This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Welcome into the world of Transformers, the deep learning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
Back in 2017, my firm launched an AI Center of Excellence. GUEST: AI has evolved at an astonishing pace. What seemed like science fiction just a few years ago is now an undeniable reality.
A team at Google Brain developed Transformers in 2017, and they are now replacing RNN models like long short-term memory(LSTM) as the model of choice for NLP […]. Introduction Transformers were one of the game-changer advancements in Natural language processing in the last decade.
Introduction In the rapidly evolving landscape of artificial intelligence, especially in NLP, large language models (LLMs) have swiftly transformed interactions with technology. Since the groundbreaking ‘Attention is all you need’ paper in 2017, the Transformer architecture, notably exemplified by ChatGPT, has become pivotal.
Introduction Embark on a journey through the evolution of artificial intelligence and the astounding strides made in Natural Language Processing (NLP). The seismic impact of finetuning large language models has utterly transformed NLP, revolutionizing our technological interactions. In a mere blink, AI has surged, shaping our world.
Over the past year I have on several occasions encouraged NLP researchers to do systematic reviews of the research literature. I In AI and NLP, most literature surveys are like “previous work” sections in papers. The I describe the concept below, I think it is a very useful tool in many contexts!
It has been a very productive year for NLP and ML research. Venues First, let’s look at different publication venues between 2012-2017. Most other venues are also growing rapidly, with 2017 being the biggest year ever for ICML, ICLR, EMNLP, EACL and CoNLL. Smith (Washington).
Natural Language Processing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. As NLP continues to advance, there is a growing need for skilled professionals to develop innovative solutions for various applications, such as chatbots, sentiment analysis, and machine translation.
Photo by Will Truettner on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 The last known comms from 3301 came in April 2017 via Pastebin post. These 2 repos encompass NLP and Speech modeling. Primus The Liber Primus is unsolved to this day.
The Ninth Wave (1850) Ivan Aivazovsky NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 09.13.20 declassified Blast from the past: Check out this old (2017) blog post from Google introducing transformer models. Aere Perrenius Welcome back. Hope you enjoyed your week! Data conversion and encoding.
Over the past decade, advancements in machine learning, Natural Language Processing (NLP), and neural networks have transformed the field. In 2017, Apple introduced Core ML , a machine learning framework that allowed developers to integrate AI capabilities into their apps. Notable acquisitions include companies like Xnor.a
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture. appeared first on MarkTechPost.
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. That’s great news for researchers who often work on SLRs because the traditional process is mind-numbingly slow: An analysis from 2017 found that SLRs take, on average, 67 weeks to produce.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
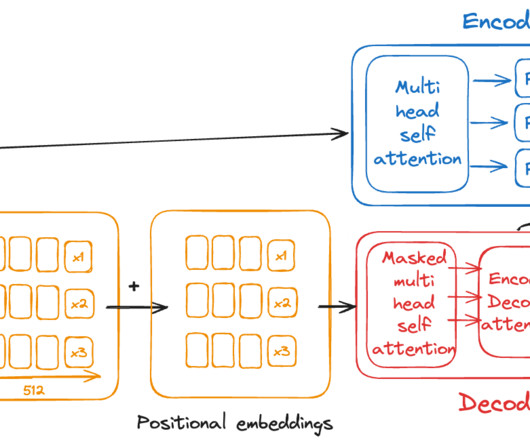
Early foundations of NLP were established by statistical and rule-based models like the Bag of Words (BoW). In this article, we will discuss what BoW is and how Transformers revolutionized the field of NLP over time. It is one of the widely used technique in NLP despite its simplicity. Transformer Architecture (Vaswani et al.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
spaCy In 2017 spaCy grew into one of the most popular open-source libraries for Artificial Intelligence. In April 2017, we published a follow up that described the solution we were working on, and in August we introduced Prodigy , and started accepting beta users. spaCy’s Machine Learning library for NLP in Python.
BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers. This model marked a new era in NLP with pre-training of language models becoming a new standard. What is the goal? accuracy on SQuAD 1.1
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
By 2017, deep learning began to make waves, driven by breakthroughs in neural networks and the release of frameworks like TensorFlow. Researchers and practitioners explored complex architectures, from transformers to reinforcement learning , leading to a surge in sessions on natural language processing (NLP) and computervision.
Natural language processing (NLP) research predominantly focuses on developing methods that work well for English despite the many positive benefits of working on other languages. Most of the world's languages are spoken in Asia, Africa, the Pacific region and the Americas. Each feature has 5.93 categories on average.
Exploring the encoder-decoder magic in NLP behind LLMsImage created by the author. The state-of-the-art Natural Language Processing (NLP) models used to be Recurrent Neural Networks (RNN) among others. And then came Transformers. Transformer architecture significantly improved natural language task performance compared to earlier RNNs.
unsplash Attention-based transformers have revolutionized the AI industry since 2017. Now it’s possible to have deep learning models with no limitation for the input size.
My second company was an alternative asset management company I co-founded in 2017 prior to the ICO-wave in crypto. This was my first exposure to NLP where we used sentiment analysis of social media data as an investment strategy. At the same time, I also learned a lot about myself and about what I wanted to work in.
