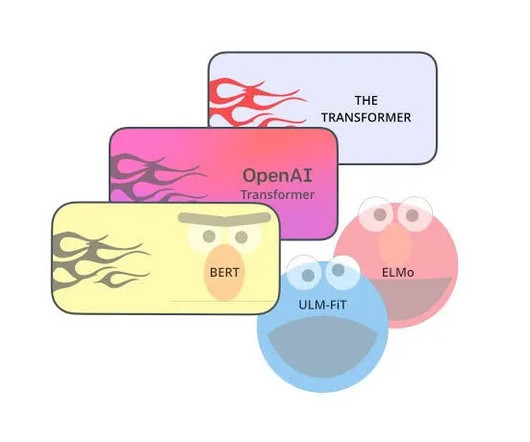
In this article, we aim to focus on the development of one of the most powerful generative NLP tools, OpenAI’s GPT. Evolution of NLP domain after Transformers Before we start, let's take a look at the timeline of the works which brought great advancement in the NLP domain. Let’s see it step by step. In 2015, Andrew M.
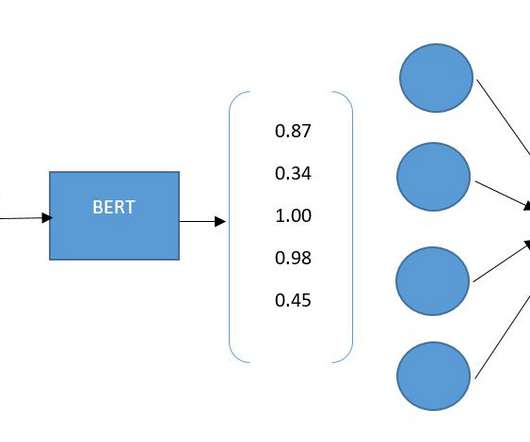
Since its introduction in 2018, BERT has transformed Natural Language Processing. It performs well in tasks like sentiment analysis, question answering, and language inference. Using bidirectional training and transformer-based self-attention, BERT introduced a new way to understand relationships between words in text.
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. dollars apiece. This study by Bui et al.
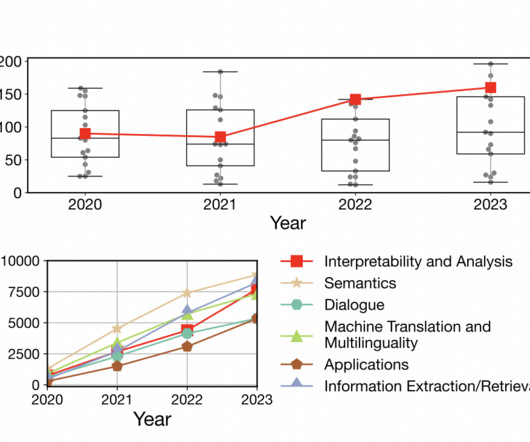
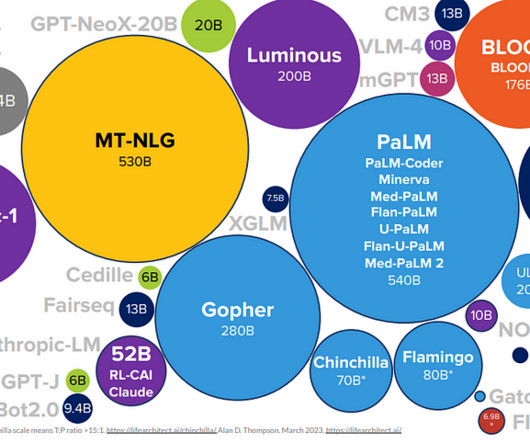
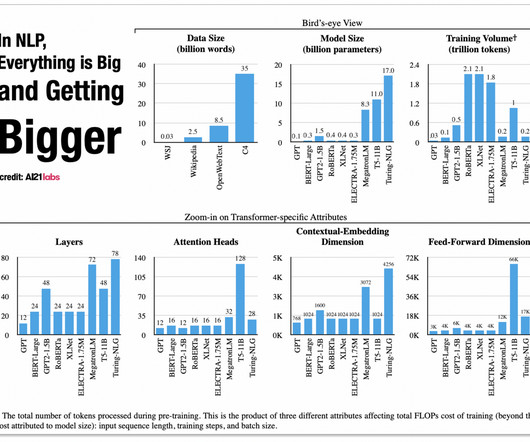
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Natural language processing (NLP) research predominantly focuses on developing methods that work well for English despite the many positive benefits of working on other languages. 2018 )—and keyboard support is even rarer for languages without a widespread written tradition ( Paterson, 2015 ). Each feature has 5.93
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
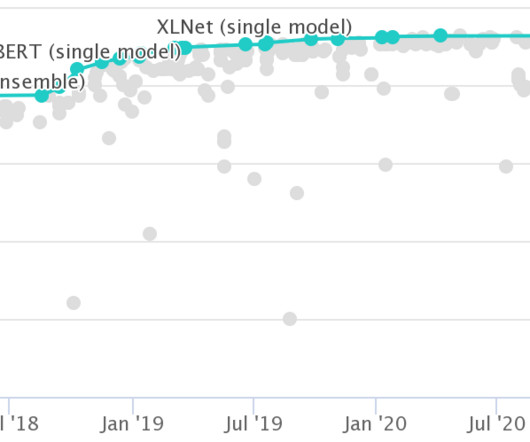
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
It has been a very productive year for NLP and ML research. NAACL and COLING were notably missing from 2017, but we can look forward to both of them in 2018. Ravikumar (CMU) are publishing mainly in the general ML venues, while the others are balanced between NLP and ML. Smith (Washington). That’s it for 2017.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. This allows the model to learn long-range dependencies between words, which is essential for many NLP tasks, such as machine translation and text summarization.
