This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Up until now, object detection in images using computervision models faced a major roadblock of a few seconds of lag due to processing time. However, the YOLOv8 computervision model's release by Ultralytics has broken through the processing delay. What Makes YOLOv8 Standout?
Introduction Deep learning has revolutionized computervision and paved the way for numerous breakthroughs in the last few years. One of the key breakthroughs in deep learning is the ResNet architecture, introduced in 2015 by Microsoft Research.
Introduction Semantic segmentation, categorizing images pixel-by-pixel into specified groups, is a crucial problem in computervision. Fully Convolutional Networks (FCNs) were first introduced in a seminal publication by Trevor Darrell, Evan Shelhamer, and Jonathan Long in 2015.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
To learn about ComputerVision and Deep Learning for Education, just keep reading. ComputerVision and Deep Learning for Education Benefits Smart Content Artificial Intelligence can help teachers and research experts create innovative and personalized content for their students. Or requires a degree in computer science?
Roadzen has pioneered computervision research, generative AI and telematics including tools and products for road safety, underwriting and claims. How does Roadzen use computervision to assess the value of a vehicle? How does Roadzen use computervision to assess the value of a vehicle?
In recent years, advances in computervision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it. In this blog post we discussed using computervision on satellite imagery.
These include computervision and sound recognition systems that help automate curation and editing of exciting moments in sports; systems that extract summaries or factoids from vast amounts of structured and unstructured natural language data; and systems that forecast and predict player performance and winners.
Computervision models enable the machine to extract, analyze, and recognize useful information from a set of images. Lightweight computervision models allow the users to deploy them on mobile and edge devices. About us: Viso Suite allows enterprise teams to realize value with computervision in only 3 days.
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutional neural networks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
In computervision, there is an area called domain adaptation or style transfer which generates a new image by mixing up specific attributes from different images. Neural Style Transfer (NST) was born in 2015 [2], slightly later than GAN. One may associate these applications with the trending generative models.
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
Khudanpur, "Librispeech: An ASR corpus based on public domain audio books," 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 2015, pp. " Proceedings of the IEEE/CVF conference on computervision and pattern recognition. 2015.7178964. [3]
Allen School of Computer Science & Engineering at University of Washington, Farhadi’s research impact has been globally recognized with several best paper awards at CVPR, NeruIPS, AAAI, NSF Career Award, and the Sloan Fellowship.
Container runtimes are consistent, meaning they would work precisely the same whether you’re on a Dell laptop with an AMD CPU, a top-notch MacBook Pro , or an old Intel Lenovo ThinkPad from 2015. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? That’s not the case.
2015 ), SSD ( Fei-Fei et al., 2015 ; Redmon and Farhad, 2016 ), and others. 2013) submitted the original R-CNN publication to arXiv, Girkshick (2015) published a second paper, Fast R-CNN. Image credit: Figure 1 of Girshick (2015) ). 2004 ), You Only Look Once (YOLO) ( Redmon et al., In this work, Girshick et al.
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Therefore, Now we conquer this problem of detecting the cracks using image processing methods, deep learning algorithms, and ComputerVision.
ComputerVision Datasets Object Detection What Is Object Detection Object detection is a cool technique that allows computers to see and understand what’s in an image or a video. The world relies increasingly on fish protein, so you might want to check out this fish dataset and explore the world of underwater computervision.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
The platform's computervision technology maps the captured images to the project plans, creating a fully navigable digital twin of the construction site. By leveraging computervision technology and 360-degree cameras mounted on hardhats, Buildots captures comprehensive visual data of construction sites on a daily basis.
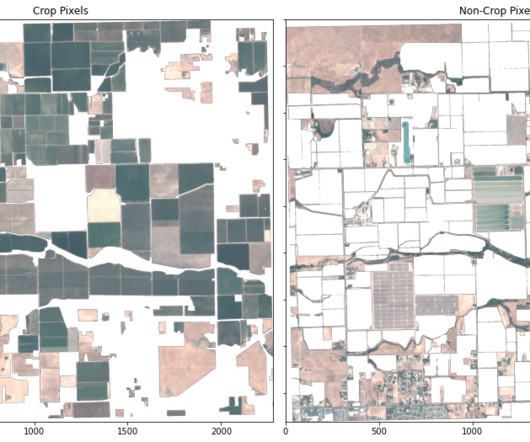
Our results reveal that the classification from the KNN model is more accurately representative of the state of the current crop field in 2017 than the ground truth classification data from 2015. However, Landsat 8 lower-resolution imagery could have been used as a bridge between 2015 and 2017.
In 2015, clinical trials demonstrated the superiority of directly removing the clot from the cerebral arteries by navigating tiny guidewires and catheters within the arterial vasculature, a procedure called mechanical thrombectomy. AI will further enhance navigation capabilities with locally embedded computervision and path planning models.
In 2015, Andrew M. People who are familiar with the world of computervision will have an idea of the concept called transfer learning, so we need to shift a bit to the computervision world to understand the importance and urge to find something equivalent.
a proposal to establish an annual International Day of Light The final report of IYL 2015 was delivered to UNESCO in Paris (IDL) as an extension of the highly successful International Year of during a special meeting in October 2016. At this event, SPIE member Light and Light-based Technologies (IYL 2015).
