This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apple prioritizes computervision , natural language processing , voice recognition, and healthcare to enhance its products. Likewise, Microsoft strengthens its cloud and enterprise software through acquisitions in natural language processing , computervision , and cybersecurity.
Founded in 2014, AI2 is the research institute created by the late philanthropist Paul G. Allen School of Computer Science & Engineering at University of Washington, Farhadi’s research impact has been globally recognized with several best paper awards at CVPR, NeruIPS, AAAI, NSF Career Award, and the Sloan Fellowship.
In computervision, there is an area called domain adaptation or style transfer which generates a new image by mixing up specific attributes from different images. However, generative models is not a new term and it has come a long way since Generative Adversarial Network (GAN) was published in 2014 [1].
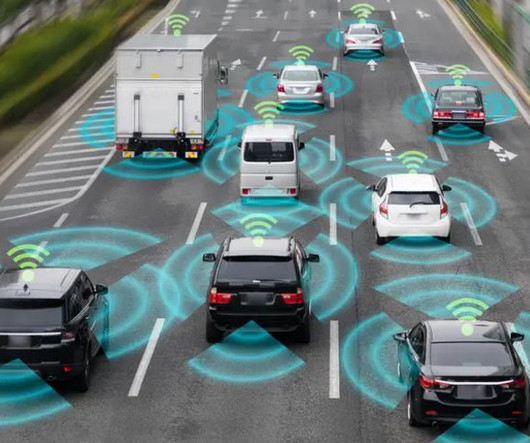
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Therefore, Now we conquer this problem of detecting the cracks using image processing methods, deep learning algorithms, and ComputerVision.
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutional neural networks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
I offer data science mentoring sessions and long-term career mentoring: Generative adversarial networks (GANs) have revolutionized image synthesis since their introduction in 2014.
ComputerVision for Cultural Heritage Preservation: Unlocking the Past with Advanced Imaging Technology Image Source: Technology Innovators Preserving our cultural legacy is critical because it allows us to remain in touch with our past, learn our roots, and appreciate humanity's rich history.
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
More posts by this contributor 4 questions to ask before building a computervision model During the past six months, we have witnessed some incredible developments in AI. These problems are why, despite the early promise and floods of investment, technologies like self-driving cars have been just one year away since 2014.
Applications in ComputerVision CNNs dominate computervision tasks such as object detection, image classification, and facial recognition. Introduced by Ian Goodfellow in 2014, GANs are designed to generate realistic data, such as images, videos, and audio, that mimic real-world datasets.
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
The original Faster R-CNN paper used VGG (Simonyan and Zisserman, 2014) and ZF (Zeiler and Fergus, 2013) as the base networks. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery.
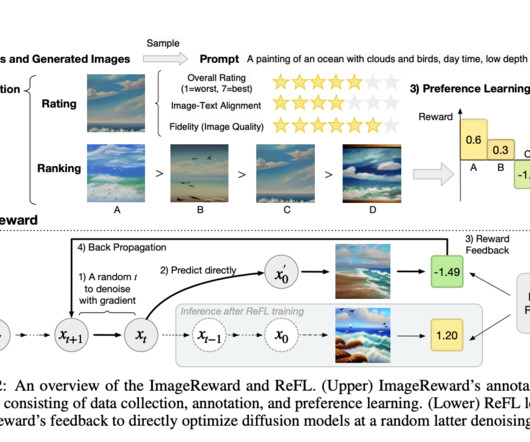
ImageReward aligns consistently with human preference ranking and exhibits superior distinguishability across models and samples compared to FID and CLIP scores on prompts from actual users and MS-COCO 2014. • For fine-tuning diffusion models concerning human preference scores, they suggest Reward Feedback Learning (ReFL).
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. billion to a projected $574.78 billion in 2017 to a projected $37.68
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
on MS-COCO 2014-30k using the same denoiser architecture as Stable Diffusion. Their one-step generator performs much better than known few-step diffusion methods on all benchmarks, including Consistency Models, Progressive Distillation, and Rectified Flow. DMD achieves FIDs of 2.62 on ImageNet, outperforming the Consistency Model by 2.4×.