Picture created with Dall-E-2 Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, three computer scientists and artificial intelligence (AI) researchers, were jointly awarded the 2018 Turing Prize for their contributions to deep learning, a subfield of AI. Join thousands of data leaders on the AI newsletter.
In the past years, the tech world has seen a surge of NLP applications in various areas including adtech, publishing, customer service and market intelligence. To put it simply – NLP is wildly adopted with wildly variable success (let’s assume a working definition of success in terms of quality and ROI).
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). 2018 ; Howard et al., 2020 saw the development of ever larger language and dialogue models such as Meena ( Adiwardana et al.,
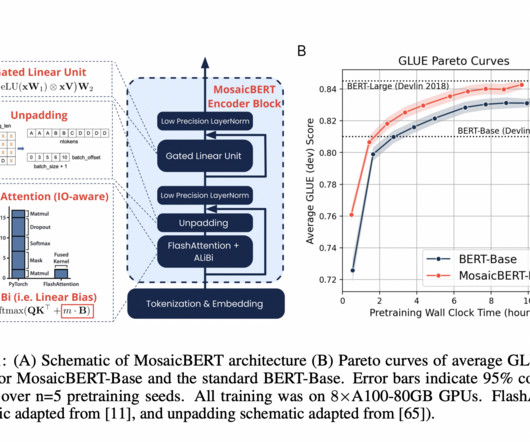
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
The Generative Pre-trained Transformer (GPT) series, developed by OpenAI, has revolutionized the field of NLP with its groundbreaking advancements in language generation and understanding. GPT-1: The Beginning Launched in June 2018, GPT-1 marked the inception of the GPT series. Model Size: 1.5
NLP research has undergone a paradigm shift over the last year. In contrast, NLP researchers today are faced with a constraint that is much harder to overcome: compute. A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models Li et al. Defining a New NLP Playground Saphra et al.
This post was first published in NLP News. NLP research has undergone a paradigm shift over the last year. In contrast, NLP researchers today are faced with a constraint that is much harder to overcome: compute. A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models Li et al.
