This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
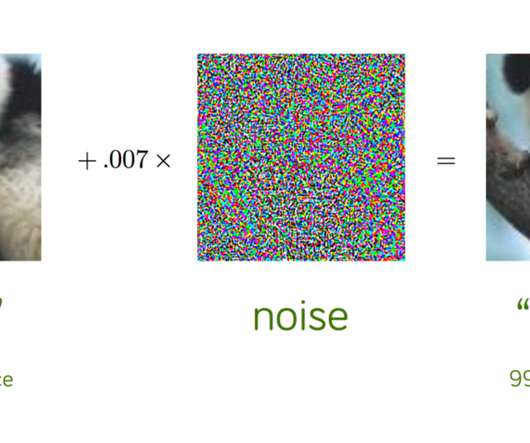
In 2014, a group of researchers at Google and NYU found that it was far too easy to fool ConvNets with an imperceivable, but carefully constructed nudge in the input. But by 2014, ConvNets had become powerful enough to start surpassing human accuracy on a number of visual recognition tasks. What are adversarial attacks? confidence.
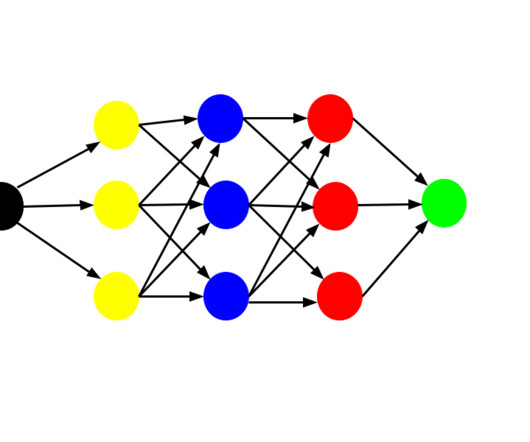
In this guide, we’ll talk about Convolutional NeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are Convolutional NeuralNetworks CNN? CNNs are artificial neuralnetworks built to handle data having a grid-like architecture, such as photos or movies.
In the following, we will explore Convolutional NeuralNetworks (CNNs), a key element in computer vision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neuralnetworks and their applications. Howard et al.
Deep learning (DL) is a subset of machine learning that uses neuralnetworks which have a structure similar to the human neural system. Include summary statistics of the data, including counts of any discrete or categorical features and the target feature. 12, 2014. [3] MIT Press, ISBN: 978–0262028189, 2014. [7]
Hence, rapid development in deep convolutional neuralnetworks (CNN) and GPU’s enhanced computing power are the main drivers behind the great advancement of computer vision based object detection. Various two-stage detectors include region convolutional neuralnetwork (RCNN), with evolutions Faster R-CNN or Mask R-CNN.
Deep learning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e. cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.” deep” architecture). These can be customized and trained.
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. Object detection is no different. 2015 ; He et al.,
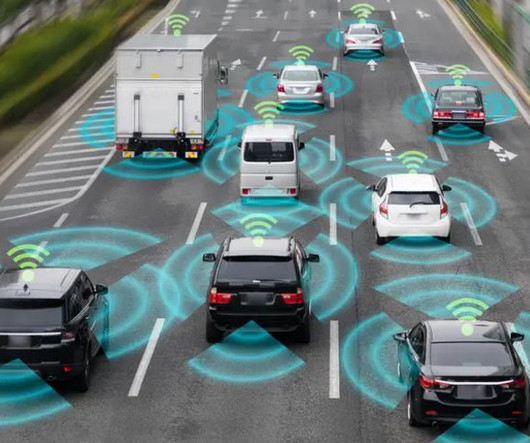
Autonomous Driving applying Semantic Segmentation in autonomous vehicles Semantic segmentation is now more accurate and efficient thanks to deep learning techniques that utilize neuralnetwork models. Levels of Automation in Vehicles – Source Here we present the development timeline of the autonomous vehicles.
State of Computer Vision Tasks in 2024 The field of computer vision today involves advanced AI algorithms and architectures, such as convolutional neuralnetworks (CNNs) and vision transformers ( ViTs ), to process, analyze, and extract relevant patterns from visual data. Get a demo here.
Introduction In natural language processing, text categorization tasks are common (NLP). Uysal and Gunal, 2014). The last Dense layer is the network’s output layer, it takes in a variable shape which can be either 4 or 3, denoting the number of classes for therapist and client. As a technical writer, every little bit helps.
Human Action Recognition (HAR) is a process of identifying and categorizing human actions from videos or image sequences. The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutional neuralnetwork architecture for image recognition tasks. It was introduced in 2014 by a group of researchers (A.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content