About us : Viso Suite is an End-to-End ComputerVision Infrastructure that provides all the tools required to train, build, deploy, and manage computervision applications at scale. To get started with enterprise-grade computervision infrastructure, book a demo of Viso Suite with our team of experts.
When it comes to terrestrial applications, the benchmark datasets that machine learning and computervision researchers swarm to are ImageNet and Microsoft COCO. In order to annotate gathered videos more extensively, they started funding professional taxonomists in 2015.
Intorduction The computervision research community relies on standardized datasets to assess the efficacy of novel models and enhancements to existing ones. Source : COCO Released by Microsoft in 2015, the MS COCO dataset is a comprehensive collection crafted for tasks such as object detection, image segmentation, and captioning.
The MBD approach has shown promising results in image segmentation tasks, where it has been found to be effective in selecting informative features and reducing the computational cost of segmentation algorithms (Xu et al., 2015; Huang et al., 2015), which consists of 20 object categories with varying levels of complexity.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
In 2015, a research paper from Stanford University and UC Berkeley introduced diffusion models, coming originally from statistical physics, into the field of machine learning. However, the quality of generated images was quite poor back in 2015, as there was still huge room for improvement. Midjourney Evolution.
However, the real breakthrough in this AI advancement, which integrated technologies such as ComputerVision, Sensor Fusion, and Deep Learning, relied significantly on about 1000 individuals in India. Global corporate investments in AI have increased sevenfold since 2015.
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. This “transfer learning” approach was so successful that it became the de-facto standard for solving a broad range of computervision problems.
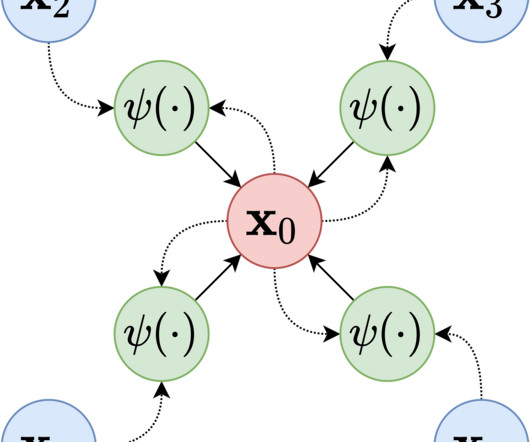
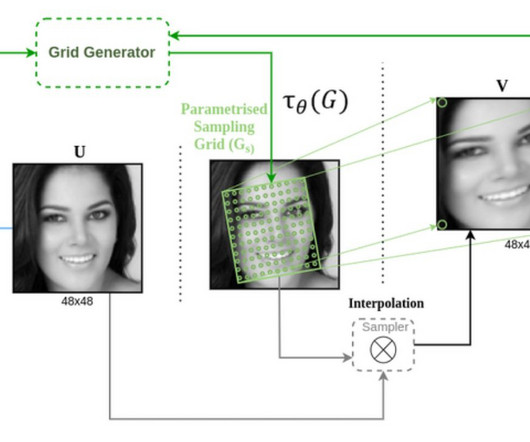
A Spatial Transformer Network (STN) is an effective method to achieve spatial invariance of a computervision system. first proposed the concept in a 2015 paper by the same name. I.e., the robustness to accurately execute computervision tasks on datasets where objects have varying presentations.
Since its inception in 2015, the YOLO (You Only Look Once) object-detection algorithm has been closely followed by tech enthusiasts, data scientists, ML engineers, and more, gaining a massive following due to its open-source nature and community contributions. Viso Suite is the end-to-end platform for no code computervision.
is a state-of-the-art vision segmentation model designed for high-performance computervision tasks, enabling advanced object detection and segmentation workflows. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). Source : Johnson et al. using Faster-RCNN[ 82 ].
This database has undoubtedly played a great impact in advancing computervision software research. It is a technique used in computervision to identify and categorize the main content (objects) in a photo or video. The other usage of image datasets is as a benchmark in computervision algorithms.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. Interestingly, “to ghost” wasn’t very common in 2015.
Object detection is one of the crucial tasks in ComputerVision (CV). Computervision researchers introduced YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015. About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
Figure 4: The Netflix personalized home page generation problem (source: Alvino and Basilico, “Learning a Personalized Homepage,” Netflix Technology Blog , 2015 ). Green ticks represent the relevant titles (source: Alvino and Basilico, “Learning a Personalized Homepage,” Netflix Technology Blog , 2015 ). That’s not the case.
This has meant that some of the most important recent technologies for computervision, such as residual connections and batch normalisation have so far had relatively little impact in the NLP community. 2015) Paragraph Vector 57.7 2015) SVM + Bigrams 57.6 2015) SVM + Unigrams 58.9 2015) CNN-word 59.7
Launched in July 2015, AliMe is an IHCI-based shopping guide and assistant for e-commerce that overhauls traditional services, and improves the online user experience. Following its successful adoption in computervision and voice recognition, DL will continue to be applied in the domain of natural language processing (NLP).
The traditional way to solve these problems is to use computervision machine learning (ML) models to classify the damage and its severity and complement with regression models that predict numerical outcomes based on input features like the make and model of the car, damage severity, damaged part, and more.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content