It includes data from 28 climate models and 142 model runs, covering historical (1850-2014) and future scenarios (SSP2-4.5, ClimDetect is a dataset with 816,000 daily climate snapshots from the CMIP6 model ensemble, designed to enhance D&A studies of climate signals.
In recent years, the field of computervision has witnessed significant advancements in the area of image segmentation. We can also get the bounding boxes from smaller models, or in some cases, using standard computervision tools. Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC).
Deeper Insights Year Founded : 2014 HQ : London, UK Team Size : 11–50 employees Clients : Smith and Nephew, Deloitte, Breast Cancer Now, IAC, Jones Lang-Lasalle, Revival Health. Services : AI Solution Development, ML Engineering, Data Science Consulting, NLP, AI Model Development, AI Strategic Consulting, ComputerVision.
Course information: 80 total classes • 105+ hours of on-demand code walkthrough videos • Last updated: September 2023 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computervision and deep learning. Or requires a degree in computer science?
Pascal VOC is a renowned dataset and benchmark suite that has significantly contributed to the advancement of computervision research. It provides standardized image data sets for object class recognition and a common set of tools for accessing the data and evaluating the performance of computervision models.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). 2014)[ 73 ] and Donahue et al.
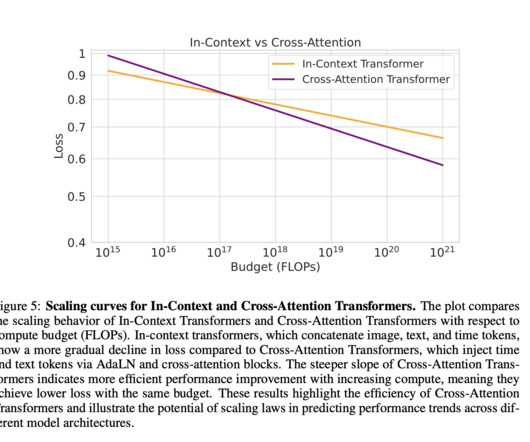
The study validates scaling laws on out-of-domain datasets using the COCO 2014 validation set. To validate these laws, they extrapolate to a 1.5e21 FLOPs budget, training a 958.3M parameter model that closely matches predicted loss.
He has 20+ years of experience with internet-related technologies, engineering and architecting solutions and joined AWS in 2014, first guiding some of the largest AWS customers on most efficient and scalable use of AWS services and later focused on AI/ML with a focus on computervision and at the moment is obsessed with extracting information from (..)
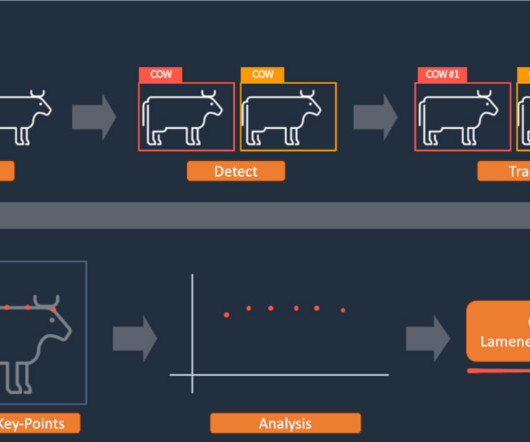
According to a 2014 study, the proportion of severely lame cows in China can be as high as 31 percent. He specializes in ComputerVision (CV) and Visual-Language Model (VLM). Tianjun Xiao is a senior applied scientist at the AWS AI Shanghai Lablet, co-leading the computervision efforts.
Next, we recommend “Interstellar” (2014), a thought-provoking and visually stunning film that delves into the mysteries of time and space. He is passionate about computervision, NLP, generative AI, and MLOps. With its groundbreaking special effects and memorable characters, this movie is a must-see for any fan of the genre.