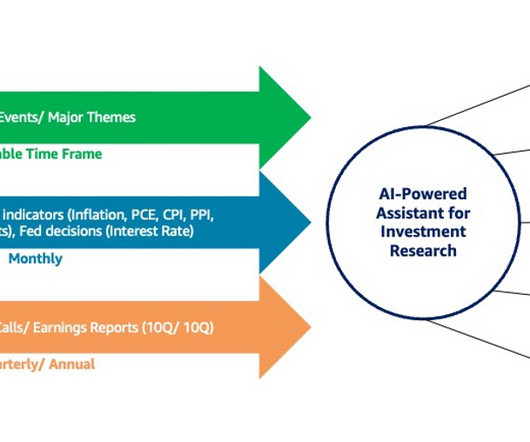
For unstructured data, the agent uses AWS Lambda functions with AI services such as Amazon Textract for document analysis, Amazon Transcribe for speech recognition, Amazon Comprehend for NLP, and Amazon Kendra for intelligent search. Can you build an optimized portfolio using these three stocks? ” WWW: $85.91 DDD: $9.82 WWW: $85.91
Let's create an advanced prompt where ChatGPT is tasked with summarizing key takeaways from AI and NLP research papers. Using the few-shot learning approach, let's teach ChatGPT to summarize key findings from AI and NLP research papers: 1. This demonstrates a classic case of ‘knowledge conflict'.
ArXiv 2018. EMNLP 2018. NAACL 2018. NAACL 2018. At the end, I also include the summaries for my own published papers since the last iteration (papers 61-74). Here we go. Improving Language Understanding by Generative Pre-Training Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. Microsoft, Edinburgh.
But now, a computer can be taught to comprehend and process human language through Natural Language Processing (NLP), which was implemented, to make computers capable of understanding spoken and written language. This allows RoBERTa to better adapt to specific NLP tasks during fine-tuning.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. Deep contextualized word representations This paper was released by Allen-AI in the year 2018. Last Updated on July 29, 2023 by Editorial Team Author(s): Abhijit Roy Originally published on Towards AI.
Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. The introduction of attention mechanisms has notably altered our approach to working with deep learning algorithms, leading to a revolution in the realms of computer vision and natural language processing (NLP).
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019) find winning ticket initialisations also for LSTMs and Transformers in NLP and RL models. 2019 ) and other variants.
There is very little contention that large language models have evolved very rapidly since 2018. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. This facilitates various NLP tasks by providing meaningful word embeddings.
Enter Natural Language Processing (NLP) and its transformational power. This is the promise of NLP: to transform the way we approach legal discovery. The seemingly impossible chore of sorting through mountains of legal documents can be accomplished with astonishing efficiency and precision using NLP.
BERT origins and basics Researchers released Google BERT in October 2018, not long after the seminal Attention is All You Need paper (which introduced the transformer building block for large language models.) BERT excels at understanding the relationships between words and can be used for various NLP tasks. Book a demo today.
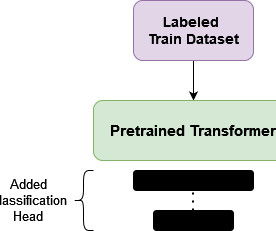
Introduction The idea behind using fine-tuning in Natural Language Processing (NLP) was borrowed from Computer Vision (CV). Despite the popularity and success of transfer learning in CV, for many years it wasnt clear what the analogous pretraining process was for NLP. How is Fine-tuning Different from Pretraining?
In the 1980s and 1990s, the field of natural language processing (NLP) began to emerge as a distinct area of research within AI. NLP researchers focused on developing statistical models that could process and generate text based on patterns and probabilities, rather than strict rules. I think GPT-3 is as intelligent as a human.
Over the last years, models in NLP have become much more powerful, driven by advances in transfer learning. This post aims to give an overview of challenges and opportunities in benchmarking in NLP, together with some general recommendations. Does this mean that we have solved natural language processing? Far from it.
BERT origins and basics Researchers released Google BERT in October 2018, not long after the seminal Attention is All You Need paper (which introduced the transformer building block for large language models.) The post BERT models: Google’s NLP for the enterprise appeared first on Snorkel AI. Book a demo today.
For unstructured data, the agent uses AWS Lambda functions with AI services such as Amazon Comprehend for natural language processing (NLP). Prompt the agent to build an optimal portfolio using the collected data What are the closing prices of stocks AAAA, WWW, DDD in year 2018? per share, investing $1,419.20
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content