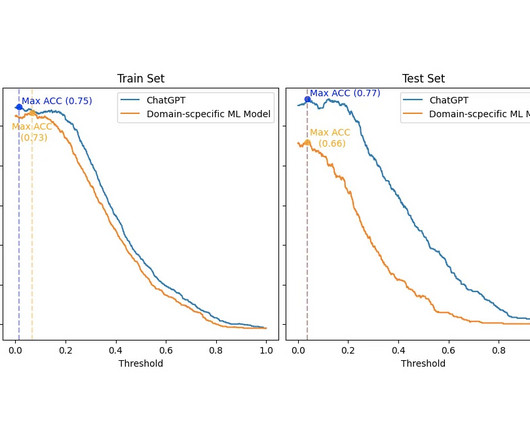
SA is a very widespread Natural Language Processing (NLP). Hence, whether general domain ML models can be as capable as domain-specific models is still an open research question in NLP. It has several applications and thus can be used in several domains (e.g., finance, entertainment, psychology).
Large language models (LLMs) have seen remarkable success in natural language processing (NLP). Moreover, other methods have been explored for utilizing pre-trained language models in NLP tasks, contributing to the ongoing advancements in the field. However, they pose major challenges in computational resources and memory usage.
Photo by Johannes Plenio on Unsplash Since the 2017 paper “Attention Is All You Need” invented the Transformer architecture, natural language processing (NLP) has seen tremendous growth. Leon Eversberg Originally published on Towards AI. LLMs are evolving at a rapid speed.
The Generative Pre-trained Transformer (GPT) series, developed by OpenAI, has revolutionized the field of NLP with its groundbreaking advancements in language generation and understanding. in 2017 , which relies on self-attention mechanisms to process input data in parallel, enhancing computational efficiency and scalability.
The Normalizer annotator in Spark NLP performs text normalization on data. The Normalizer annotator in Spark NLP is often used as part of a preprocessing step in NLP pipelines to improve the accuracy and quality of downstream analyses and models. These transformations can be configured by the user to meet their specific needs.
Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text.
Rule-based sentiment analysis in Natural Language Processing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.
Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data. Stopwords are commonly occurring words (like the, a, and, in , etc.)
AI Categories in CRE Colliers has identified six primary categories of AI that are currently being utilized or expected to be adopted soon: Natural Language Processing (NLP) – Understands, generates, and interacts with human language. According to the data: 33% plan to implement AI within the next two years. billion 2023 : $29.1
PwC 👉Industry domain: AI, Professional services, Business intelligence, Consulting, Cybersecurity, Generative AI 👉Location: 73 offices 👉Year founded: 1998 👉Programming Languages Deployed: Java, Google Cloud, Microsoft SQL, jQuery, Pandas, R, Oracle 👉Benefits: Hybrid workspace, Child care and parental leave, flexible (..)
Word embeddings are considered as a type of representation used in natural language processing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in natural language processing (NLP) as a technique to represent words in a numerical format.
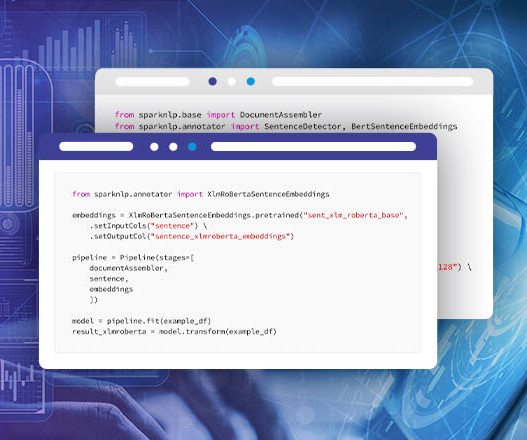
Sentence embeddings with Transformers are a powerful natural language processing (NLP) technique that use deep learning models known as Transformers to encode sentences into fixed-length vectors that can be used for a variety of NLP tasks. Introduction to Spark NLP Spark NLP is an open-source library maintained by John Snow Labs.
#ML — Jason Eisner (@adveisner) August 12, 2017 E.g., regularize toward word embeddings θ that were pretrained on big data for some other objective. — Jason Eisner (@adveisner) August 12, 2017 I have this in the book btw (p. Coeff controls bias/variance tradeoff.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). This is less of a problem in NLP where unsupervised pre-training involves classification over thousands of word types.
So, In 2017, we took our national intelligence agency experience and began to make this happen with the mission of helping organizations prevent breaches, by continuously mapping their external exposure blind spots and finding the paths of least resistance into their internal networks.
The Ninth Wave (1850) Ivan Aivazovsky NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 09.13.20 link] Blast from the past: Check out this old (2017) blog post from Google introducing transformer models. Wild to see how much progress that’s been made in the field of NLP in the last couple of years. ?
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019) find winning ticket initialisations also for LSTMs and Transformers in NLP and RL models. 2019 ) and other variants.
Over the last years, models in NLP have become much more powerful, driven by advances in transfer learning. This post aims to give an overview of challenges and opportunities in benchmarking in NLP, together with some general recommendations. Does this mean that we have solved natural language processing? Far from it.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content