In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. 2012; Otsu, 1979; Long et al., 2013; Goodfellow et al., IEEE transactions on pattern analysis and machine intelligence, 33(5), 898–916. Goodfellow, I.
In the following, we will explore Convolutional Neural Networks (CNNs), a key element in computervision and image processing. Viso Suite enables the use of neural networks for computervision with no code. Le propose architectures that balance accuracy and computational efficiency. Learn more and request a demo.
AlphaPose is a multi-person pose estimation model that uses computervision and deep learning techniques to detect and predict human poses from images and videos in real time. About us: Viso Suite provides full-scale features to rapidly build, deploy, and scale enterprise-grade computervision applications.
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. This “transfer learning” approach was so successful that it became the de-facto standard for solving a broad range of computervision problems.
Apart from supporting explanations for tabular data, Clarify also supports explainability for both computervision (CV) and natural language processing (NLP) using the same SHAP algorithm. It is constructed by selecting 14 non-overlapping classes from DBpedia 2014.
He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computervision. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions.
Built in 2014 along the Ankhor Canal, it’s fondly known as the “Snow Mosque” due to its pristine white marble construction. The keras and keras_cv imports are for using Keras and its computervision extensions, respectively. Here, we are using the “torch” backend. Join the Newsletter!
StyleGAN is GAN (Generative Adversarial Network), a Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. Since the development of GANs, the world saw several models introduced every year that got nearer to generating real images.
2014; Bojanowski et al., Traditionally, ComputerVision tasks use several Convolutional layers to extract significant features by iterating over the image using a fixed-sized box (kernel). Instead, why not use a set of embeddings that are already trained? Sometimes, this can be easier and much faster. So, what’s the alternative?
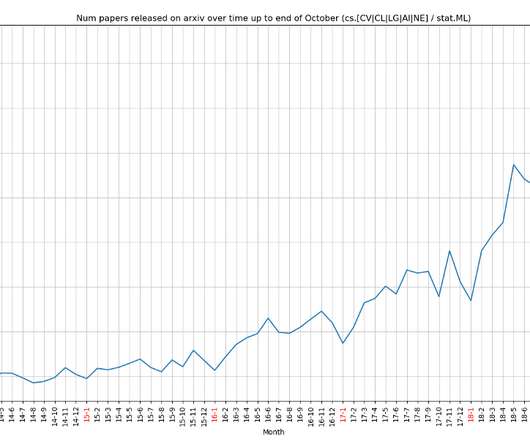
It, of course, includes the work we have done manually in our previous two survey publications: A Year in ComputerVision and Multi-Modal Methods. Crafting a dataset The number of papers added to ArXiv per month since 2014. In 2018, over 1000 papers have been released on ArXiv per month in the above areas.
GANs based Models GANs were first introduced in 2014 and have been modified for use in various applications, style transfer being one of them. Enterprise AI Viso Suite infrastructure makes it possible for enterprises to integrate state-of-the-art computervision systems into their everyday workflows.
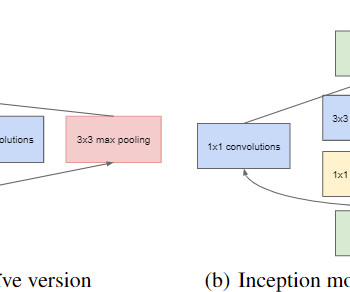
In this blog, we will try to deep dive into the concept of 1x1 convolution operation which appeared in the paper ‘Network in Network’ by Lin et al in (2013) and ‘Going Deeper with Convolutions’ by Szegedy et al (2014) that proposed the GoogLeNet architecture.
GoogLeNet: is a highly optimized CNN architecture developed by researchers at Google in 2014. This helps avoid disappearing gradients in very deep networks, allowing ResNet to attain cutting-edge performance on a wide range of computervision applications.
This article will discuss the following: Neuromorphic Engineering and its core principles History and Development Algorithms Used How Neuromorphic Algorithms differ from Traditional Algorithms Real-world examples Applications and Use Cases About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. This is a joint blog with AWS and Philips.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content