This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Analysts and thought leaders almost universally urge the importance of the CEO being actively involved in data initiatives. But what gets buried in the small print is the acknowledgement that many data projects never make it to production. In 2016, Gartner assessed it at only 15%. It’s all data driven,” Faruqui explains.
Many consider a NoSQL database essential for high dataingestion rates. In 2016, Db2 for z/OS moved to a continuous delivery model that provides new capabilities and enhancements through the service stream in just weeks (and sometimes days) instead of multi-year release cycles.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
TensorFlow Extended (TFX): End-to-End Pipeline: Providing a variety of tools and libraries for production-ready machine learning pipelines, TFX takes care of the entire lifecycle from dataingestion and validation to model training, evaluation, and deployment. So, let’s take a look at PyTorch.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any data science task then you definitely used pandas. So, pandas is a library which helps with performing dataingestion and transformations. apply(lambda x: x.year) df.groupby('year')['Sales'].mean() Yearly average sales.
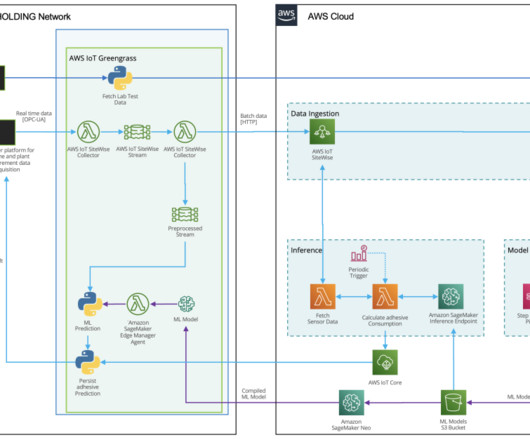
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. Since 2016 he mentored hundreds of entrepreneurs at startup incubation programs pro-bono.
In 2010, WorldQuant was producing several thousand alphas per year, by 2016 had one million alphas, by 2022, had multiple millions, with a stated ambition to get to 100 million alphas. The automated process of dataingestion, processing, packaging, combination, and prediction is referred to by WorldQuant as their “alpha factory.”
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content