This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Linear categorical to categorical correlation is not supported.
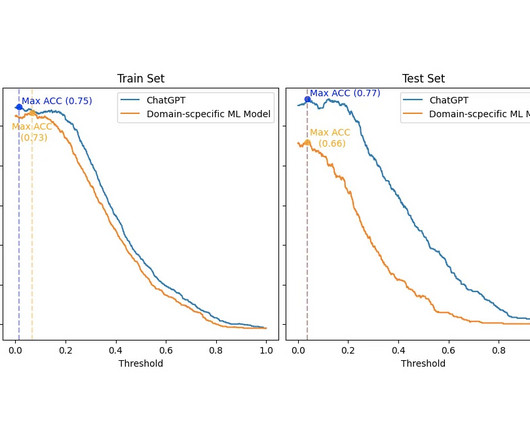
So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. This evaluation assesses how the accuracy (y-axis) changes regarding the threshold (x-axis) for categorizing the numeric Gold-Standard dataset for both models. First, I must be honest. Then, I made a confusion matrix.
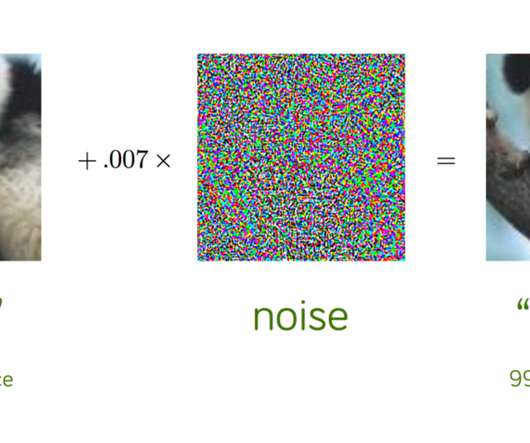
In 2014, a group of researchers at Google and NYU found that it was far too easy to fool ConvNets with an imperceivable, but carefully constructed nudge in the input. But by 2014, ConvNets had become powerful enough to start surpassing human accuracy on a number of visual recognition tasks. What are adversarial attacks? confidence.
Getting the Metrics and Loss Functions Since our model must implement two tasks — classification and regression — we need two different Loss Functions : One for the classification task: we may use any Loss Function usually found in only-classification tasks like Categorical Crossentropy. and model (only 3,235,014 parameters!)
In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text. We want to aggregate it, link it, filter it, categorize it, generate it and correct it. We all spend a big part of our working lives writing, reading, speaking and listening.
Image Classification Image classification tasks involve CV models categorizing images into user-defined classes for various applications. Based on the presence of a tiger, the entire image is categorized as such. The model secured first and second positions in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014.
AlexNet was created to categorize photos in the ImageNet dataset, which contains approximately 1 million images divided into 1,000 categories. GoogLeNet: is a highly optimized CNN architecture developed by researchers at Google in 2014. It has eight layers, five of which are convolutional and three fully linked.
VGGNet , introduced by Simonyan and Zisserman in 2014, emphasized the importance of depth in CNN architectures through its 16-19 layer CNN network. Text Processing with CNNs In text processing, CNNs are remarkably efficient, particularly in tasks like sentiment analysis, topic categorization, and language translation.
Year: More than half the cars in the data were manufactured in or after 2014. Before building a model, I have to encode categorical features. This is a clear indication that a good model is formed to explain variance in the price of used cars up to 87%. The log transformation was applied on this column to reduce skewness.
The original Faster R-CNN paper used VGG (Simonyan and Zisserman, 2014) and ZF (Zeiler and Fergus, 2013) as the base networks. All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. 2015 ; He et al., MobileNets ). Or has to involve complex mathematics and equations?
AI algorithms can help with automatic artifact recognition, categorization, and analysis, allowing more efficient research and documentation operations. References: Francesco Nex and Fabio Remondino's "Photogrammetry and Remote Sensing with Unmanned Aerial Vehicles" (2014).
Human Action Recognition (HAR) is a process of identifying and categorizing human actions from videos or image sequences. It was introduced in 2014 by a group of researchers (A. This is going to be a hands-on tutorial, so I urge you to read and code along, and I will add the link to the code at the end of the article. Zisserman and K.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content